 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoBA-RL: Capability-Oriented Budget Allocation for Reinforcement Learning in LLMs
Feb 03, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key approach for enhancing LLM reasoning.However, standard frameworks like Group Relative Policy Optimization (GRPO) typically employ a uniform rollout budget, leading to resource inefficiency. Moreover, existing adaptive methods often rely on instance-level metrics, such as task pass rates, failing to capture the model's dynamic learning state. To address these limitations, we propose CoBA-RL, a reinforcement learning algorithm designed to adaptively allocate rollout budgets based on the model's evolving capability. Specifically, CoBA-RL utilizes a Capability-Oriented Value function to map tasks to their potential training gains and employs a heap-based greedy strategy to efficiently self-calibrate the distribution of computational resources to samples with high training value. Extensive experiments demonstrate that our approach effectively orchestrates the trade-off between exploration and exploitation, delivering consistent generalization improvements across multiple challenging benchmarks. These findings underscore that quantifying sample training value and optimizing budget allocation are pivotal for advancing LLM post-training efficiency.
$V_0$: A Generalist Value Model for Any Policy at State Zero
Feb 03, 2026Policy gradient methods rely on a baseline to measure the relative advantage of an action, ensuring the model reinforces behaviors that outperform its current average capability. In the training of Large Language Models (LLMs) using Actor-Critic methods (e.g., PPO), this baseline is typically estimated by a Value Model (Critic) often as large as the policy model itself. However, as the policy continuously evolves, the value model requires expensive, synchronous incremental training to accurately track the shifting capabilities of the policy. To avoid this overhead, Group Relative Policy Optimization (GRPO) eliminates the coupled value model by using the average reward of a group of rollouts as the baseline; yet, this approach necessitates extensive sampling to maintain estimation stability. In this paper, we propose $V_0$, a Generalist Value Model capable of estimating the expected performance of any model on unseen prompts without requiring parameter updates. We reframe value estimation by treating the policy's dynamic capability as an explicit context input; specifically, we leverage a history of instruction-performance pairs to dynamically profile the model, departing from the traditional paradigm that relies on parameter fitting to perceive capability shifts. Focusing on value estimation at State Zero (i.e., the initial prompt, hence $V_0$), our model serves as a critical resource scheduler. During GRPO training, $V_0$ predicts success rates prior to rollout, allowing for efficient sampling budget allocation; during deployment, it functions as a router, dispatching instructions to the most cost-effective and suitable model. Empirical results demonstrate that $V_0$ significantly outperforms heuristic budget allocation and achieves a Pareto-optimal trade-off between performance and cost in LLM routing tasks.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Model Assembly Learning with Heterogeneous Layer Weight Merging
Mar 27, 2025Model merging acquires general capabilities without extra data or training by combining multiple models' parameters. Previous approaches achieve linear mode connectivity by aligning parameters into the same loss basin using permutation invariance. In this paper, we introduce Model Assembly Learning (MAL), a novel paradigm for model merging that iteratively integrates parameters from diverse models in an open-ended model zoo to enhance the base model's capabilities. Unlike previous works that require identical architectures, MAL allows the merging of heterogeneous architectures and selective parameters across layers. Specifically, the base model can incorporate parameters from different layers of multiple pre-trained models. We systematically investigate the conditions and fundamental settings of heterogeneous parameter merging, addressing all possible mismatches in layer widths between the base and target models. Furthermore, we establish key laws and provide practical guidelines for effectively implementing MAL.
Capability Instruction Tuning: A New Paradigm for Dynamic LLM Routing
Feb 24, 2025Large Language Models (LLMs) have demonstrated human-like instruction-following abilities, particularly those exceeding 100 billion parameters. The combined capability of some smaller, resource-friendly LLMs can address most of the instructions that larger LLMs excel at. In this work, we explore how to route the best-performing LLM for each instruction to achieve better overall performance. We develop a new paradigm, constructing capability instructions with model capability representation, user instruction, and performance inquiry prompts to assess the performance. To learn from capability instructions, we introduce a new end-to-end framework called Model Selection with Aptitude Test (Model-SAT), which generates positive and negative samples based on what different models perform well or struggle with. Model-SAT uses a model capability encoder that extends its model representation to a lightweight LLM. Our experiments show that Model-SAT understands the performance dimensions of candidate models and provides the probabilities of their capability to handle various instructions. Additionally, during deployment, a new model can quickly infer its aptitude test results across 50 tasks, each with 20 shots. Model-SAT performs state-of-the-art model routing without candidate inference and in real-world new model-released scenarios. The code is available at https://github.com/Now-Join-Us/CIT-LLM-Routing
OmniEvalKit: A Modular, Lightweight Toolbox for Evaluating Large Language Model and its Omni-Extensions
Dec 09, 2024The rapid advancements in Large Language Models (LLMs) have significantly expanded their applications, ranging from multilingual support to domain-specific tasks and multimodal integration. In this paper, we present OmniEvalKit, a novel benchmarking toolbox designed to evaluate LLMs and their omni-extensions across multilingual, multidomain, and multimodal capabilities. Unlike existing benchmarks that often focus on a single aspect, OmniEvalKit provides a modular, lightweight, and automated evaluation system. It is structured with a modular architecture comprising a Static Builder and Dynamic Data Flow, promoting the seamless integration of new models and datasets. OmniEvalKit supports over 100 LLMs and 50 evaluation datasets, covering comprehensive evaluations across thousands of model-dataset combinations. OmniEvalKit is dedicated to creating an ultra-lightweight and fast-deployable evaluation framework, making downstream applications more convenient and versatile for the AI community.
Wings: Learning Multimodal LLMs without Text-only Forgetting
Jun 05, 2024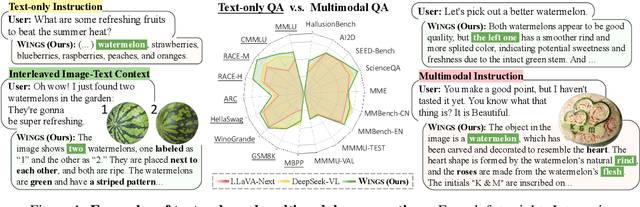
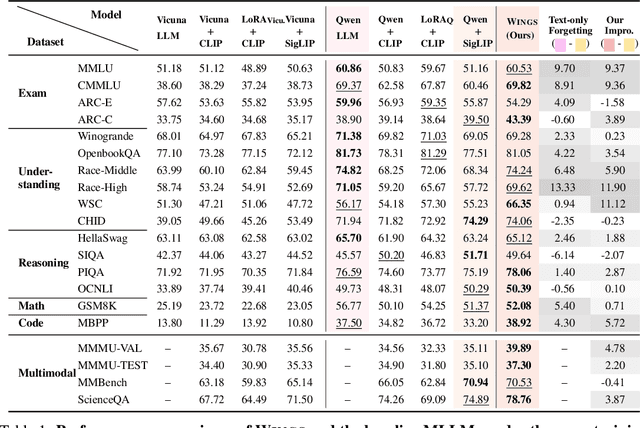
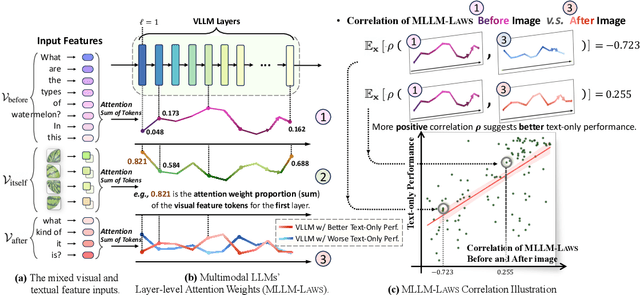
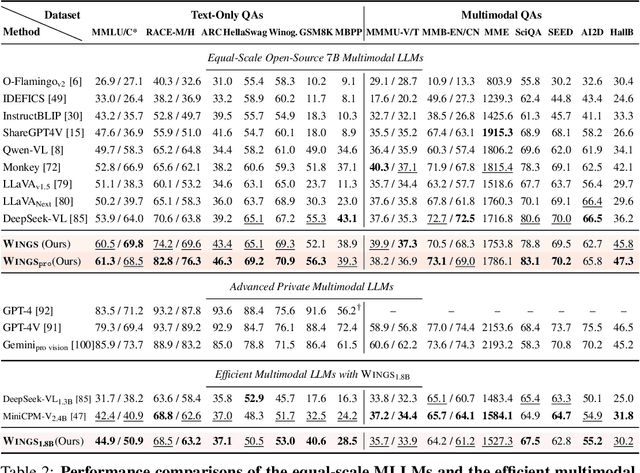
Multimodal large language models (MLLMs), initiated with a trained LLM, first align images with text and then fine-tune on multimodal mixed inputs. However, the MLLM catastrophically forgets the text-only instructions, which do not include images and can be addressed within the initial LLM. In this paper, we present Wings, a novel MLLM that excels in both text-only dialogues and multimodal comprehension. Analyzing MLLM attention in multimodal instructions reveals that text-only forgetting is related to the attention shifts from pre-image to post-image text. From that, we construct extra modules that act as the boosted learner to compensate for the attention shift. The complementary visual and textual learners, like "wings" on either side, are connected in parallel within each layer's attention block. Initially, image and text inputs are aligned with visual learners operating alongside the main attention, balancing focus on visual elements. Textual learners are later collaboratively integrated with attention-based routing to blend the outputs of the visual and textual learners. We design the Low-Rank Residual Attention (LoRRA) to guarantee high efficiency for learners. Our experimental results demonstrate that Wings outperforms equally-scaled MLLMs in both text-only and visual question-answering tasks. On a newly constructed Interleaved Image-Text (IIT) benchmark, Wings exhibits superior performance from text-only-rich to multimodal-rich question-answering tasks.
Few-Shot Class-Incremental Learning via Training-Free Prototype Calibration
Dec 08, 2023


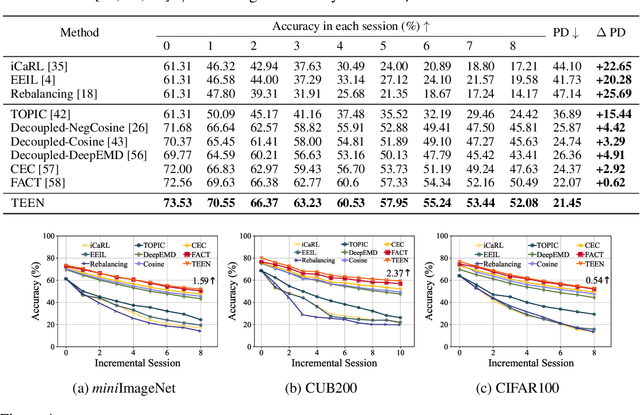
Real-world scenarios are usually accompanied by continuously appearing classes with scare labeled samples, which require the machine learning model to incrementally learn new classes and maintain the knowledge of base classes. In this Few-Shot Class-Incremental Learning (FSCIL) scenario, existing methods either introduce extra learnable components or rely on a frozen feature extractor to mitigate catastrophic forgetting and overfitting problems. However, we find a tendency for existing methods to misclassify the samples of new classes into base classes, which leads to the poor performance of new classes. In other words, the strong discriminability of base classes distracts the classification of new classes. To figure out this intriguing phenomenon, we observe that although the feature extractor is only trained on base classes, it can surprisingly represent the semantic similarity between the base and unseen new classes. Building upon these analyses, we propose a simple yet effective Training-frEE calibratioN (TEEN) strategy to enhance the discriminability of new classes by fusing the new prototypes (i.e., mean features of a class) with weighted base prototypes. In addition to standard benchmarks in FSCIL, TEEN demonstrates remarkable performance and consistent improvements over baseline methods in the few-shot learning scenario. Code is available at: https://github.com/wangkiw/TEEN
ZhiJian: A Unifying and Rapidly Deployable Toolbox for Pre-trained Model Reuse
Aug 17, 2023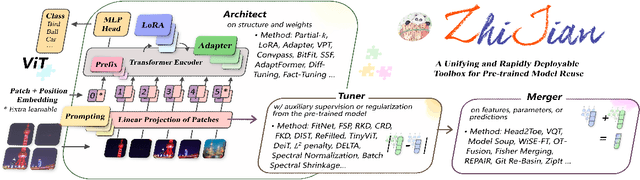
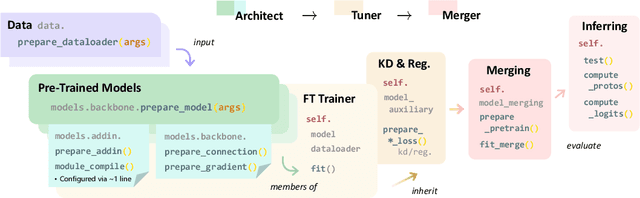
The rapid expansion of foundation pre-trained models and their fine-tuned counterparts has significantly contributed to the advancement of machine learning. Leveraging pre-trained models to extract knowledge and expedite learning in real-world tasks, known as "Model Reuse", has become crucial in various applications. Previous research focuses on reusing models within a certain aspect, including reusing model weights, structures, and hypothesis spaces. This paper introduces ZhiJian, a comprehensive and user-friendly toolbox for model reuse, utilizing the PyTorch backend. ZhiJian presents a novel paradigm that unifies diverse perspectives on model reuse, encompassing target architecture construction with PTM, tuning target model with PTM, and PTM-based inference. This empowers deep learning practitioners to explore downstream tasks and identify the complementary advantages among different methods. ZhiJian is readily accessible at https://github.com/zhangyikaii/lamda-zhijian facilitating seamless utilization of pre-trained models and streamlining the model reuse process for researchers and developers.
Model Spider: Learning to Rank Pre-Trained Models Efficiently
Jun 06, 2023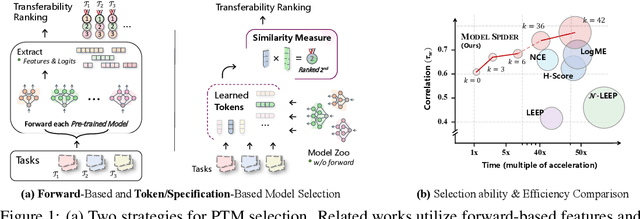
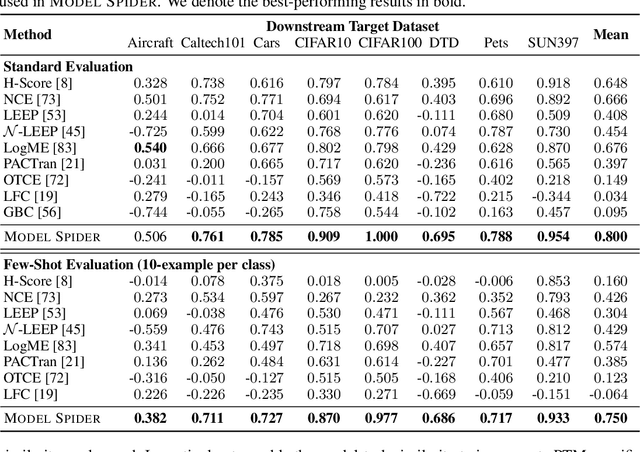
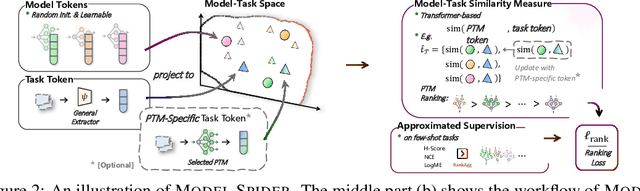
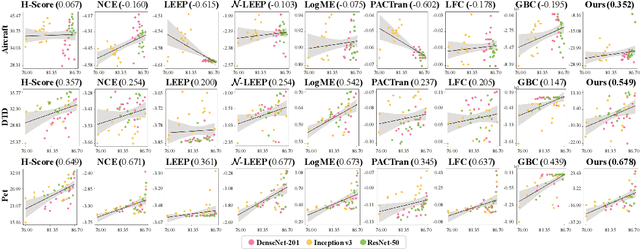
Figuring out which Pre-Trained Model (PTM) from a model zoo fits the target task is essential to take advantage of plentiful model resources. With the availability of numerous heterogeneous PTMs from diverse fields, efficiently selecting the most suitable PTM is challenging due to the time-consuming costs of carrying out forward or backward passes over all PTMs. In this paper, we propose Model Spider, which tokenizes both PTMs and tasks by summarizing their characteristics into vectors to enable efficient PTM selection. By leveraging the approximated performance of PTMs on a separate set of training tasks, Model Spider learns to construct tokens and measure the fitness score between a model-task pair via their tokens. The ability to rank relevant PTMs higher than others generalizes to new tasks. With the top-ranked PTM candidates, we further learn to enrich task tokens with their PTM-specific semantics to re-rank the PTMs for better selection. Model Spider balances efficiency and selection ability, making PTM selection like a spider preying on a web. Model Spider demonstrates promising performance in various configurations of model zoos.