 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Class-Incremental Learning via Training-Free Prototype Calibration
Dec 08, 2023


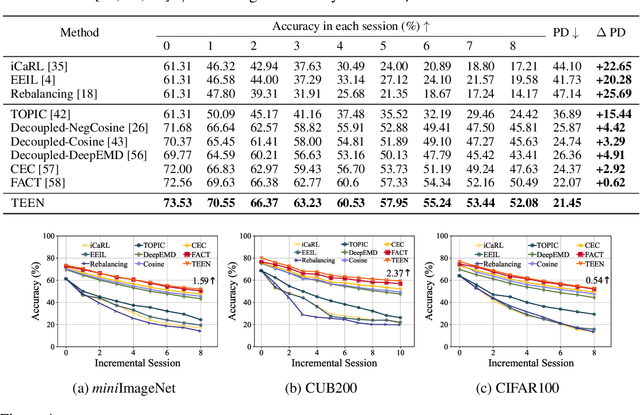
Real-world scenarios are usually accompanied by continuously appearing classes with scare labeled samples, which require the machine learning model to incrementally learn new classes and maintain the knowledge of base classes. In this Few-Shot Class-Incremental Learning (FSCIL) scenario, existing methods either introduce extra learnable components or rely on a frozen feature extractor to mitigate catastrophic forgetting and overfitting problems. However, we find a tendency for existing methods to misclassify the samples of new classes into base classes, which leads to the poor performance of new classes. In other words, the strong discriminability of base classes distracts the classification of new classes. To figure out this intriguing phenomenon, we observe that although the feature extractor is only trained on base classes, it can surprisingly represent the semantic similarity between the base and unseen new classes. Building upon these analyses, we propose a simple yet effective Training-frEE calibratioN (TEEN) strategy to enhance the discriminability of new classes by fusing the new prototypes (i.e., mean features of a class) with weighted base prototypes. In addition to standard benchmarks in FSCIL, TEEN demonstrates remarkable performance and consistent improvements over baseline methods in the few-shot learning scenario. Code is available at: https://github.com/wangkiw/TEEN
ZhiJian: A Unifying and Rapidly Deployable Toolbox for Pre-trained Model Reuse
Aug 17, 2023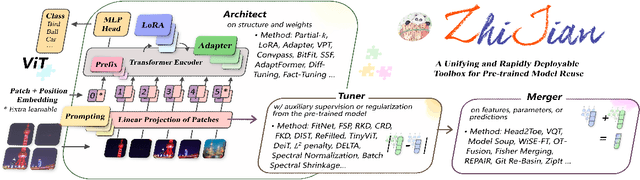
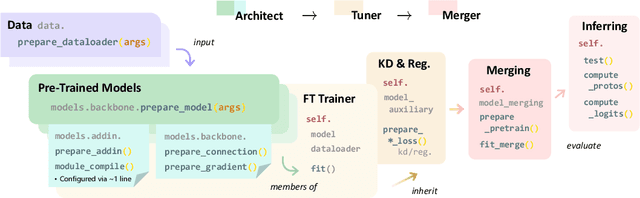
The rapid expansion of foundation pre-trained models and their fine-tuned counterparts has significantly contributed to the advancement of machine learning. Leveraging pre-trained models to extract knowledge and expedite learning in real-world tasks, known as "Model Reuse", has become crucial in various applications. Previous research focuses on reusing models within a certain aspect, including reusing model weights, structures, and hypothesis spaces. This paper introduces ZhiJian, a comprehensive and user-friendly toolbox for model reuse, utilizing the PyTorch backend. ZhiJian presents a novel paradigm that unifies diverse perspectives on model reuse, encompassing target architecture construction with PTM, tuning target model with PTM, and PTM-based inference. This empowers deep learning practitioners to explore downstream tasks and identify the complementary advantages among different methods. ZhiJian is readily accessible at https://github.com/zhangyikaii/lamda-zhijian facilitating seamless utilization of pre-trained models and streamlining the model reuse process for researchers and developers.
Streaming CTR Prediction: Rethinking Recommendation Task for Real-World Streaming Data
Jul 14, 2023



The Click-Through Rate (CTR) prediction task is critical in industrial recommender systems, where models are usually deployed on dynamic streaming data in practical applications. Such streaming data in real-world recommender systems face many challenges, such as distribution shift, temporal non-stationarity, and systematic biases, which bring difficulties to the training and utilizing of recommendation models. However, most existing studies approach the CTR prediction as a classification task on static datasets, assuming that the train and test sets are independent and identically distributed (a.k.a, i.i.d. assumption). To bridge this gap, we formulate the CTR prediction problem in streaming scenarios as a Streaming CTR Prediction task. Accordingly, we propose dedicated benchmark settings and metrics to evaluate and analyze the performance of the models in streaming data. To better understand the differences compared to traditional CTR prediction tasks, we delve into the factors that may affect the model performance, such as parameter scale, normalization, regularization, etc. The results reveal the existence of the ''streaming learning dilemma'', whereby the same factor may have different effects on model performance in the static and streaming scenarios. Based on the findings, we propose two simple but inspiring methods (i.e., tuning key parameters and exemplar replay) that significantly improve the effectiveness of the CTR models in the new streaming scenario. We hope our work will inspire further research on streaming CTR prediction and help improve the robustness and adaptability of recommender systems.
Deep Class-Incremental Learning: A Survey
Feb 07, 2023



Deep models, e.g., CNNs and Vision Transformers, have achieved impressive achievements in many vision tasks in the closed world. However, novel classes emerge from time to time in our ever-changing world, requiring a learning system to acquire new knowledge continually. For example, a robot needs to understand new instructions, and an opinion monitoring system should analyze emerging topics every day. Class-Incremental Learning (CIL) enables the learner to incorporate the knowledge of new classes incrementally and build a universal classifier among all seen classes. Correspondingly, when directly training the model with new class instances, a fatal problem occurs -- the model tends to catastrophically forget the characteristics of former ones, and its performance drastically degrades. There have been numerous efforts to tackle catastrophic forgetting in the machine learning community. In this paper, we survey comprehensively recent advances in deep class-incremental learning and summarize these methods from three aspects, i.e., data-centric, model-centric, and algorithm-centric. We also provide a rigorous and unified evaluation of 16 methods in benchmark image classification tasks to find out the characteristics of different algorithms empirically. Furthermore, we notice that the current comparison protocol ignores the influence of memory budget in model storage, which may result in unfair comparison and biased results. Hence, we advocate fair comparison by aligning the memory budget in evaluation, as well as several memory-agnostic performance measures. The source code to reproduce these evaluations is available at https://github.com/zhoudw-zdw/CIL_Survey/
A Model or 603 Exemplars: Towards Memory-Efficient Class-Incremental Learning
May 26, 2022

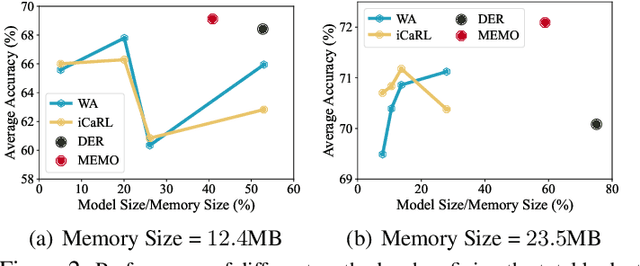

Real-world applications require the classification model to adapt to new classes without forgetting old ones. Correspondingly, Class-Incremental Learning (CIL) aims to train a model with limited memory size to meet this requirement. Typical CIL methods tend to save representative exemplars from former classes to resist forgetting, while recent works find that storing models from history can substantially boost the performance. However, the stored models are not counted into the memory budget, which implicitly results in unfair comparisons. We find that when counting the model size into the total budget and comparing methods with aligned memory size, saving models do not consistently work, especially for the case with limited memory budgets. As a result, we need to holistically evaluate different CIL methods at different memory scales and simultaneously consider accuracy and memory size for measurement. On the other hand, we dive deeply into the construction of the memory buffer for memory efficiency. By analyzing the effect of different layers in the network, we find that shallow and deep layers have different characteristics in CIL. Motivated by this, we propose a simple yet effective baseline, denoted as MEMO for Memory-efficient Expandable MOdel. MEMO extends specialized layers based on the shared generalized representations, efficiently extracting diverse representations with modest cost and maintaining representative exemplars. Extensive experiments on benchmark datasets validate MEMO's competitive performance.