 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Adapter Routing for Long-Tailed Class-Incremental Learning
Sep 11, 2024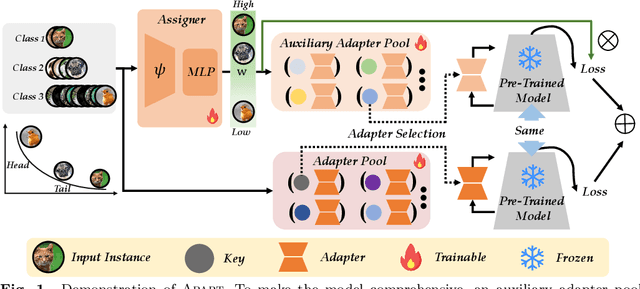
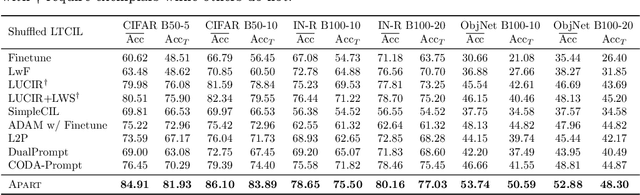
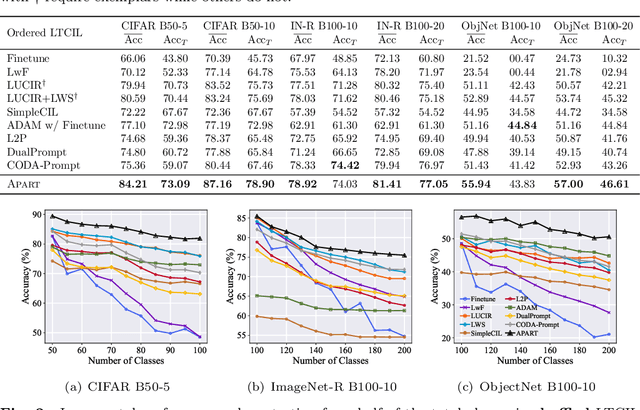
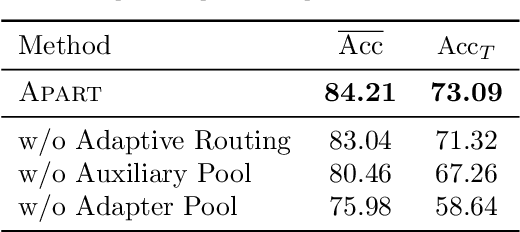
In our ever-evolving world, new data exhibits a long-tailed distribution, such as e-commerce platform reviews. This necessitates continuous model learning imbalanced data without forgetting, addressing the challenge of long-tailed class-incremental learning (LTCIL). Existing methods often rely on retraining linear classifiers with former data, which is impractical in real-world settings. In this paper, we harness the potent representation capabilities of pre-trained models and introduce AdaPtive Adapter RouTing (APART) as an exemplar-free solution for LTCIL. To counteract forgetting, we train inserted adapters with frozen pre-trained weights for deeper adaptation and maintain a pool of adapters for selection during sequential model updates. Additionally, we present an auxiliary adapter pool designed for effective generalization, especially on minority classes. Adaptive instance routing across these pools captures crucial correlations, facilitating a comprehensive representation of all classes. Consequently, APART tackles the imbalance problem as well as catastrophic forgetting in a unified framework. Extensive benchmark experiments validate the effectiveness of APART. Code is available at: https://github.com/vita-qzh/APART
TV100: A TV Series Dataset that Pre-Trained CLIP Has Not Seen
Apr 16, 2024The era of pre-trained models has ushered in a wealth of new insights for the machine learning community. Among the myriad of questions that arise, one of paramount importance is: 'Do pre-trained models possess comprehensive knowledge?' This paper seeks to address this crucial inquiry. In line with our objective, we have made publicly available a novel dataset comprised of images from TV series released post-2021. This dataset holds significant potential for use in various research areas, including the evaluation of incremental learning, novel class discovery, and long-tailed learning, among others. Project page: https://tv-100.github.io/
Deep Class-Incremental Learning: A Survey
Feb 07, 2023



Deep models, e.g., CNNs and Vision Transformers, have achieved impressive achievements in many vision tasks in the closed world. However, novel classes emerge from time to time in our ever-changing world, requiring a learning system to acquire new knowledge continually. For example, a robot needs to understand new instructions, and an opinion monitoring system should analyze emerging topics every day. Class-Incremental Learning (CIL) enables the learner to incorporate the knowledge of new classes incrementally and build a universal classifier among all seen classes. Correspondingly, when directly training the model with new class instances, a fatal problem occurs -- the model tends to catastrophically forget the characteristics of former ones, and its performance drastically degrades. There have been numerous efforts to tackle catastrophic forgetting in the machine learning community. In this paper, we survey comprehensively recent advances in deep class-incremental learning and summarize these methods from three aspects, i.e., data-centric, model-centric, and algorithm-centric. We also provide a rigorous and unified evaluation of 16 methods in benchmark image classification tasks to find out the characteristics of different algorithms empirically. Furthermore, we notice that the current comparison protocol ignores the influence of memory budget in model storage, which may result in unfair comparison and biased results. Hence, we advocate fair comparison by aligning the memory budget in evaluation, as well as several memory-agnostic performance measures. The source code to reproduce these evaluations is available at https://github.com/zhoudw-zdw/CIL_Survey/