 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Boosted Adapter for Open-Vocabulary Segmentation
Paper and Code
Sep 13, 2024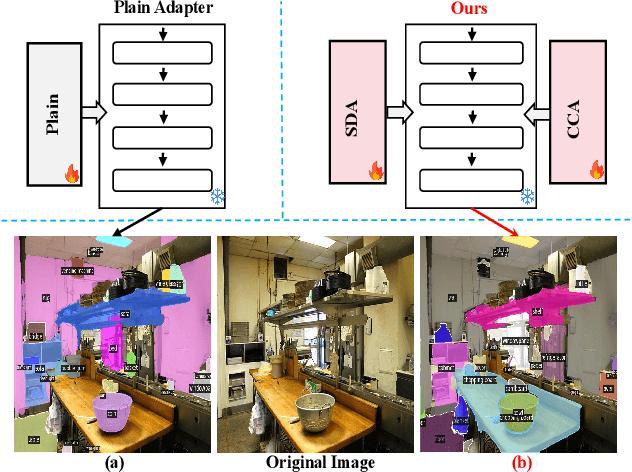
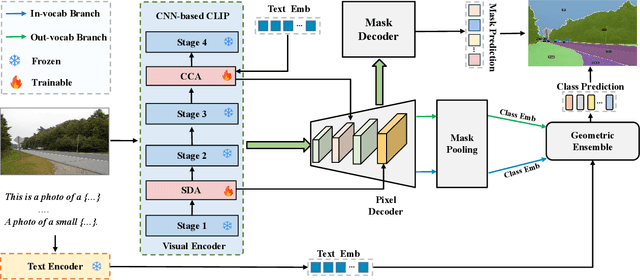
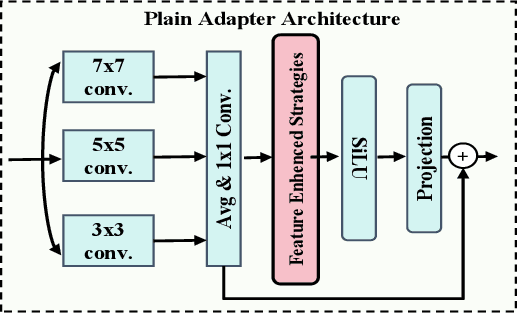
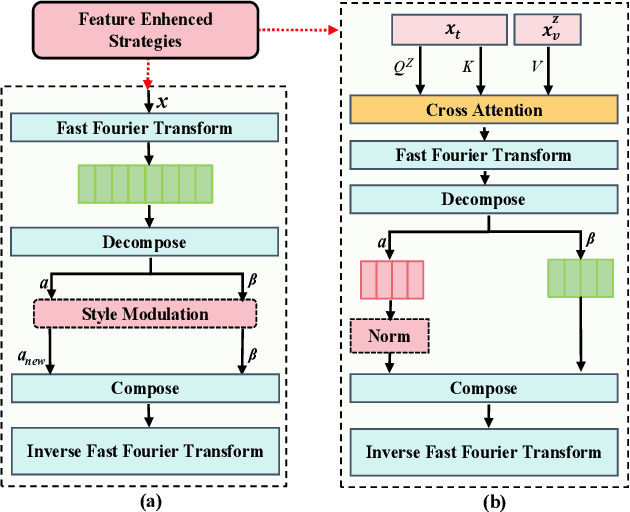
Vision-language models (VLMs) have demonstrated remarkable open-vocabulary object recognition capabilities, motivating their adaptation for dense prediction tasks like segmentation. However, directly applying VLMs to such tasks remains challenging due to their lack of pixel-level granularity and the limited data available for fine-tuning, leading to overfitting and poor generalization. To address these limitations, we propose Generalization Boosted Adapter (GBA), a novel adapter strategy that enhances the generalization and robustness of VLMs for open-vocabulary segmentation. GBA comprises two core components: (1) a Style Diversification Adapter (SDA) that decouples features into amplitude and phase components, operating solely on the amplitude to enrich the feature space representation while preserving semantic consistency; and (2) a Correlation Constraint Adapter (CCA) that employs cross-attention to establish tighter semantic associations between text categories and target regions, suppressing irrelevant low-frequency ``noise'' information and avoiding erroneous associations. Through the synergistic effect of the shallow SDA and the deep CCA, GBA effectively alleviates overfitting issues and enhances the semantic relevance of feature representations. As a simple, efficient, and plug-and-play component, GBA can be flexibly integrated into various CLIP-based methods, demonstrating broad applicability and achieving state-of-the-art performance on multiple open-vocabulary segmentation benchmarks.