 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDummy-Aware Weighted Attack (DAWA): Breaking the Safe Sink in Dummy Class Defenses
Mar 31, 2026Adversarial robustness evaluation faces a critical challenge as new defense paradigms emerge that can exploit limitations in existing assessment methods. This paper reveals that Dummy Classes-based defenses, which introduce an additional "dummy" class as a safety sink for adversarial examples, achieve significantly overestimated robustness under conventional evaluation strategies like AutoAttack. The fundamental limitation stems from these attacks' singular focus on misleading the true class label, which aligns perfectly with the defense mechanism--successful attacks are simply captured by the dummy class. To address this gap, we propose Dummy-Aware Weighted Attack (DAWA), a novel evaluation method that simultaneously targets both the true label and dummy label with adaptive weighting during adversarial example synthesis. Extensive experiments demonstrate that DAWA effectively breaks this defense paradigm, reducing the measured robustness of a leading Dummy Classes-based defense from 58.61% to 29.52% on CIFAR-10 under l_infty perturbation (epsilon=8/255). Our work provides a more reliable benchmark for evaluating this emerging class of defenses and highlights the need for continuous evolution of robustness assessment methodologies.
Generalization Boosted Adapter for Open-Vocabulary Segmentation
Sep 13, 2024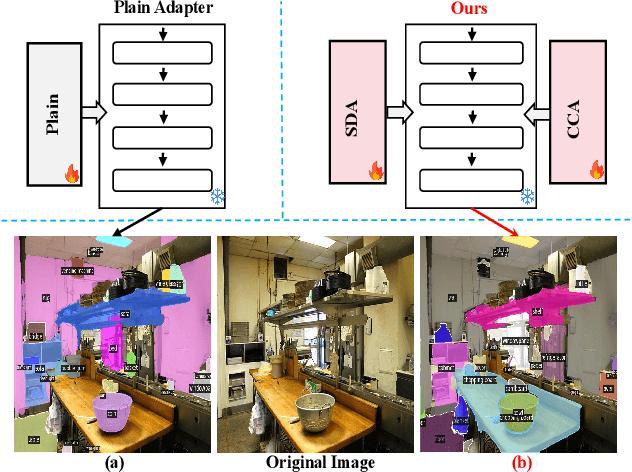
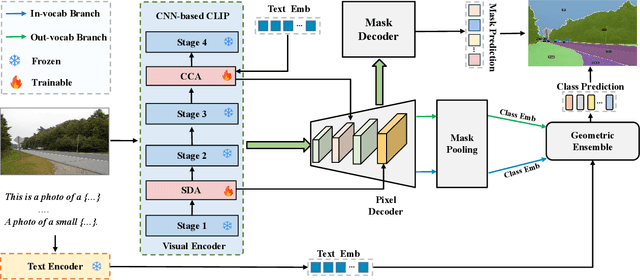
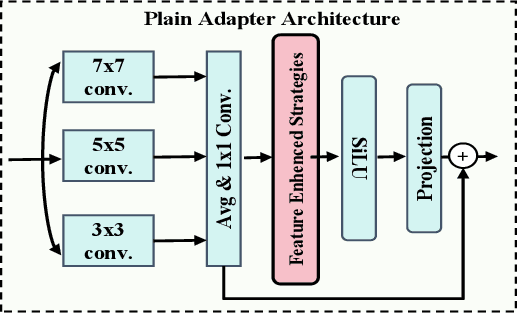
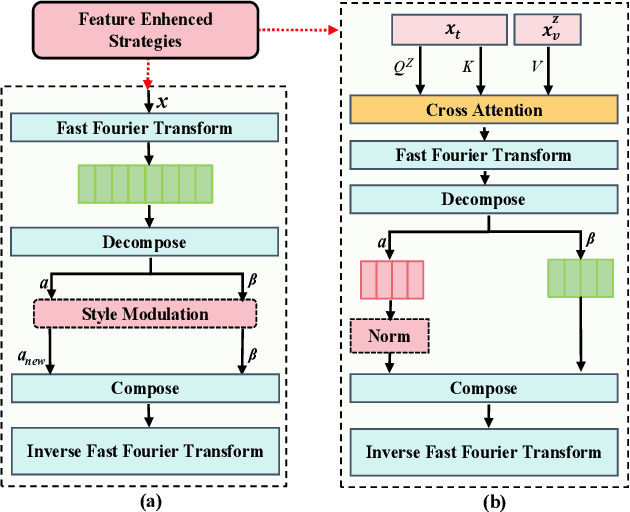
Vision-language models (VLMs) have demonstrated remarkable open-vocabulary object recognition capabilities, motivating their adaptation for dense prediction tasks like segmentation. However, directly applying VLMs to such tasks remains challenging due to their lack of pixel-level granularity and the limited data available for fine-tuning, leading to overfitting and poor generalization. To address these limitations, we propose Generalization Boosted Adapter (GBA), a novel adapter strategy that enhances the generalization and robustness of VLMs for open-vocabulary segmentation. GBA comprises two core components: (1) a Style Diversification Adapter (SDA) that decouples features into amplitude and phase components, operating solely on the amplitude to enrich the feature space representation while preserving semantic consistency; and (2) a Correlation Constraint Adapter (CCA) that employs cross-attention to establish tighter semantic associations between text categories and target regions, suppressing irrelevant low-frequency ``noise'' information and avoiding erroneous associations. Through the synergistic effect of the shallow SDA and the deep CCA, GBA effectively alleviates overfitting issues and enhances the semantic relevance of feature representations. As a simple, efficient, and plug-and-play component, GBA can be flexibly integrated into various CLIP-based methods, demonstrating broad applicability and achieving state-of-the-art performance on multiple open-vocabulary segmentation benchmarks.
The Development of LLMs for Embodied Navigation
Nov 18, 2023



In recent years, the rapid advancement of Large Language Models (LLMs) such as the Generative Pre-trained Transformer (GPT) has attracted increasing attention due to their potential in a variety of practical applications. The application of LLMs with Embodied Intelligence has emerged as a significant area of focus. Among the myriad applications of LLMs, navigation tasks are particularly noteworthy because they demand a deep understanding of the environment and quick, accurate decision-making. LLMs can augment embodied intelligence systems with sophisticated environmental perception and decision-making support, leveraging their robust language and image-processing capabilities. This article offers an exhaustive summary of the symbiosis between LLMs and embodied intelligence with a focus on navigation. It reviews state-of-the-art models, research methodologies, and assesses the advantages and disadvantages of existing embodied navigation models and datasets. Finally, the article elucidates the role of LLMs in embodied intelligence, based on current research, and forecasts future directions in the field. A comprehensive list of studies in this survey is available at https://github.com/Rongtao-Xu/Awesome-LLM-EN