 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Unseen: Guiding Personalized Diffusion Models to Expose Training Data
Paper and Code
Oct 03, 2024
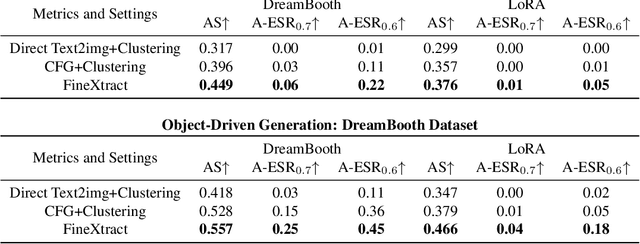
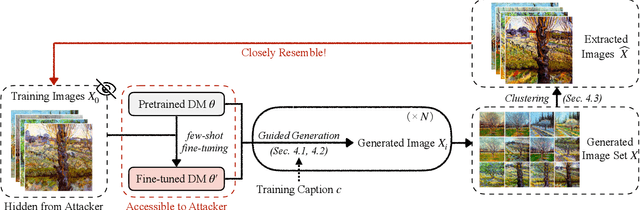

Diffusion Models (DMs) have evolved into advanced image generation tools, especially for few-shot fine-tuning where a pretrained DM is fine-tuned on a small set of images to capture specific styles or objects. Many people upload these personalized checkpoints online, fostering communities such as Civitai and HuggingFace. However, model owners may overlook the potential risks of data leakage by releasing their fine-tuned checkpoints. Moreover, concerns regarding copyright violations arise when unauthorized data is used during fine-tuning. In this paper, we ask: "Can training data be extracted from these fine-tuned DMs shared online?" A successful extraction would present not only data leakage threats but also offer tangible evidence of copyright infringement. To answer this, we propose FineXtract, a framework for extracting fine-tuning data. Our method approximates fine-tuning as a gradual shift in the model's learned distribution -- from the original pretrained DM toward the fine-tuning data. By extrapolating the models before and after fine-tuning, we guide the generation toward high-probability regions within the fine-tuned data distribution. We then apply a clustering algorithm to extract the most probable images from those generated using this extrapolated guidance. Experiments on DMs fine-tuned with datasets such as WikiArt, DreamBooth, and real-world checkpoints posted online validate the effectiveness of our method, extracting approximately 20% of fine-tuning data in most cases, significantly surpassing baseline performance.