 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Know What to Drop: Self-Attention Guided KV Cache Eviction for Efficient Long-Context Inference
Mar 11, 2025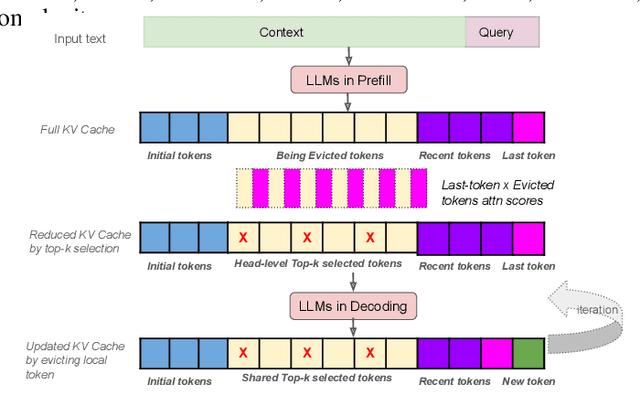
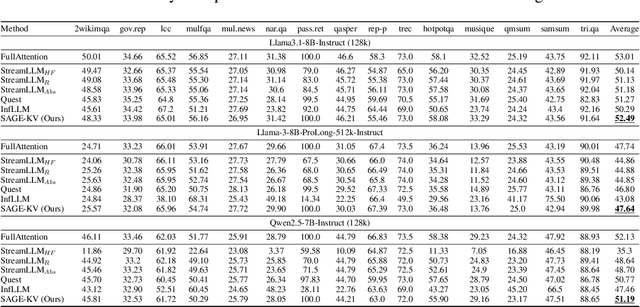
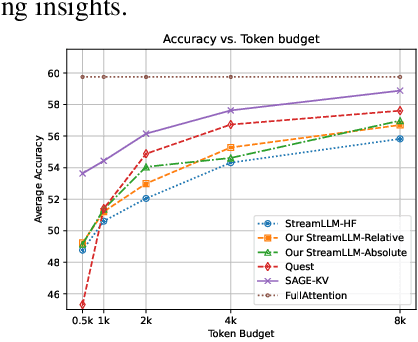
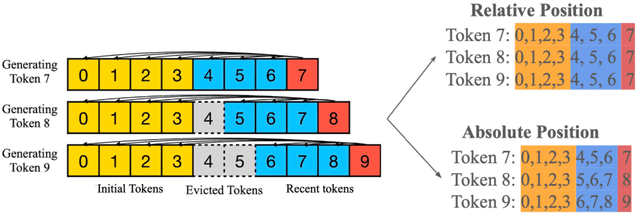
Efficient long-context inference is critical as large language models (LLMs) adopt context windows of ranging from 128K to 1M tokens. However, the growing key-value (KV) cache and the high computational complexity of attention create significant bottlenecks in memory usage and latency. In this paper, we find that attention in diverse long-context tasks exhibits sparsity, and LLMs implicitly "know" which tokens can be dropped or evicted at the head level after the pre-filling stage. Based on this insight, we propose Self-Attention Guided Eviction~(SAGE-KV), a simple and effective KV eviction cache method for long-context inference. After prefilling, our method performs a one-time top-k selection at both the token and head levels to compress the KV cache, enabling efficient inference with the reduced cache. Evaluations on LongBench and three long-context LLMs (Llama3.1-8B-Instruct-128k, Llama3-8B-Prolong-512k-Instruct, and Qwen2.5-7B-Instruct-128k) show that SAGE-KV maintains accuracy comparable to full attention while significantly improving efficiency. Specifically, SAGE-KV achieves 4x higher memory efficiency with improved accuracy over the static KV cache selection method StreamLLM, and 2x higher memory efficiency with better accuracy than the dynamic KV cache selection method Quest.
Kernel Looping: Eliminating Synchronization Boundaries for Peak Inference Performance
Oct 31, 2024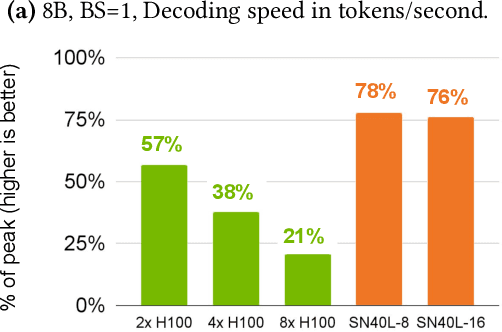
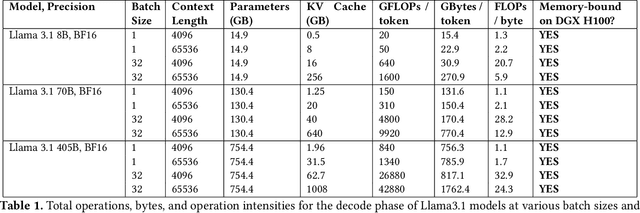
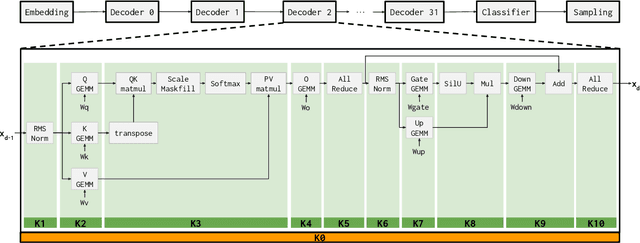

Token generation speed is critical to power the next wave of AI inference applications. GPUs significantly underperform during token generation due to synchronization overheads at kernel boundaries, utilizing only 21% of their peak memory bandwidth. While recent dataflow architectures mitigate these overheads by enabling aggressive fusion of decoder layers into a single kernel, they too leave performance on the table due to synchronization penalties at layer boundaries. This paper presents kernel looping, a specialized global optimization technique which exploits an optimization opportunity brought by combining the unique layer-level fusion possible in modern dataflow architectures with the repeated layer structure found in language models. Kernel looping eliminates synchronization costs between consecutive calls to the same kernel by transforming these calls into a single call to a modified kernel containing a pipelined outer loop. We evaluate kernel looping on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU), a commercial dataflow accelerator for AI. Experiments demonstrate that kernel looping speeds up the decode phase of a wide array of powerful open-source models by up to 2.2$\times$ on SN40L. Kernel looping allows scaling of decode performance over multiple SN40L sockets, achieving speedups of up to 2.5$\times$. Finally, kernel looping enables SN40L to achieve over 90% of peak performance on 8 and 16 sockets and achieve a speedup of up to 3.7$\times$ over DGX H100. Kernel looping, as well as the models evaluated in this paper, are deployed in production in a commercial AI inference cloud.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024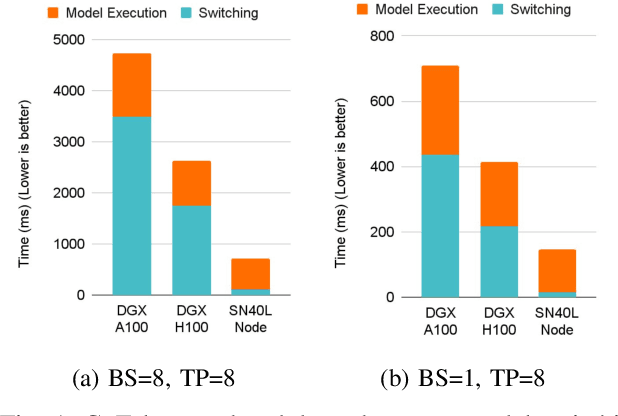
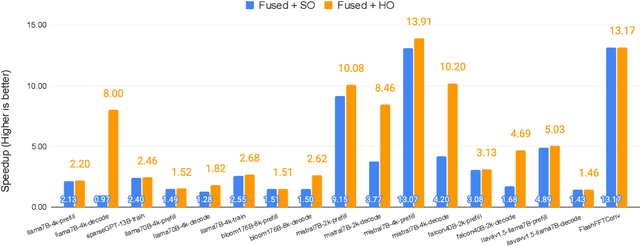
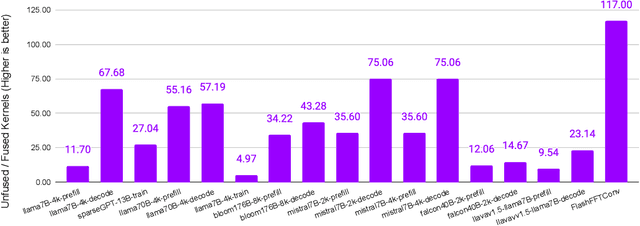
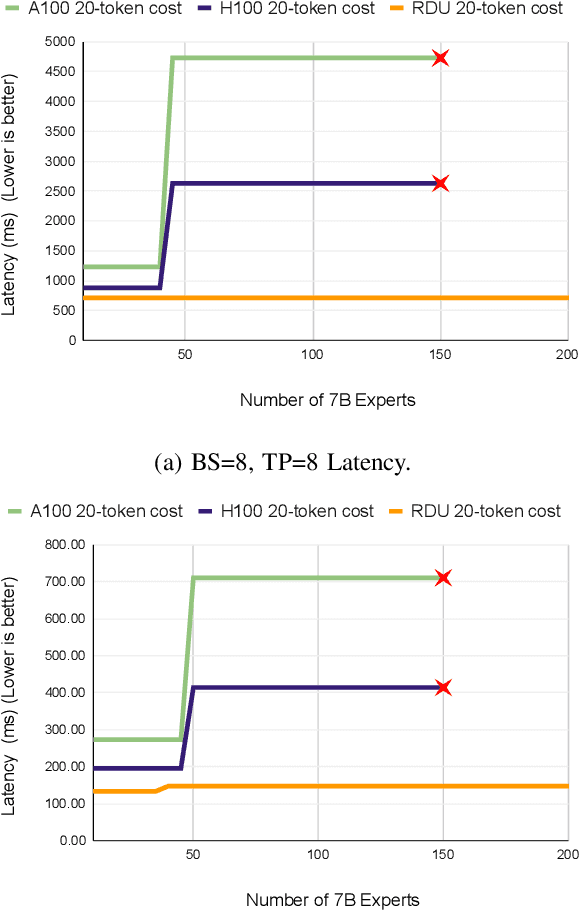
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
Training Large Language Models Efficiently with Sparsity and Dataflow
Apr 11, 2023Large foundation language models have shown their versatility in being able to be adapted to perform a wide variety of downstream tasks, such as text generation, sentiment analysis, semantic search etc. However, training such large foundational models is a non-trivial exercise that requires a significant amount of compute power and expertise from machine learning and systems experts. As models get larger, these demands are only increasing. Sparsity is a promising technique to relieve the compute requirements for training. However, sparsity introduces new challenges in training the sparse model to the same quality as the dense counterparts. Furthermore, sparsity drops the operation intensity and introduces irregular memory access patterns that makes it challenging to efficiently utilize compute resources. This paper demonstrates an end-to-end training flow on a large language model - 13 billion GPT - using sparsity and dataflow. The dataflow execution model and architecture enables efficient on-chip irregular memory accesses as well as native kernel fusion and pipelined parallelism that helps recover device utilization. We show that we can successfully train GPT 13B to the same quality as the dense GPT 13B model, while achieving an end-end speedup of 4.5x over dense A100 baseline.