 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIDiff: Translating Videos via Multi-Modal Instructions with Diffusion Models
Paper and Code
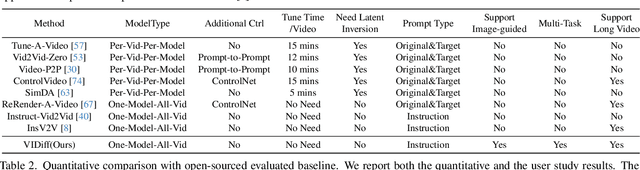
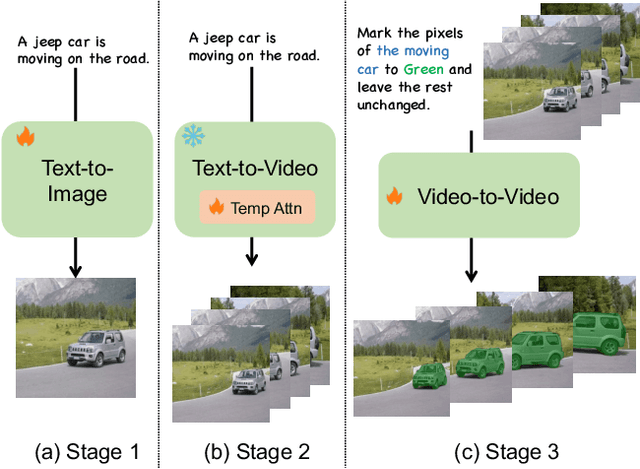

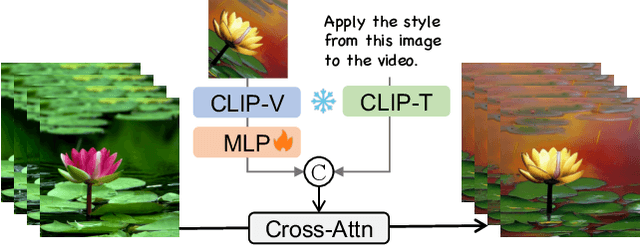
Diffusion models have achieved significant success in image and video generation. This motivates a growing interest in video editing tasks, where videos are edited according to provided text descriptions. However, most existing approaches only focus on video editing for short clips and rely on time-consuming tuning or inference. We are the first to propose Video Instruction Diffusion (VIDiff), a unified foundation model designed for a wide range of video tasks. These tasks encompass both understanding tasks (such as language-guided video object segmentation) and generative tasks (video editing and enhancement). Our model can edit and translate the desired results within seconds based on user instructions. Moreover, we design an iterative auto-regressive method to ensure consistency in editing and enhancing long videos. We provide convincing generative results for diverse input videos and written instructions, both qualitatively and quantitatively. More examples can be found at our website https://ChenHsing.github.io/VIDiff.