 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
Mar 15, 2024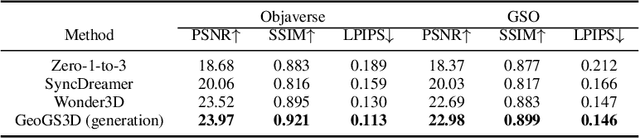
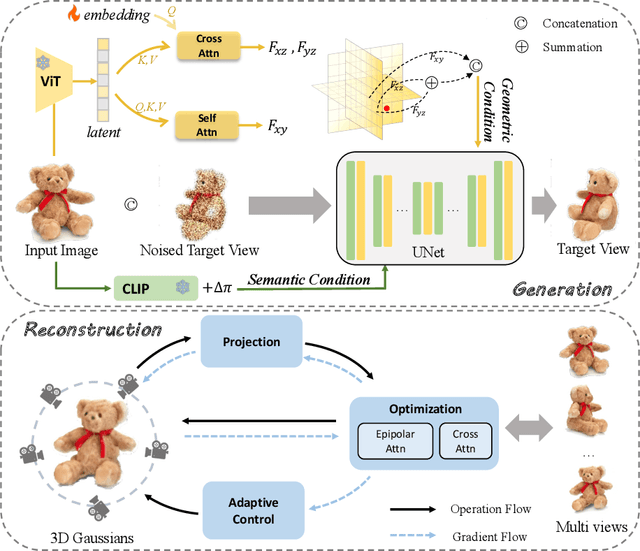
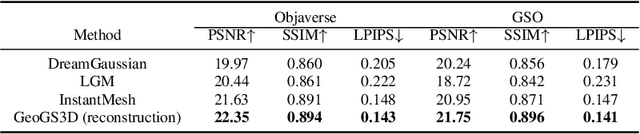
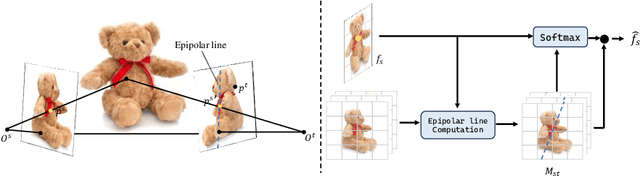
Reconstructing detailed 3D objects from single-view images remains a challenging task due to the limited information available. In this paper, we introduce FDGaussian, a novel two-stage framework for single-image 3D reconstruction. Recent methods typically utilize pre-trained 2D diffusion models to generate plausible novel views from the input image, yet they encounter issues with either multi-view inconsistency or lack of geometric fidelity. To overcome these challenges, we propose an orthogonal plane decomposition mechanism to extract 3D geometric features from the 2D input, enabling the generation of consistent multi-view images. Moreover, we further accelerate the state-of-the-art Gaussian Splatting incorporating epipolar attention to fuse images from different viewpoints. We demonstrate that FDGaussian generates images with high consistency across different views and reconstructs high-quality 3D objects, both qualitatively and quantitatively. More examples can be found at our website https://qjfeng.net/FDGaussian/.
A Survey on Video Diffusion Models
Oct 16, 2023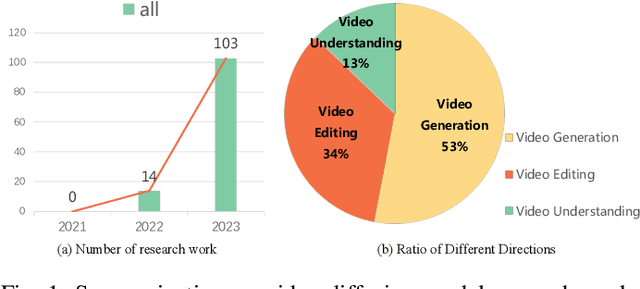
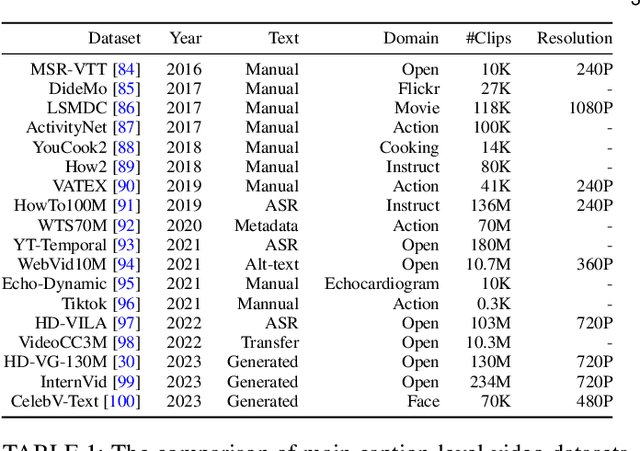

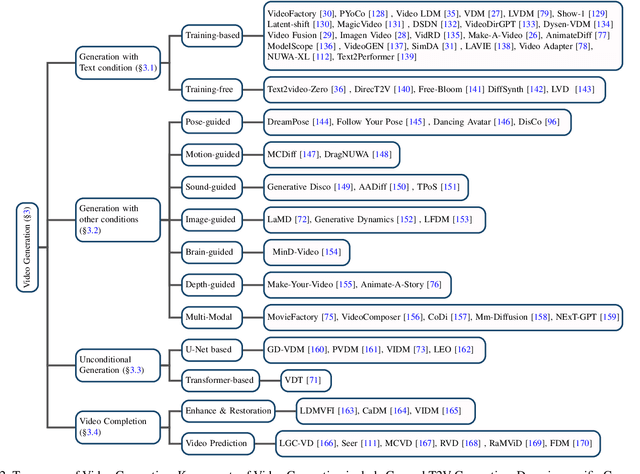
The recent wave of AI-generated content (AIGC) has witnessed substantial success in computer vision, with the diffusion model playing a crucial role in this achievement. Due to their impressive generative capabilities, diffusion models are gradually superseding methods based on GANs and auto-regressive Transformers, demonstrating exceptional performance not only in image generation and editing, but also in the realm of video-related research. However, existing surveys mainly focus on diffusion models in the context of image generation, with few up-to-date reviews on their application in the video domain. To address this gap, this paper presents a comprehensive review of video diffusion models in the AIGC era. Specifically, we begin with a concise introduction to the fundamentals and evolution of diffusion models. Subsequently, we present an overview of research on diffusion models in the video domain, categorizing the work into three key areas: video generation, video editing, and other video understanding tasks. We conduct a thorough review of the literature in these three key areas, including further categorization and practical contributions in the field. Finally, we discuss the challenges faced by research in this domain and outline potential future developmental trends. A comprehensive list of video diffusion models studied in this survey is available at https://github.com/ChenHsing/Awesome-Video-Diffusion-Models.