 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenRec: Unifying Video Generation and Recognition with Diffusion Models
Paper and Code
Aug 27, 2024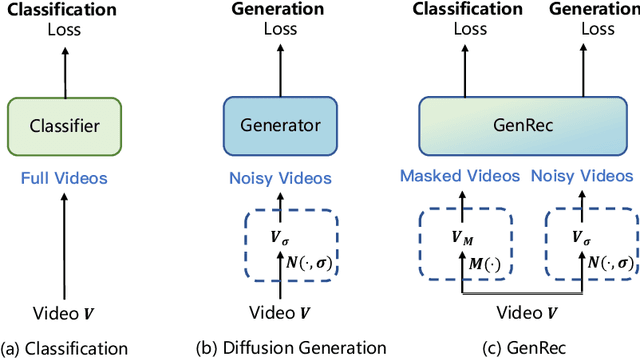
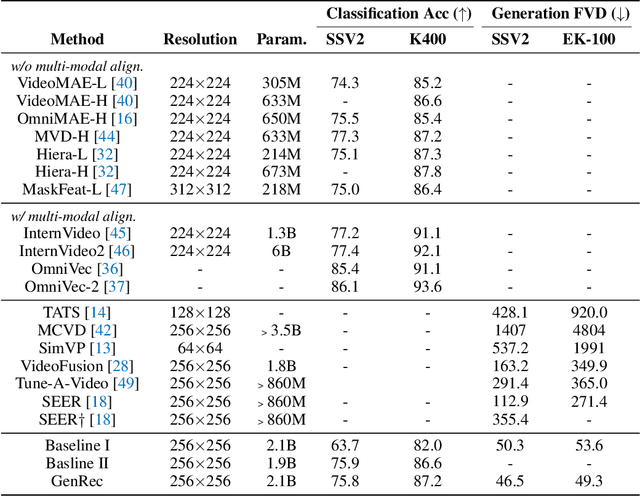
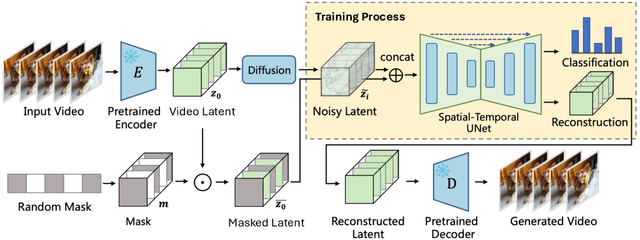
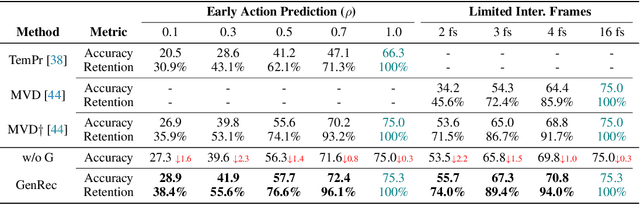
Video diffusion models are able to generate high-quality videos by learning strong spatial-temporal priors on large-scale datasets. In this paper, we aim to investigate whether such priors derived from a generative process are suitable for video recognition, and eventually joint optimization of generation and recognition. Building upon Stable Video Diffusion, we introduce GenRec, the first unified framework trained with a random-frame conditioning process so as to learn generalized spatial-temporal representations. The resulting framework can naturally supports generation and recognition, and more importantly is robust even when visual inputs contain limited information. Extensive experiments demonstrate the efficacy of GenRec for both recognition and generation. In particular, GenRec achieves competitive recognition performance, offering 75.8% and 87.2% accuracy on SSV2 and K400, respectively. GenRec also performs the best class-conditioned image-to-video generation results, achieving 46.5 and 49.3 FVD scores on SSV2 and EK-100 datasets. Furthermore, GenRec demonstrates extraordinary robustness in scenarios that only limited frames can be observed.