 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate Segmentation Purely from Self-Supervision
Feb 27, 2026Accurately segmenting objects without any manual annotations remains one of the core challenges in computer vision. In this work, we introduce Selfment, a fully self-supervised framework that segments foreground objects directly from raw images without human labels, pretrained segmentation models, or any post-processing. Selfment first constructs patch-level affinity graphs from self-supervised features and applies NCut to obtain an initial coarse foreground--background separation. We then introduce Iterative Patch Optimization (IPO), a feature-space refinement procedure that progressively enforces spatial coherence and semantic consistency through iterative patch clustering. The refined masks are subsequently used as supervisory signals to train a lightweight segmentation head with contrastive and region-consistency objectives, allowing the model to learn stable and transferable object representations. Despite its simplicity and complete absence of manual supervision, Selfment sets new state-of-the-art (SoTA) results across multiple benchmarks. It achieves substantial improvements on $F_{\max}$ over previous unsupervised saliency detection methods on ECSSD ($+4.0\%$), HKUIS ($+4.6\%$), and PASCAL-S ($+5.7\%$). Moreover, without any additional fine-tuning, Selfment demonstrates remarkable zero-shot generalization to camouflaged object detection tasks (e.g., $0.910$ $S_m$ on CHAMELEON and $0.792$ $F_β^ω$ on CAMO), outperforming all existing unsupervised approaches and even rivaling the SoTA fully supervised methods.
VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding
Jan 12, 2026This paper presents VideoLoom, a unified Video Large Language Model (Video LLM) for joint spatial-temporal understanding. To facilitate the development of fine-grained spatial and temporal localization capabilities, we curate LoomData-8.7k, a human-centric video dataset with temporally grounded and spatially localized captions. With this, VideoLoom achieves state-of-the-art or highly competitive performance across a variety of spatial and temporal benchmarks (e.g., 63.1 J&F on ReVOS for referring video object segmentation, and 48.3 R1@0.7 on Charades-STA for temporal grounding). In addition, we introduce LoomBench, a novel benchmark consisting of temporal, spatial, and compositional video-question pairs, enabling a comprehensive evaluation of Video LLMs from diverse aspects. Collectively, these contributions offer a universal and effective suite for joint spatial-temporal video understanding, setting a new standard in multimodal intelligence.
Pix2Cap-COCO: Advancing Visual Comprehension via Pixel-Level Captioning
Jan 23, 2025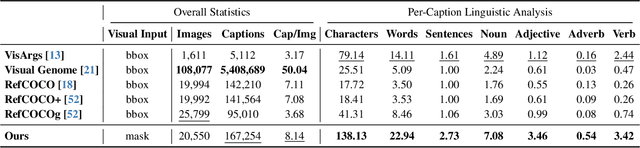
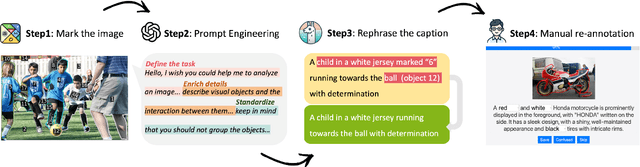

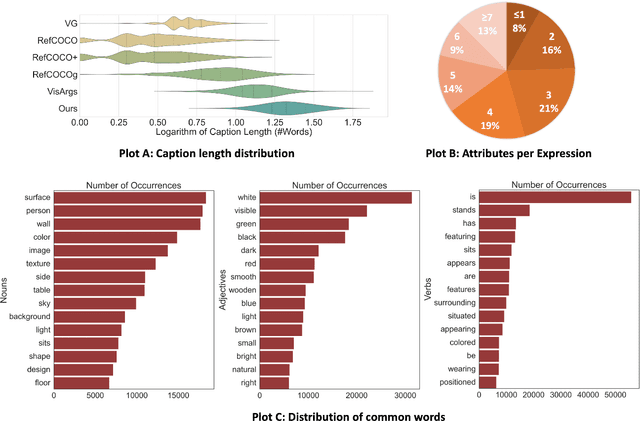
We present Pix2Cap-COCO, the first panoptic pixel-level caption dataset designed to advance fine-grained visual understanding. To achieve this, we carefully design an automated annotation pipeline that prompts GPT-4V to generate pixel-aligned, instance-specific captions for individual objects within images, enabling models to learn more granular relationships between objects and their contexts. This approach results in 167,254 detailed captions, with an average of 22.94 words per caption. Building on Pix2Cap-COCO, we introduce a novel task, panoptic segmentation-captioning, which challenges models to recognize instances in an image and provide detailed descriptions for each simultaneously. To benchmark this task, we design a robust baseline based on X-Decoder. The experimental results demonstrate that Pix2Cap-COCO is a particularly challenging dataset, as it requires models to excel in both fine-grained visual understanding and detailed language generation. Furthermore, we leverage Pix2Cap-COCO for Supervised Fine-Tuning (SFT) on large multimodal models (LMMs) to enhance their performance. For example, training with Pix2Cap-COCO significantly improves the performance of GPT4RoI, yielding gains in CIDEr +1.4%, ROUGE +0.4%, and SPICE +0.5% on Visual Genome dataset, and strengthens its region understanding ability on the ViP-BENCH, with an overall improvement of +5.1%, including notable increases in recognition accuracy +11.2% and language generation quality +22.2%.
FOCUS: Towards Universal Foreground Segmentation
Jan 09, 2025



Foreground segmentation is a fundamental task in computer vision, encompassing various subdivision tasks. Previous research has typically designed task-specific architectures for each task, leading to a lack of unification. Moreover, they primarily focus on recognizing foreground objects without effectively distinguishing them from the background. In this paper, we emphasize the importance of the background and its relationship with the foreground. We introduce FOCUS, the Foreground ObjeCts Universal Segmentation framework that can handle multiple foreground tasks. We develop a multi-scale semantic network using the edge information of objects to enhance image features. To achieve boundary-aware segmentation, we propose a novel distillation method, integrating the contrastive learning strategy to refine the prediction mask in multi-modal feature space. We conduct extensive experiments on a total of 13 datasets across 5 tasks, and the results demonstrate that FOCUS consistently outperforms the state-of-the-art task-specific models on most metrics.
Synthesize, Diagnose, and Optimize: Towards Fine-Grained Vision-Language Understanding
Nov 30, 2023



Vision language models (VLM) have demonstrated remarkable performance across various downstream tasks. However, understanding fine-grained visual-linguistic concepts, such as attributes and inter-object relationships, remains a significant challenge. While several benchmarks aim to evaluate VLMs in finer granularity, their primary focus remains on the linguistic aspect, neglecting the visual dimension. Here, we highlight the importance of evaluating VLMs from both a textual and visual perspective. We introduce a progressive pipeline to synthesize images that vary in a specific attribute while ensuring consistency in all other aspects. Utilizing this data engine, we carefully design a benchmark, SPEC, to diagnose the comprehension of object size, position, existence, and count. Subsequently, we conduct a thorough evaluation of four leading VLMs on SPEC. Surprisingly, their performance is close to random guess, revealing significant limitations. With this in mind, we propose a simply yet effective approach to optimize VLMs in fine-grained understanding, achieving significant improvements on SPEC without compromising the zero-shot performance. Results on two additional fine-grained benchmarks also show consistent improvements, further validating the transferability of our approach.