 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning While Acting: A Skill-Enhanced Test-Time Co-Evolution Framework for Online Lifelong Learning Agents
Jun 03, 2026Lifelong learning is essential for Large Language Model (LLM) agents operating in dynamic, interactive environments. However, existing lifelong learning agents for long-horizon tasks typically depend on discrete skill or past experiences retrieval with static parameters during inference, which prevents them from continuously internalizing test-time feedback like human learners. To bridge this gap, we propose Skill-enhanced Test-Time Co-Evolution (\texttt{LifeSkill}), a two-stage reinforcement learning framework for Online Lifelong Learning Agents. Specifically, we design Verifier-Guided Skill Learning that addresses the lack of direct supervision for skill extraction by rewarding candidate skills according to the average verifier success of multiple skill-conditioned policy rollouts, encouraging the model to generate skills that are useful for solving tasks rather than merely plausible in text. Furthermore, we introduce Online Skill Internalization, which continuously improves the policy model during test-time interaction by transforming skill-conditioned trajectories into reward signals. This enables the agent to directly internalize reasoning capabilities into its parameters, avoiding the context bloat of experience retrieval. Experiments on LifelongAgentBench show that LifeSkill improves average performance by 7 absolute points by comparing with existing lifelong agent baselines.
AssistantX: An LLM-Powered Proactive Assistant in Collaborative Human-Populated Environment
Sep 26, 2024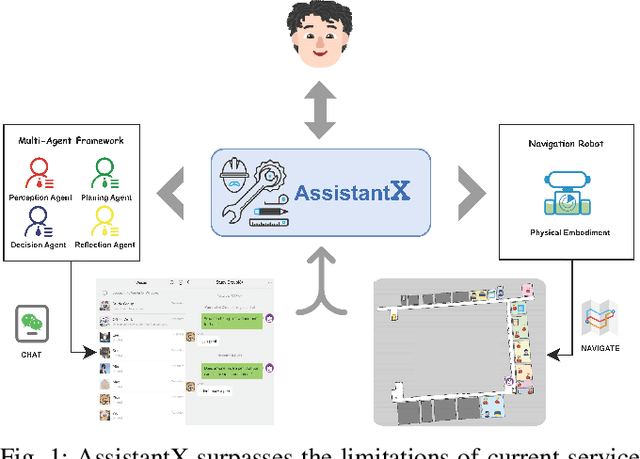
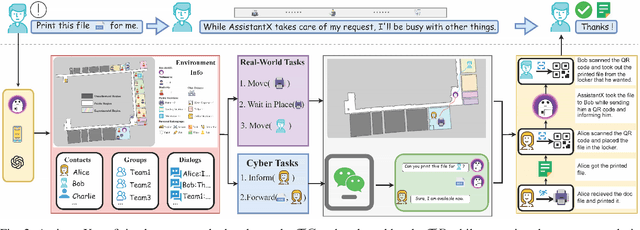
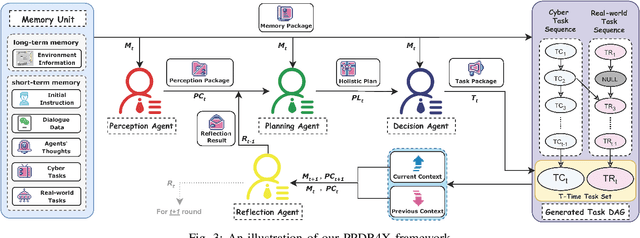
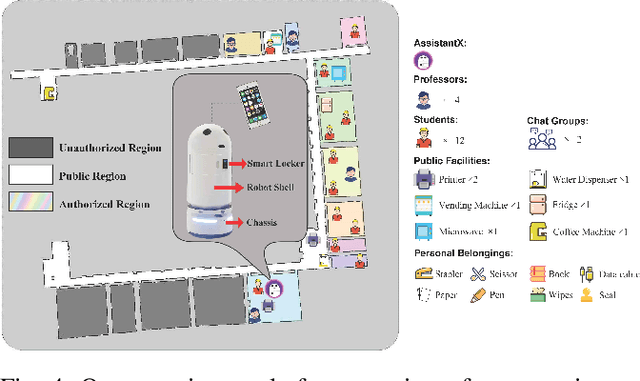
The increasing demand for intelligent assistants in human-populated environments has motivated significant research in autonomous robotic systems. Traditional service robots and virtual assistants, however, struggle with real-world task execution due to their limited capacity for dynamic reasoning and interaction, particularly when human collaboration is required. Recent developments in Large Language Models have opened new avenues for improving these systems, enabling more sophisticated reasoning and natural interaction capabilities. In this paper, we introduce AssistantX, an LLM-powered proactive assistant designed to operate autonomously in a physical office environment. Unlike conventional service robots, AssistantX leverages a novel multi-agent architecture, PPDR4X, which provides advanced inference capabilities and comprehensive collaboration awareness. By effectively bridging the gap between virtual operations and physical interactions, AssistantX demonstrates robust performance in managing complex real-world scenarios. Our evaluation highlights the architecture's effectiveness, showing that AssistantX can respond to clear instructions, actively retrieve supplementary information from memory, and proactively seek collaboration from team members to ensure successful task completion. More details and videos can be found at https://assistantx-agent.github.io/AssistantX/.
Automated Detecting and Placing Road Objects from Street-level Images
Sep 17, 2019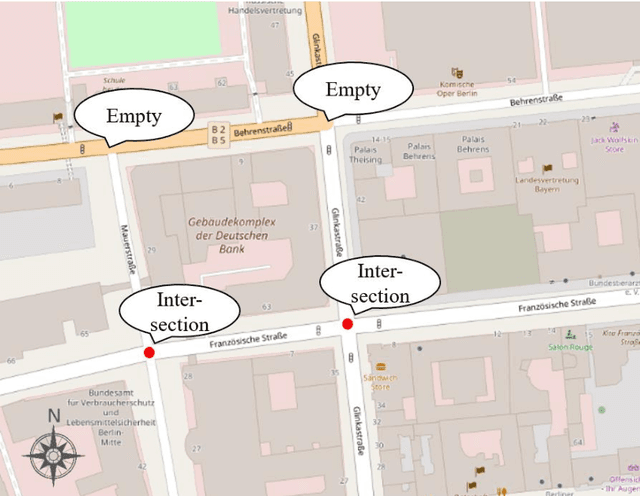

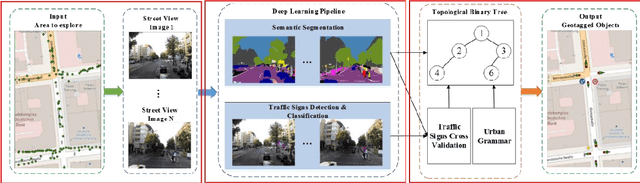

Navigation services utilized by autonomous vehicles or ordinary users require the availability of detailed information about road-related objects and their geolocations, especially at road intersections. However, these road intersections are mainly represented as point elements without detailed information, or are even not available in current versions of crowdsourced mapping databases including OpenStreetMap(OSM). This study develops an approach to automatically detect road objects and place them to right location from street-level images. Our processing pipeline relies on two convolutional neural networks: the first segments the images, while the second detects and classifies the specific objects. Moreover, to locate the detected objects, we establish an attributed topological binary tree(ATBT) based on urban grammar for each image to depict the coherent relations of topologies, attributes and semantics of the road objects. Then the ATBT is further matched with map features on OSM to determine the right placed location. The proposed method has been applied to a case study in Berlin, Germany. We validate the effectiveness of our method on two object classes: traffic signs and traffic lights. Experimental results demonstrate that the proposed approach provides near-precise localization results in terms of completeness and positional accuracy. Among many potential applications, the output may be combined with other sources of data to guide autonomous vehicles