 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Cross Domain Acoustic-to-articulatory Inverted Features For Disordered Speech Recognition
Paper and Code
Mar 19, 2022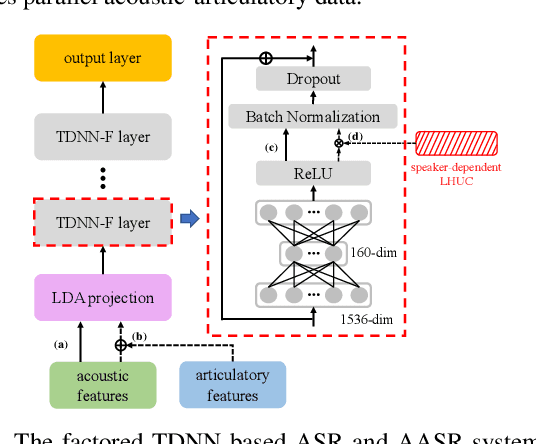
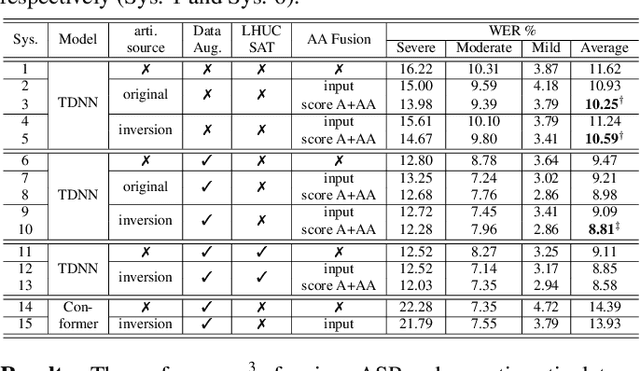
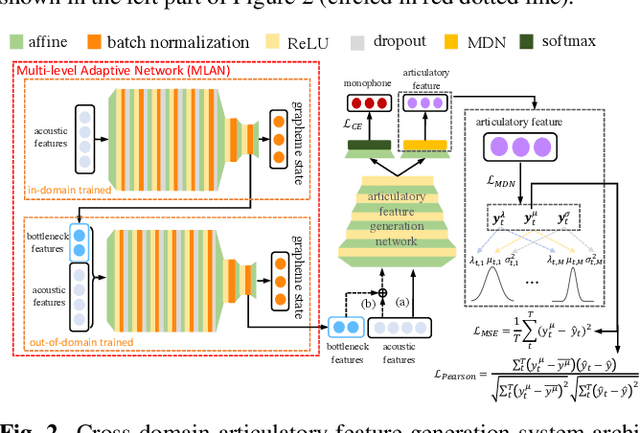
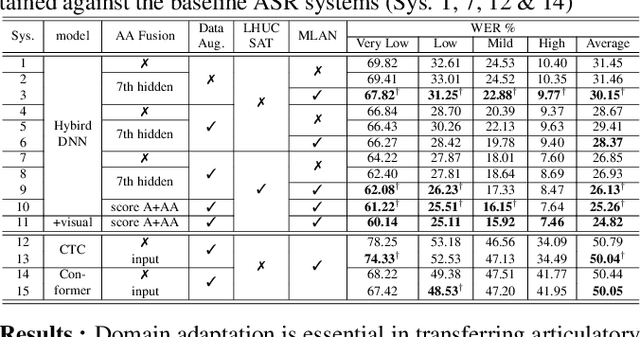
Articulatory features are inherently invariant to acoustic signal distortion and have been successfully incorporated into automatic speech recognition (ASR) systems for normal speech. Their practical application to disordered speech recognition is often limited by the difficulty in collecting such specialist data from impaired speakers. This paper presents a cross-domain acoustic-to-articulatory (A2A) inversion approach that utilizes the parallel acoustic-articulatory data of the 15-hour TORGO corpus in model training before being cross-domain adapted to the 102.7-hour UASpeech corpus and to produce articulatory features. Mixture density networks based neural A2A inversion models were used. A cross-domain feature adaptation network was also used to reduce the acoustic mismatch between the TORGO and UASpeech data. On both tasks, incorporating the A2A generated articulatory features consistently outperformed the baseline hybrid DNN/TDNN, CTC and Conformer based end-to-end systems constructed using acoustic features only. The best multi-modal system incorporating video modality and the cross-domain articulatory features as well as data augmentation and learning hidden unit contributions (LHUC) speaker adaptation produced the lowest published word error rate (WER) of 24.82% on the 16 dysarthric speakers of the benchmark UASpeech task.