 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Progress in the CUHK Dysarthric Speech Recognition System
Paper and Code
Jan 15, 2022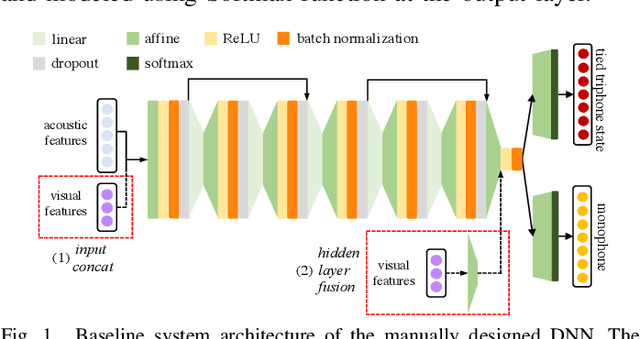
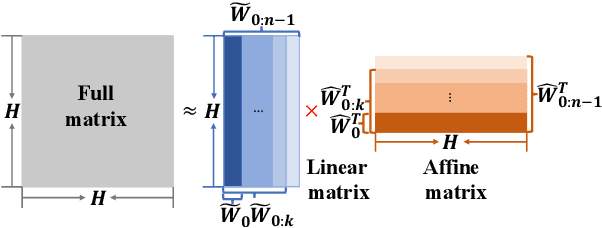
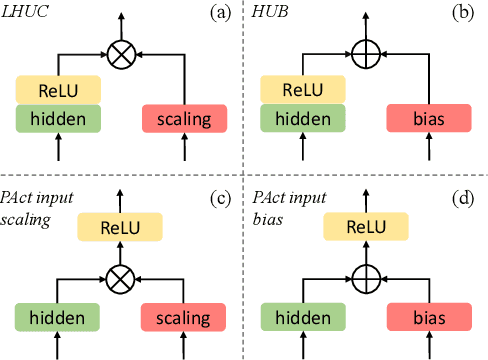
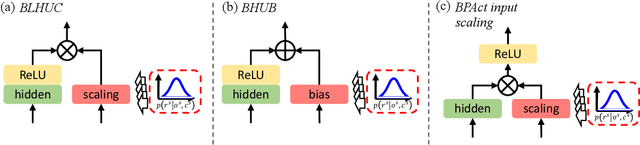
Despite the rapid progress of automatic speech recognition (ASR) technologies in the past few decades, recognition of disordered speech remains a highly challenging task to date. Disordered speech presents a wide spectrum of challenges to current data intensive deep neural networks (DNNs) based ASR technologies that predominantly target normal speech. This paper presents recent research efforts at the Chinese University of Hong Kong (CUHK) to improve the performance of disordered speech recognition systems on the largest publicly available UASpeech dysarthric speech corpus. A set of novel modelling techniques including neural architectural search, data augmentation using spectra-temporal perturbation, model based speaker adaptation and cross-domain generation of visual features within an audio-visual speech recognition (AVSR) system framework were employed to address the above challenges. The combination of these techniques produced the lowest published word error rate (WER) of 25.21% on the UASpeech test set 16 dysarthric speakers, and an overall WER reduction of 5.4% absolute (17.6% relative) over the CUHK 2018 dysarthric speech recognition system featuring a 6-way DNN system combination and cross adaptation of out-of-domain normal speech data trained systems. Bayesian model adaptation further allows rapid adaptation to individual dysarthric speakers to be performed using as little as 3.06 seconds of speech. The efficacy of these techniques were further demonstrated on a CUDYS Cantonese dysarthric speech recognition task.