 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagGPT: Large Language Models are Zero-shot Multimodal Taggers
Apr 06, 2023


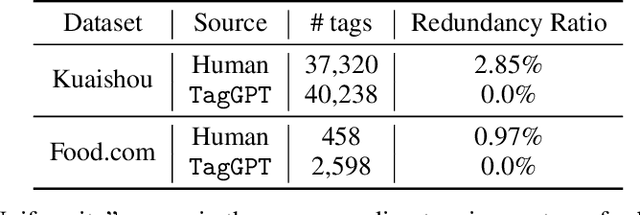
Tags are pivotal in facilitating the effective distribution of multimedia content in various applications in the contemporary Internet era, such as search engines and recommendation systems. Recently, large language models (LLMs) have demonstrated impressive capabilities across a wide range of tasks. In this work, we propose TagGPT, a fully automated system capable of tag extraction and multimodal tagging in a completely zero-shot fashion. Our core insight is that, through elaborate prompt engineering, LLMs are able to extract and reason about proper tags given textual clues of multimodal data, e.g., OCR, ASR, title, etc. Specifically, to automatically build a high-quality tag set that reflects user intent and interests for a specific application, TagGPT predicts large-scale candidate tags from a series of raw data via prompting LLMs, filtered with frequency and semantics. Given a new entity that needs tagging for distribution, TagGPT introduces two alternative options for zero-shot tagging, i.e., a generative method with late semantic matching with the tag set, and another selective method with early matching in prompts. It is well noticed that TagGPT provides a system-level solution based on a modular framework equipped with a pre-trained LLM (GPT-3.5 used here) and a sentence embedding model (SimCSE used here), which can be seamlessly replaced with any more advanced one you want. TagGPT is applicable for various modalities of data in modern social media and showcases strong generalization ability to a wide range of applications. We evaluate TagGPT on publicly available datasets, i.e., Kuaishou and Food.com, and demonstrate the effectiveness of TagGPT compared to existing hashtags and off-the-shelf taggers. Project page: https://github.com/TencentARC/TagGPT.