 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-pretrained Deep Neural Network
Jun 02, 2016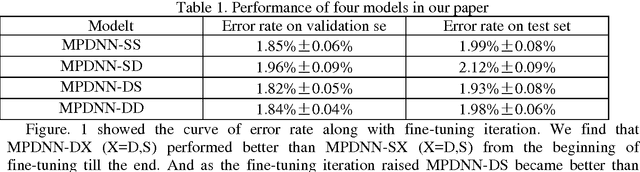

Pretraining is widely used in deep neutral network and one of the most famous pretraining models is Deep Belief Network (DBN). The optimization formulas are different during the pretraining process for different pretraining models. In this paper, we pretrained deep neutral network by different pretraining models and hence investigated the difference between DBN and Stacked Denoising Autoencoder (SDA) when used as pretraining model. The experimental results show that DBN get a better initial model. However the model converges to a relatively worse model after the finetuning process. Yet after pretrained by SDA for the second time the model converges to a better model if finetuned.
On the Complexity of One-class SVM for Multiple Instance Learning
Mar 16, 2016
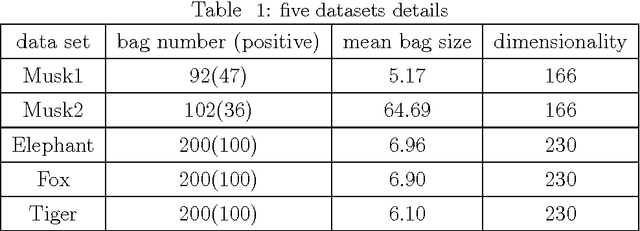
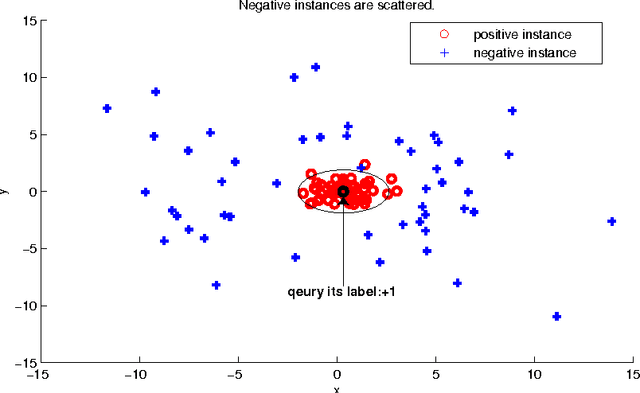
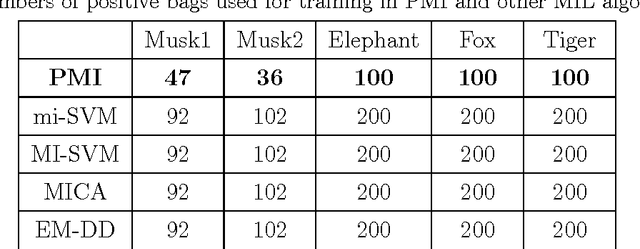
In traditional multiple instance learning (MIL), both positive and negative bags are required to learn a prediction function. However, a high human cost is needed to know the label of each bag---positive or negative. Only positive bags contain our focus (positive instances) while negative bags consist of noise or background (negative instances). So we do not expect to spend too much to label the negative bags. Contrary to our expectation, nearly all existing MIL methods require enough negative bags besides positive ones. In this paper we propose an algorithm called "Positive Multiple Instance" (PMI), which learns a classifier given only a set of positive bags. So the annotation of negative bags becomes unnecessary in our method. PMI is constructed based on the assumption that the unknown positive instances in positive bags be similar each other and constitute one compact cluster in feature space and the negative instances locate outside this cluster. The experimental results demonstrate that PMI achieves the performances close to or a little worse than those of the traditional MIL algorithms on benchmark and real data sets. However, the number of training bags in PMI is reduced significantly compared with traditional MIL algorithms.