Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-pretrained Deep Neural Network
Paper and Code
Jun 02, 2016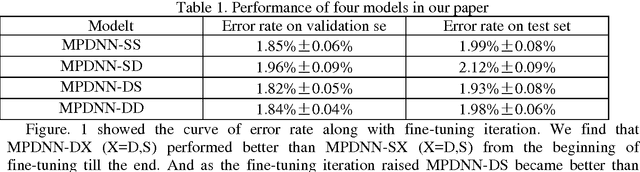

Pretraining is widely used in deep neutral network and one of the most famous pretraining models is Deep Belief Network (DBN). The optimization formulas are different during the pretraining process for different pretraining models. In this paper, we pretrained deep neutral network by different pretraining models and hence investigated the difference between DBN and Stacked Denoising Autoencoder (SDA) when used as pretraining model. The experimental results show that DBN get a better initial model. However the model converges to a relatively worse model after the finetuning process. Yet after pretrained by SDA for the second time the model converges to a better model if finetuned.
View paper on