 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiVA: Gradient-Informed Bases for Vector-Based Adaptation
Apr 23, 2026As model sizes continue to grow, parameter-efficient fine-tuning has emerged as a powerful alternative to full fine-tuning. While LoRA is widely adopted among these methods, recent research has explored vector-based adaptation methods due to their extreme parameter efficiency. However, these methods typically require substantially higher ranks than LoRA to match its performance, leading to increased training costs. This work introduces GiVA, a gradient-based initialization strategy for vector-based adaptation. It achieves training times comparable to LoRA and maintains the extreme parameter efficiency of vector-based adaptation. We evaluate GiVA across diverse benchmarks, including natural language understanding, natural language generation, and image classification. Experiments show that our approach consistently outperforms or achieves performance competitive with existing vector-based adaptation methods and LoRA while reducing rank requirements by a factor of eight ($8\times$).
Towards Robustness Analysis of E-Commerce Ranking System
Mar 07, 2024


Information retrieval (IR) is a pivotal component in various applications. Recent advances in machine learning (ML) have enabled the integration of ML algorithms into IR, particularly in ranking systems. While there is a plethora of research on the robustness of ML-based ranking systems, these studies largely neglect commercial e-commerce systems and fail to establish a connection between real-world and manipulated query relevance. In this paper, we present the first systematic measurement study on the robustness of e-commerce ranking systems. We define robustness as the consistency of ranking outcomes for semantically identical queries. To quantitatively analyze robustness, we propose a novel metric that considers both ranking position and item-specific information that are absent in existing metrics. Our large-scale measurement study with real-world data from e-commerce retailers reveals an open opportunity to measure and improve robustness since semantically identical queries often yield inconsistent ranking results. Based on our observations, we propose several solution directions to enhance robustness, such as the use of Large Language Models. Note that the issue of robustness discussed herein does not constitute an error or oversight. Rather, in scenarios where there exists a vast array of choices, it is feasible to present a multitude of products in various permutations, all of which could be equally appealing. However, this extensive selection may lead to customer confusion. As e-commerce retailers use various techniques to improve the quality of search results, we hope that this research offers valuable guidance for measuring the robustness of the ranking systems.
Towards Scalability and Extensibility of Query Reformulation Modeling in E-commerce Search
Feb 17, 2024



Customer behavioral data significantly impacts e-commerce search systems. However, in the case of less common queries, the associated behavioral data tends to be sparse and noisy, offering inadequate support to the search mechanism. To address this challenge, the concept of query reformulation has been introduced. It suggests that less common queries could utilize the behavior patterns of their popular counterparts with similar meanings. In Amazon product search, query reformulation has displayed its effectiveness in improving search relevance and bolstering overall revenue. Nonetheless, adapting this method for smaller or emerging businesses operating in regions with lower traffic and complex multilingual settings poses the challenge in terms of scalability and extensibility. This study focuses on overcoming this challenge by constructing a query reformulation solution capable of functioning effectively, even when faced with limited training data, in terms of quality and scale, along with relatively complex linguistic characteristics. In this paper we provide an overview of the solution implemented within Amazon product search infrastructure, which encompasses a range of elements, including refining the data mining process, redefining model training objectives, and reshaping training strategies. The effectiveness of the proposed solution is validated through online A/B testing on search ranking and Ads matching. Notably, employing the proposed solution in search ranking resulted in 0.14% and 0.29% increase in overall revenue in Japanese and Hindi cases, respectively, and a 0.08\% incremental gain in the English case compared to the legacy implementation; while in search Ads matching led to a 0.36% increase in Ads revenue in the Japanese case.
AttnGrounder: Talking to Cars with Attention
Sep 11, 2020
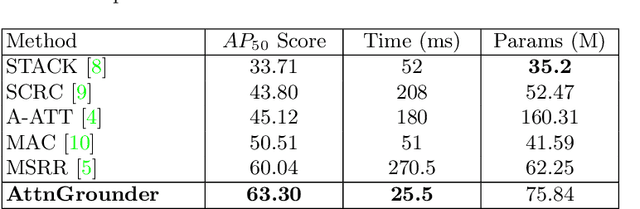
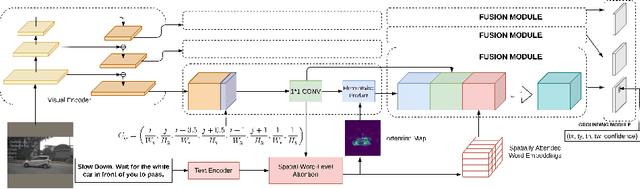

We propose Attention Grounder (AttnGrounder), a single-stage end-to-end trainable model for the task of visual grounding. Visual grounding aims to localize a specific object in an image based on a given natural language text query. Unlike previous methods that use the same text representation for every image region, we use a visual-text attention module that relates each word in the given query with every region in the corresponding image for constructing a region dependent text representation. Furthermore, for improving the localization ability of our model, we use our visual-text attention module to generate an attention mask around the referred object. The attention mask is trained as an auxiliary task using a rectangular mask generated with the provided ground-truth coordinates. We evaluate AttnGrounder on the Talk2Car dataset and show an improvement of 3.26% over the existing methods.