 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttnGrounder: Talking to Cars with Attention
Paper and Code

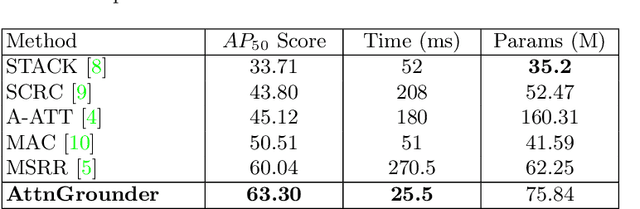
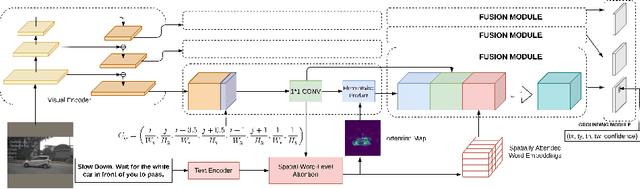

We propose Attention Grounder (AttnGrounder), a single-stage end-to-end trainable model for the task of visual grounding. Visual grounding aims to localize a specific object in an image based on a given natural language text query. Unlike previous methods that use the same text representation for every image region, we use a visual-text attention module that relates each word in the given query with every region in the corresponding image for constructing a region dependent text representation. Furthermore, for improving the localization ability of our model, we use our visual-text attention module to generate an attention mask around the referred object. The attention mask is trained as an auxiliary task using a rectangular mask generated with the provided ground-truth coordinates. We evaluate AttnGrounder on the Talk2Car dataset and show an improvement of 3.26% over the existing methods.