 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World 3D Scene Graph Generation for Retrieval-Augmented Reasoning
Nov 08, 2025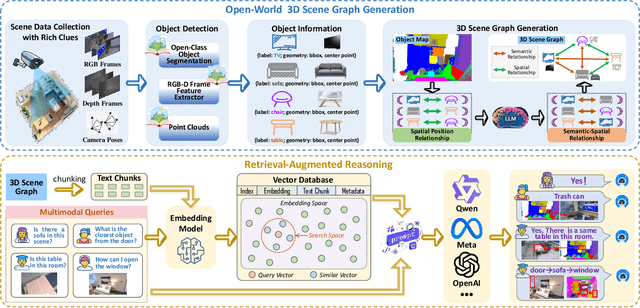

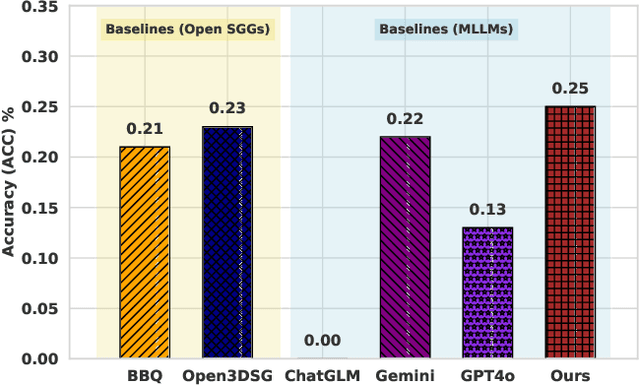
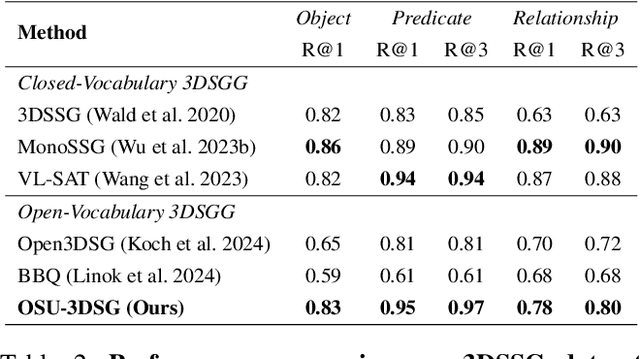
Understanding 3D scenes in open-world settings poses fundamental challenges for vision and robotics, particularly due to the limitations of closed-vocabulary supervision and static annotations. To address this, we propose a unified framework for Open-World 3D Scene Graph Generation with Retrieval-Augmented Reasoning, which enables generalizable and interactive 3D scene understanding. Our method integrates Vision-Language Models (VLMs) with retrieval-based reasoning to support multimodal exploration and language-guided interaction. The framework comprises two key components: (1) a dynamic scene graph generation module that detects objects and infers semantic relationships without fixed label sets, and (2) a retrieval-augmented reasoning pipeline that encodes scene graphs into a vector database to support text/image-conditioned queries. We evaluate our method on 3DSSG and Replica benchmarks across four tasks-scene question answering, visual grounding, instance retrieval, and task planning-demonstrating robust generalization and superior performance in diverse environments. Our results highlight the effectiveness of combining open-vocabulary perception with retrieval-based reasoning for scalable 3D scene understanding.
Scene Understanding Enabled Semantic Communication with Open Channel Coding
Jan 24, 2025



As communication systems transition from symbol transmission to conveying meaningful information, sixth-generation (6G) networks emphasize semantic communication. This approach prioritizes high-level semantic information, improving robustness and reducing redundancy across modalities like text, speech, and images. However, traditional semantic communication faces limitations, including static coding strategies, poor generalization, and reliance on task-specific knowledge bases that hinder adaptability. To overcome these challenges, we propose a novel system combining scene understanding, Large Language Models (LLMs), and open channel coding, named \textbf{OpenSC}. Traditional systems rely on fixed domain-specific knowledge bases, limiting their ability to generalize. Our open channel coding approach leverages shared, publicly available knowledge, enabling flexible, adaptive encoding. This dynamic system reduces reliance on static task-specific data, enhancing adaptability across diverse tasks and environments. Additionally, we use scene graphs for structured semantic encoding, capturing object relationships and context to improve tasks like Visual Question Answering (VQA). Our approach selectively encodes key semantic elements, minimizing redundancy and improving transmission efficiency. Experimental results show significant improvements in both semantic understanding and efficiency, advancing the potential of adaptive, generalizable semantic communication in 6G networks.
Enhanced Multimodal RAG-LLM for Accurate Visual Question Answering
Dec 30, 2024



Multimodal large language models (MLLMs), such as GPT-4o, Gemini, LLaVA, and Flamingo, have made significant progress in integrating visual and textual modalities, excelling in tasks like visual question answering (VQA), image captioning, and content retrieval. They can generate coherent and contextually relevant descriptions of images. However, they still face challenges in accurately identifying and counting objects and determining their spatial locations, particularly in complex scenes with overlapping or small objects. To address these limitations, we propose a novel framework based on multimodal retrieval-augmented generation (RAG), which introduces structured scene graphs to enhance object recognition, relationship identification, and spatial understanding within images. Our framework improves the MLLM's capacity to handle tasks requiring precise visual descriptions, especially in scenarios with challenging perspectives, such as aerial views or scenes with dense object arrangements. Finally, we conduct extensive experiments on the VG-150 dataset that focuses on first-person visual understanding and the AUG dataset that involves aerial imagery. The results show that our approach consistently outperforms existing MLLMs in VQA tasks, which stands out in recognizing, localizing, and quantifying objects in different spatial contexts and provides more accurate visual descriptions.
Towards Scalability and Extensibility of Query Reformulation Modeling in E-commerce Search
Feb 17, 2024



Customer behavioral data significantly impacts e-commerce search systems. However, in the case of less common queries, the associated behavioral data tends to be sparse and noisy, offering inadequate support to the search mechanism. To address this challenge, the concept of query reformulation has been introduced. It suggests that less common queries could utilize the behavior patterns of their popular counterparts with similar meanings. In Amazon product search, query reformulation has displayed its effectiveness in improving search relevance and bolstering overall revenue. Nonetheless, adapting this method for smaller or emerging businesses operating in regions with lower traffic and complex multilingual settings poses the challenge in terms of scalability and extensibility. This study focuses on overcoming this challenge by constructing a query reformulation solution capable of functioning effectively, even when faced with limited training data, in terms of quality and scale, along with relatively complex linguistic characteristics. In this paper we provide an overview of the solution implemented within Amazon product search infrastructure, which encompasses a range of elements, including refining the data mining process, redefining model training objectives, and reshaping training strategies. The effectiveness of the proposed solution is validated through online A/B testing on search ranking and Ads matching. Notably, employing the proposed solution in search ranking resulted in 0.14% and 0.29% increase in overall revenue in Japanese and Hindi cases, respectively, and a 0.08\% incremental gain in the English case compared to the legacy implementation; while in search Ads matching led to a 0.36% increase in Ads revenue in the Japanese case.