 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Understanding Enabled Semantic Communication with Open Channel Coding
Jan 24, 2025



As communication systems transition from symbol transmission to conveying meaningful information, sixth-generation (6G) networks emphasize semantic communication. This approach prioritizes high-level semantic information, improving robustness and reducing redundancy across modalities like text, speech, and images. However, traditional semantic communication faces limitations, including static coding strategies, poor generalization, and reliance on task-specific knowledge bases that hinder adaptability. To overcome these challenges, we propose a novel system combining scene understanding, Large Language Models (LLMs), and open channel coding, named \textbf{OpenSC}. Traditional systems rely on fixed domain-specific knowledge bases, limiting their ability to generalize. Our open channel coding approach leverages shared, publicly available knowledge, enabling flexible, adaptive encoding. This dynamic system reduces reliance on static task-specific data, enhancing adaptability across diverse tasks and environments. Additionally, we use scene graphs for structured semantic encoding, capturing object relationships and context to improve tasks like Visual Question Answering (VQA). Our approach selectively encodes key semantic elements, minimizing redundancy and improving transmission efficiency. Experimental results show significant improvements in both semantic understanding and efficiency, advancing the potential of adaptive, generalizable semantic communication in 6G networks.
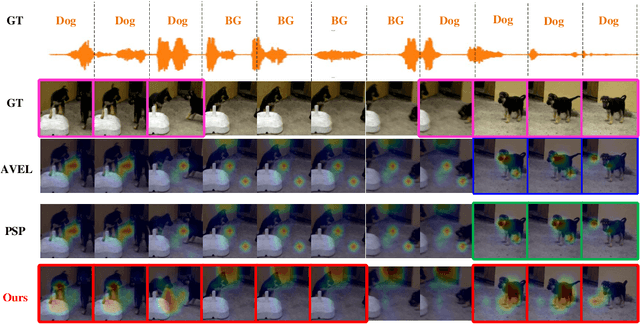
Pilot-guided Multimodal Semantic Communication for Audio-Visual Event Localization
Dec 09, 2024



Multimodal semantic communication, which integrates various data modalities such as text, images, and audio, significantly enhances communication efficiency and reliability. It has broad application prospects in fields such as artificial intelligence, autonomous driving, and smart homes. However, current research primarily relies on analog channels and assumes constant channel states (perfect CSI), which is inadequate for addressing dynamic physical channels and noise in real-world scenarios. Existing methods often focus on single modality tasks and fail to handle multimodal stream data, such as video and audio, and their corresponding tasks. Furthermore, current semantic encoding and decoding modules mainly transmit single modality features, neglecting the need for multimodal semantic enhancement and recognition tasks. To address these challenges, this paper proposes a pilot-guided framework for multimodal semantic communication specifically tailored for audio-visual event localization tasks. This framework utilizes digital pilot codes and channel modules to guide the state of analog channels in real-wold scenarios and designs Euler-based multimodal semantic encoding and decoding that consider time-frequency characteristics based on dynamic channel state. This approach effectively handles multimodal stream source data, especially for audio-visual event localization tasks. Extensive numerical experiments demonstrate the robustness of the proposed framework in channel changes and its support for various communication scenarios. The experimental results show that the framework outperforms existing benchmark methods in terms of Signal-to-Noise Ratio (SNR), highlighting its advantage in semantic communication quality.
Multimodal Trustworthy Semantic Communication for Audio-Visual Event Localization
Nov 04, 2024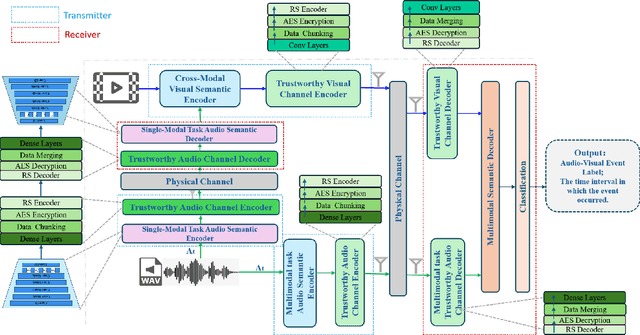
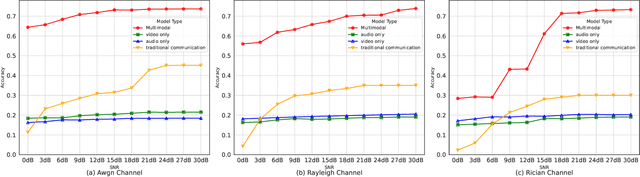

The exponential growth in wireless data traffic, driven by the proliferation of mobile devices and smart applications, poses significant challenges for modern communication systems. Ensuring the secure and reliable transmission of multimodal semantic information is increasingly critical, particularly for tasks like Audio-Visual Event (AVE) localization. This letter introduces MMTrustSC, a novel framework designed to address these challenges by enhancing the security and reliability of multimodal communication. MMTrustSC incorporates advanced semantic encoding techniques to safeguard data integrity and privacy. It features a two-level coding scheme that combines error-correcting codes with conventional encoders to improve the accuracy and reliability of multimodal data transmission. Additionally, MMTrustSC employs hybrid encryption, integrating both asymmetric and symmetric encryption methods, to secure semantic information and ensure its confidentiality and integrity across potentially hostile networks. Simulation results validate MMTrustSC's effectiveness, demonstrating substantial improvements in data transmission accuracy and reliability for AVE localization tasks. This framework represents a significant advancement in managing intermodal information complementarity and mitigating physical noise, thus enhancing overall system performance.