 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Understanding Enabled Semantic Communication with Open Channel Coding
Jan 24, 2025



As communication systems transition from symbol transmission to conveying meaningful information, sixth-generation (6G) networks emphasize semantic communication. This approach prioritizes high-level semantic information, improving robustness and reducing redundancy across modalities like text, speech, and images. However, traditional semantic communication faces limitations, including static coding strategies, poor generalization, and reliance on task-specific knowledge bases that hinder adaptability. To overcome these challenges, we propose a novel system combining scene understanding, Large Language Models (LLMs), and open channel coding, named \textbf{OpenSC}. Traditional systems rely on fixed domain-specific knowledge bases, limiting their ability to generalize. Our open channel coding approach leverages shared, publicly available knowledge, enabling flexible, adaptive encoding. This dynamic system reduces reliance on static task-specific data, enhancing adaptability across diverse tasks and environments. Additionally, we use scene graphs for structured semantic encoding, capturing object relationships and context to improve tasks like Visual Question Answering (VQA). Our approach selectively encodes key semantic elements, minimizing redundancy and improving transmission efficiency. Experimental results show significant improvements in both semantic understanding and efficiency, advancing the potential of adaptive, generalizable semantic communication in 6G networks.
Pilot-guided Multimodal Semantic Communication for Audio-Visual Event Localization
Dec 09, 2024



Multimodal semantic communication, which integrates various data modalities such as text, images, and audio, significantly enhances communication efficiency and reliability. It has broad application prospects in fields such as artificial intelligence, autonomous driving, and smart homes. However, current research primarily relies on analog channels and assumes constant channel states (perfect CSI), which is inadequate for addressing dynamic physical channels and noise in real-world scenarios. Existing methods often focus on single modality tasks and fail to handle multimodal stream data, such as video and audio, and their corresponding tasks. Furthermore, current semantic encoding and decoding modules mainly transmit single modality features, neglecting the need for multimodal semantic enhancement and recognition tasks. To address these challenges, this paper proposes a pilot-guided framework for multimodal semantic communication specifically tailored for audio-visual event localization tasks. This framework utilizes digital pilot codes and channel modules to guide the state of analog channels in real-wold scenarios and designs Euler-based multimodal semantic encoding and decoding that consider time-frequency characteristics based on dynamic channel state. This approach effectively handles multimodal stream source data, especially for audio-visual event localization tasks. Extensive numerical experiments demonstrate the robustness of the proposed framework in channel changes and its support for various communication scenarios. The experimental results show that the framework outperforms existing benchmark methods in terms of Signal-to-Noise Ratio (SNR), highlighting its advantage in semantic communication quality.
Multimodal Trustworthy Semantic Communication for Audio-Visual Event Localization
Nov 04, 2024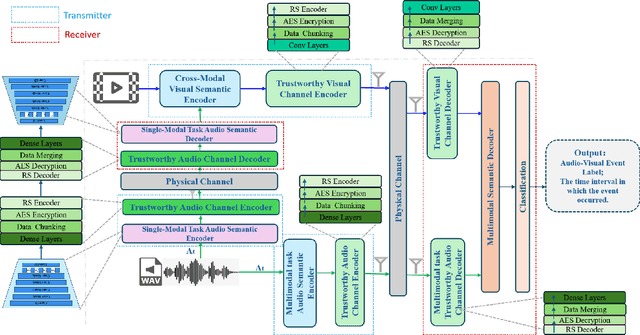
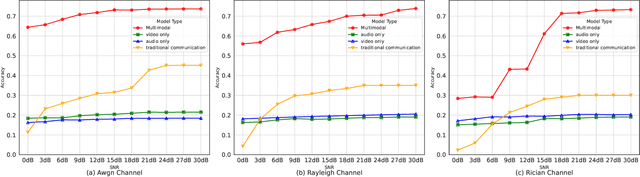
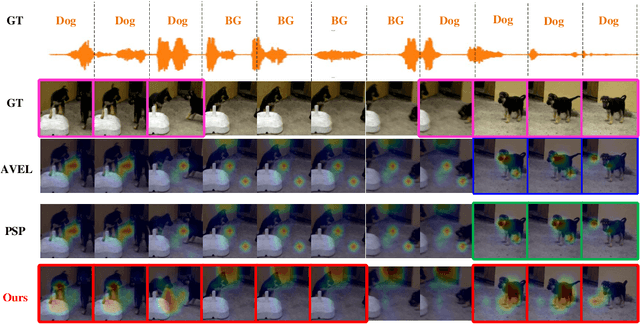

The exponential growth in wireless data traffic, driven by the proliferation of mobile devices and smart applications, poses significant challenges for modern communication systems. Ensuring the secure and reliable transmission of multimodal semantic information is increasingly critical, particularly for tasks like Audio-Visual Event (AVE) localization. This letter introduces MMTrustSC, a novel framework designed to address these challenges by enhancing the security and reliability of multimodal communication. MMTrustSC incorporates advanced semantic encoding techniques to safeguard data integrity and privacy. It features a two-level coding scheme that combines error-correcting codes with conventional encoders to improve the accuracy and reliability of multimodal data transmission. Additionally, MMTrustSC employs hybrid encryption, integrating both asymmetric and symmetric encryption methods, to secure semantic information and ensure its confidentiality and integrity across potentially hostile networks. Simulation results validate MMTrustSC's effectiveness, demonstrating substantial improvements in data transmission accuracy and reliability for AVE localization tasks. This framework represents a significant advancement in managing intermodal information complementarity and mitigating physical noise, thus enhancing overall system performance.
CVLUE: A New Benchmark Dataset for Chinese Vision-Language Understanding Evaluation
Jul 01, 2024



Despite the rapid development of Chinese vision-language models (VLMs), most existing Chinese vision-language (VL) datasets are constructed on Western-centric images from existing English VL datasets. The cultural bias in the images makes these datasets unsuitable for evaluating VLMs in Chinese culture. To remedy this issue, we present a new Chinese Vision- Language Understanding Evaluation (CVLUE) benchmark dataset, where the selection of object categories and images is entirely driven by Chinese native speakers, ensuring that the source images are representative of Chinese culture. The benchmark contains four distinct VL tasks ranging from image-text retrieval to visual question answering, visual grounding and visual dialogue. We present a detailed statistical analysis of CVLUE and provide a baseline performance analysis with several open-source multilingual VLMs on CVLUE and its English counterparts to reveal their performance gap between English and Chinese. Our in-depth category-level analysis reveals a lack of Chinese cultural knowledge in existing VLMs. We also find that fine-tuning on Chinese culture-related VL datasets effectively enhances VLMs' understanding of Chinese culture.
A Huber Loss Minimization Approach to Byzantine Robust Federated Learning
Aug 24, 2023



Federated learning systems are susceptible to adversarial attacks. To combat this, we introduce a novel aggregator based on Huber loss minimization, and provide a comprehensive theoretical analysis. Under independent and identically distributed (i.i.d) assumption, our approach has several advantages compared to existing methods. Firstly, it has optimal dependence on $\epsilon$, which stands for the ratio of attacked clients. Secondly, our approach does not need precise knowledge of $\epsilon$. Thirdly, it allows different clients to have unequal data sizes. We then broaden our analysis to include non-i.i.d data, such that clients have slightly different distributions.
High Dimensional Distributed Gradient Descent with Arbitrary Number of Byzantine Attackers
Jul 25, 2023


Robust distributed learning with Byzantine failures has attracted extensive research interests in recent years. However, most of existing methods suffer from curse of dimensionality, which is increasingly serious with the growing complexity of modern machine learning models. In this paper, we design a new method that is suitable for high dimensional problems, under arbitrary number of Byzantine attackers. The core of our design is a direct high dimensional semi-verified mean estimation method. Our idea is to identify a subspace first. The components of mean value perpendicular to this subspace can be estimated via gradient vectors uploaded from worker machines, while the components within this subspace are estimated using auxiliary dataset. We then use our new method as the aggregator of distributed learning problems. Our theoretical analysis shows that the new method has minimax optimal statistical rates. In particular, the dependence on dimensionality is significantly improved compared with previous works.
Robust Nonparametric Regression under Poisoning Attack
May 26, 2023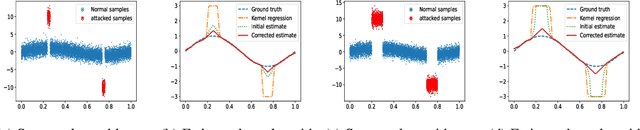
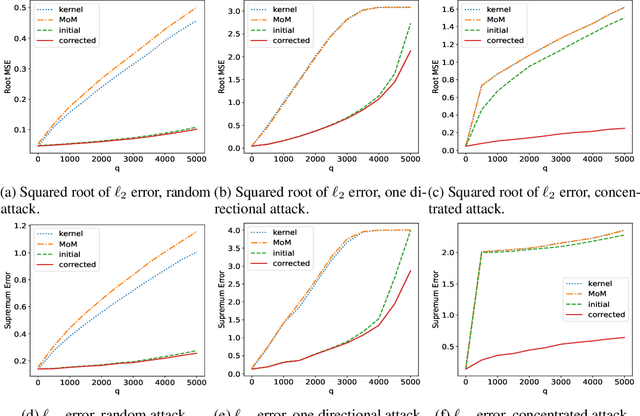
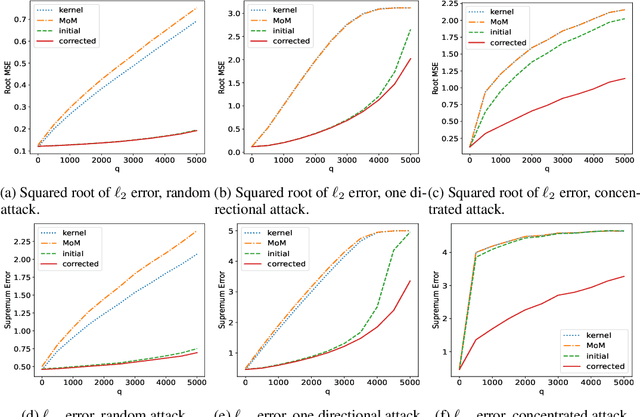
This paper studies robust nonparametric regression, in which an adversarial attacker can modify the values of up to $q$ samples from a training dataset of size $N$. Our initial solution is an M-estimator based on Huber loss minimization. Compared with simple kernel regression, i.e. the Nadaraya-Watson estimator, this method can significantly weaken the impact of malicious samples on the regression performance. We provide the convergence rate as well as the corresponding minimax lower bound. The result shows that, with proper bandwidth selection, $\ell_\infty$ error is minimax optimal. The $\ell_2$ error is optimal if $q\lesssim \sqrt{N/\ln^2 N}$, but is suboptimal with larger $q$. The reason is that this estimator is vulnerable if there are many attacked samples concentrating in a small region. To address this issue, we propose a correction method by projecting the initial estimate to the space of Lipschitz functions. The final estimate is nearly minimax optimal for arbitrary $q$, up to a $\ln N$ factor.
Intelligent Computing: The Latest Advances, Challenges and Future
Nov 21, 2022Computing is a critical driving force in the development of human civilization. In recent years, we have witnessed the emergence of intelligent computing, a new computing paradigm that is reshaping traditional computing and promoting digital revolution in the era of big data, artificial intelligence and internet-of-things with new computing theories, architectures, methods, systems, and applications. Intelligent computing has greatly broadened the scope of computing, extending it from traditional computing on data to increasingly diverse computing paradigms such as perceptual intelligence, cognitive intelligence, autonomous intelligence, and human-computer fusion intelligence. Intelligence and computing have undergone paths of different evolution and development for a long time but have become increasingly intertwined in recent years: intelligent computing is not only intelligence-oriented but also intelligence-driven. Such cross-fertilization has prompted the emergence and rapid advancement of intelligent computing. Intelligent computing is still in its infancy and an abundance of innovations in the theories, systems, and applications of intelligent computing are expected to occur soon. We present the first comprehensive survey of literature on intelligent computing, covering its theory fundamentals, the technological fusion of intelligence and computing, important applications, challenges, and future perspectives. We believe that this survey is highly timely and will provide a comprehensive reference and cast valuable insights into intelligent computing for academic and industrial researchers and practitioners.
Memory Regulation and Alignment toward Generalizer RGB-Infrared Person
Sep 18, 2021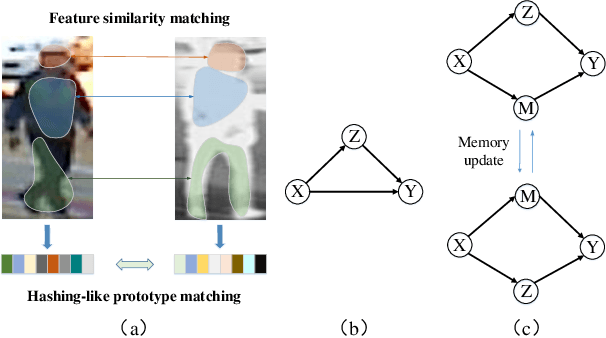
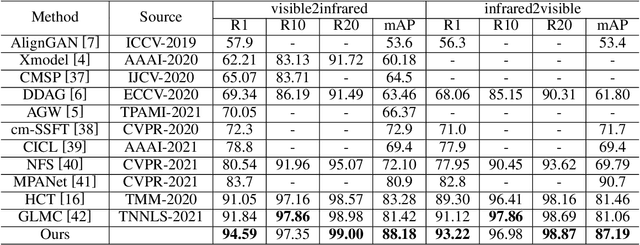
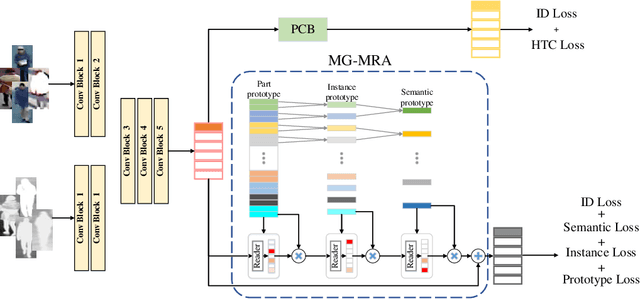
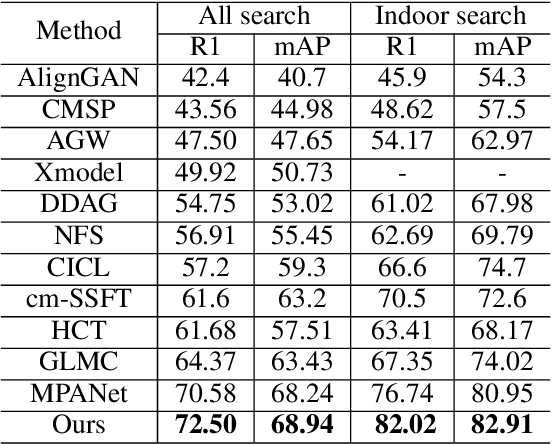
The domain shift, coming from unneglectable modality gap and non-overlapped identity classes between training and test sets, is a major issue of RGB-Infrared person re-identification. A key to tackle the inherent issue -- domain shift -- is to enforce the data distributions of the two domains to be similar. However, RGB-IR ReID always demands discriminative features, leading to over-rely feature sensitivity of seen classes, \textit{e.g.}, via attention-based feature alignment or metric learning. Therefore, predicting the unseen query category from predefined training classes may not be accurate and leads to a sub-optimal adversarial gradient. In this paper, we uncover it in a more explainable way and propose a novel multi-granularity memory regulation and alignment module (MG-MRA) to solve this issue. By explicitly incorporating a latent variable attribute, from fine-grained to coarse semantic granularity, into intermediate features, our method could alleviate the over-confidence of the model about discriminative features of seen classes. Moreover, instead of matching discriminative features by traversing nearest neighbor, sparse attributes, \textit{i.e.}, global structural pattern, are recollected with respect to features and assigned to measure pair-wise image similarity in hashing. Extensive experiments on RegDB \cite{RegDB} and SYSU-MM01 \cite{SYSU} show the superiority of the proposed method that outperforms existing state-of-the-art methods. Our code is available in https://github.com/Chenfeng1271/MGMRA.