 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robustness Analysis of E-Commerce Ranking System
Paper and Code
Mar 07, 2024

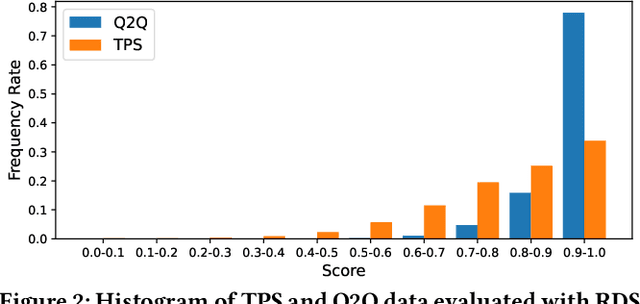

Information retrieval (IR) is a pivotal component in various applications. Recent advances in machine learning (ML) have enabled the integration of ML algorithms into IR, particularly in ranking systems. While there is a plethora of research on the robustness of ML-based ranking systems, these studies largely neglect commercial e-commerce systems and fail to establish a connection between real-world and manipulated query relevance. In this paper, we present the first systematic measurement study on the robustness of e-commerce ranking systems. We define robustness as the consistency of ranking outcomes for semantically identical queries. To quantitatively analyze robustness, we propose a novel metric that considers both ranking position and item-specific information that are absent in existing metrics. Our large-scale measurement study with real-world data from e-commerce retailers reveals an open opportunity to measure and improve robustness since semantically identical queries often yield inconsistent ranking results. Based on our observations, we propose several solution directions to enhance robustness, such as the use of Large Language Models. Note that the issue of robustness discussed herein does not constitute an error or oversight. Rather, in scenarios where there exists a vast array of choices, it is feasible to present a multitude of products in various permutations, all of which could be equally appealing. However, this extensive selection may lead to customer confusion. As e-commerce retailers use various techniques to improve the quality of search results, we hope that this research offers valuable guidance for measuring the robustness of the ranking systems.