Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERT: A New Solution to Pinyin to Character Conversion Task
Paper and Code
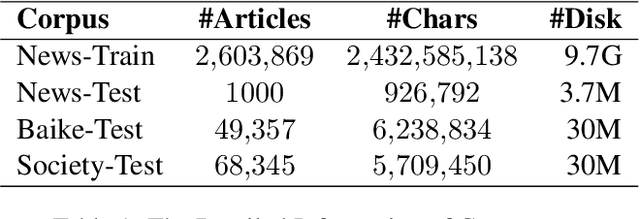
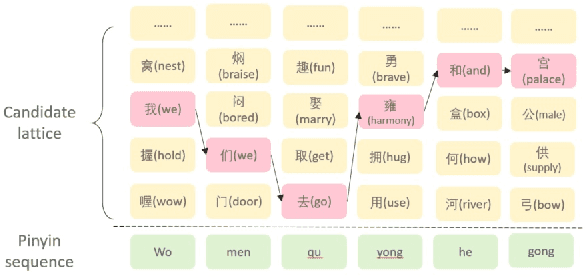
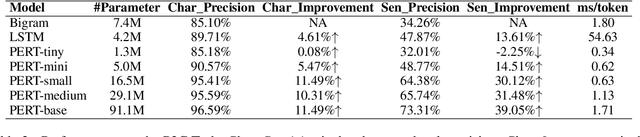
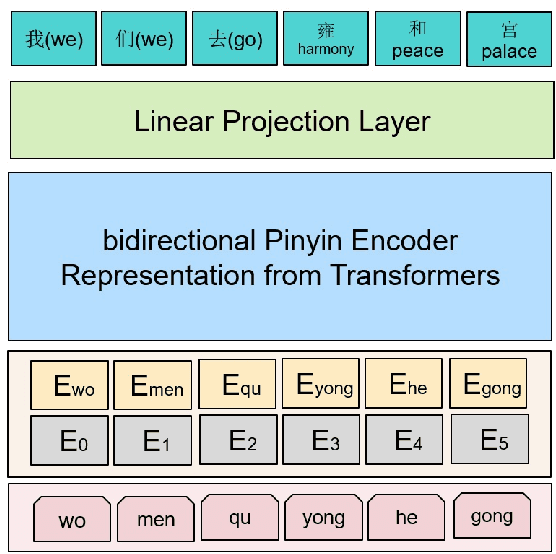
Pinyin to Character conversion (P2C) task is the key task of Input Method Engine (IME) in commercial input software for Asian languages, such as Chinese, Japanese, Thai language and so on. It's usually treated as sequence labelling task and resolved by language model, i.e. n-gram or RNN. However, the low capacity of the n-gram or RNN limits its performance. This paper introduces a new solution named PERT which stands for bidirectional Pinyin Encoder Representations from Transformers. It achieves significant improvement of performance over baselines. Furthermore, we combine PERT with n-gram under a Markov framework, and improve performance further. Lastly, the external lexicon is incorporated into PERT so as to resolve the OOD issue of IME.
View paper on