 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Pre-trained Language Models for Quantum Natural Language Processing
Feb 24, 2023



The emerging classical-quantum transfer learning paradigm has brought a decent performance to quantum computational models in many tasks, such as computer vision, by enabling a combination of quantum models and classical pre-trained neural networks. However, using quantum computing with pre-trained models has yet to be explored in natural language processing (NLP). Due to the high linearity constraints of the underlying quantum computing infrastructures, existing Quantum NLP models are limited in performance on real tasks. We fill this gap by pre-training a sentence state with complex-valued BERT-like architecture, and adapting it to the classical-quantum transfer learning scheme for sentence classification. On quantum simulation experiments, the pre-trained representation can bring 50\% to 60\% increases to the capacity of end-to-end quantum models.
UTC: A Unified Transformer with Inter-Task Contrastive Learning for Visual Dialog
May 03, 2022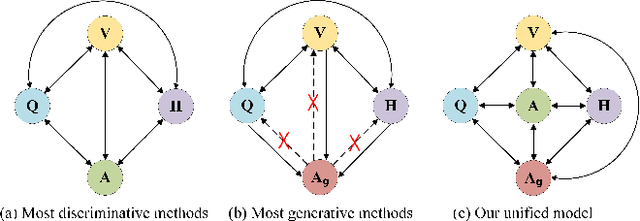
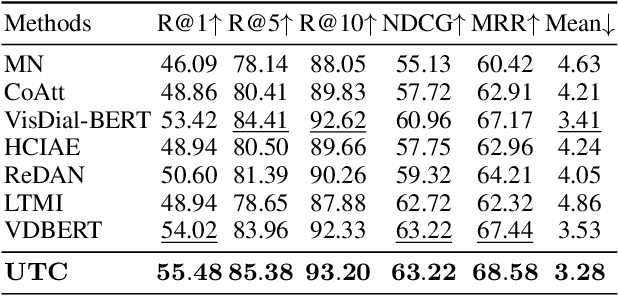
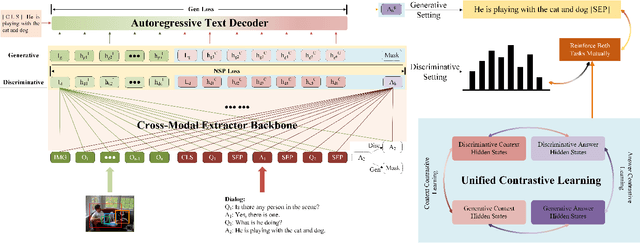
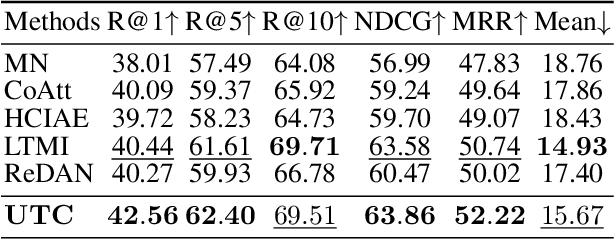
Visual Dialog aims to answer multi-round, interactive questions based on the dialog history and image content. Existing methods either consider answer ranking and generating individually or only weakly capture the relation across the two tasks implicitly by two separate models. The research on a universal framework that jointly learns to rank and generate answers in a single model is seldom explored. In this paper, we propose a contrastive learning-based framework UTC to unify and facilitate both discriminative and generative tasks in visual dialog with a single model. Specifically, considering the inherent limitation of the previous learning paradigm, we devise two inter-task contrastive losses i.e., context contrastive loss and answer contrastive loss to make the discriminative and generative tasks mutually reinforce each other. These two complementary contrastive losses exploit dialog context and target answer as anchor points to provide representation learning signals from different perspectives. We evaluate our proposed UTC on the VisDial v1.0 dataset, where our method outperforms the state-of-the-art on both discriminative and generative tasks and surpasses previous state-of-the-art generative methods by more than 2 absolute points on Recall@1.
Contrastive Learning with Positive-Negative Frame Mask for Music Representation
Apr 03, 2022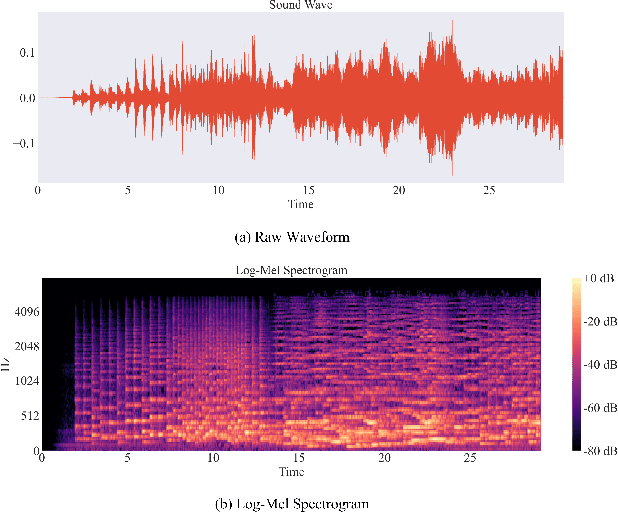
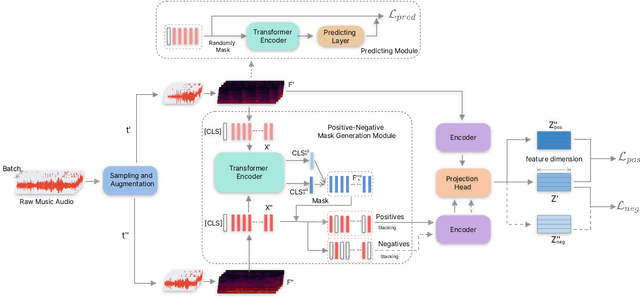
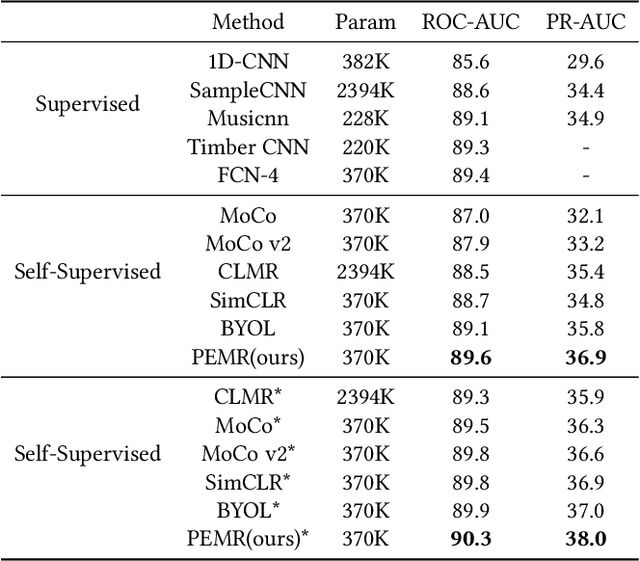
Self-supervised learning, especially contrastive learning, has made an outstanding contribution to the development of many deep learning research fields. Recently, researchers in the acoustic signal processing field noticed its success and leveraged contrastive learning for better music representation. Typically, existing approaches maximize the similarity between two distorted audio segments sampled from the same music. In other words, they ensure a semantic agreement at the music level. However, those coarse-grained methods neglect some inessential or noisy elements at the frame level, which may be detrimental to the model to learn the effective representation of music. Towards this end, this paper proposes a novel Positive-nEgative frame mask for Music Representation based on the contrastive learning framework, abbreviated as PEMR. Concretely, PEMR incorporates a Positive-Negative Mask Generation module, which leverages transformer blocks to generate frame masks on the Log-Mel spectrogram. We can generate self-augmented negative and positive samples by masking important components or inessential components, respectively. We devise a novel contrastive learning objective to accommodate both self-augmented positives/negatives sampled from the same music. We conduct experiments on four public datasets. The experimental results of two music-related downstream tasks, music classification, and cover song identification, demonstrate the generalization ability and transferability of music representation learned by PEMR.
HyperText: Endowing FastText with Hyperbolic Geometry
Oct 30, 2020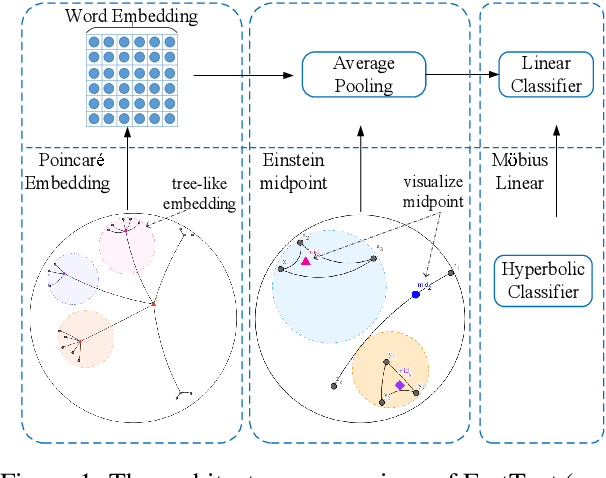


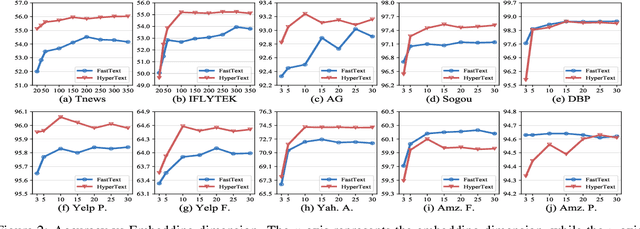
Natural language data exhibit tree-like hierarchical structures such as the hypernym-hyponym relations in WordNet. FastText, as the state-of-the-art text classifier based on shallow neural network in Euclidean space, may not model such hierarchies precisely with limited representation capacity. Considering that hyperbolic space is naturally suitable for modeling tree-like hierarchical data, we propose a new model named HyperText for efficient text classification by endowing FastText with hyperbolic geometry. Empirically, we show that HyperText outperforms FastText on a range of text classification tasks with much reduced parameters.