 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning with Positive-Negative Frame Mask for Music Representation
Paper and Code
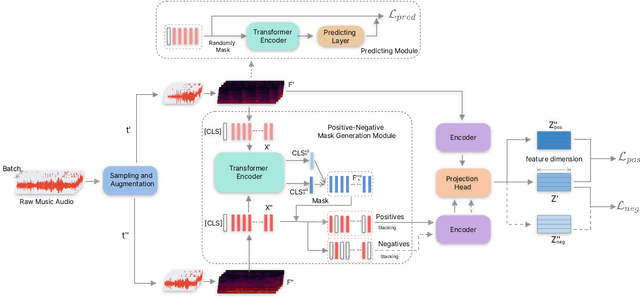
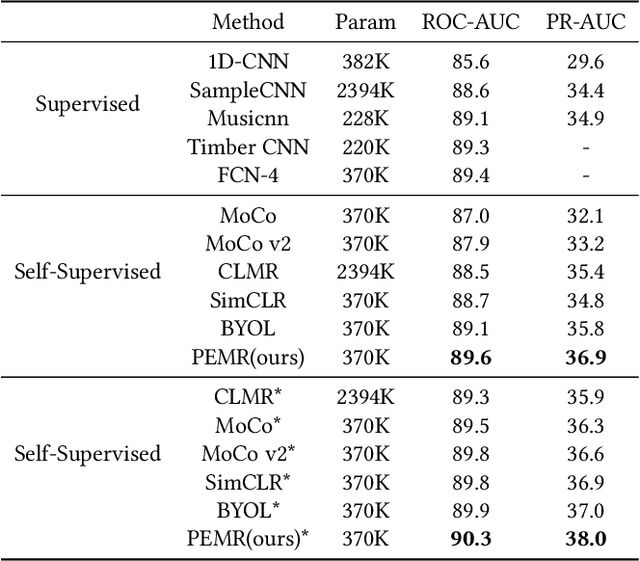
Self-supervised learning, especially contrastive learning, has made an outstanding contribution to the development of many deep learning research fields. Recently, researchers in the acoustic signal processing field noticed its success and leveraged contrastive learning for better music representation. Typically, existing approaches maximize the similarity between two distorted audio segments sampled from the same music. In other words, they ensure a semantic agreement at the music level. However, those coarse-grained methods neglect some inessential or noisy elements at the frame level, which may be detrimental to the model to learn the effective representation of music. Towards this end, this paper proposes a novel Positive-nEgative frame mask for Music Representation based on the contrastive learning framework, abbreviated as PEMR. Concretely, PEMR incorporates a Positive-Negative Mask Generation module, which leverages transformer blocks to generate frame masks on the Log-Mel spectrogram. We can generate self-augmented negative and positive samples by masking important components or inessential components, respectively. We devise a novel contrastive learning objective to accommodate both self-augmented positives/negatives sampled from the same music. We conduct experiments on four public datasets. The experimental results of two music-related downstream tasks, music classification, and cover song identification, demonstrate the generalization ability and transferability of music representation learned by PEMR.