 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUTC: A Unified Transformer with Inter-Task Contrastive Learning for Visual Dialog
Paper and Code
May 03, 2022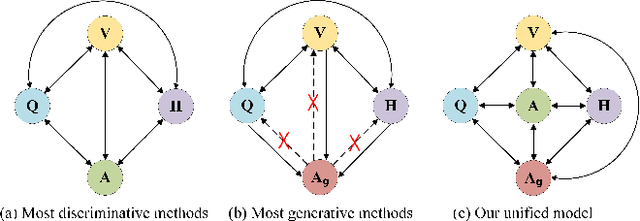
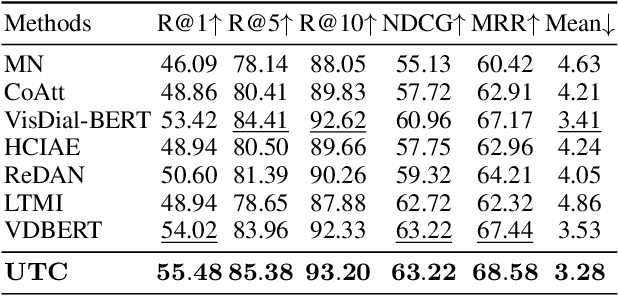
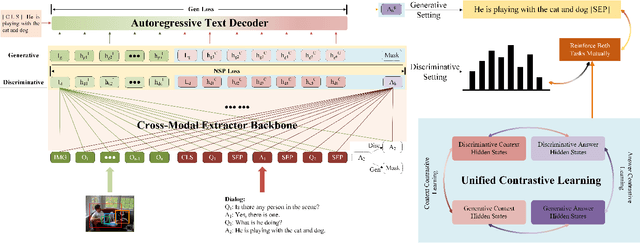
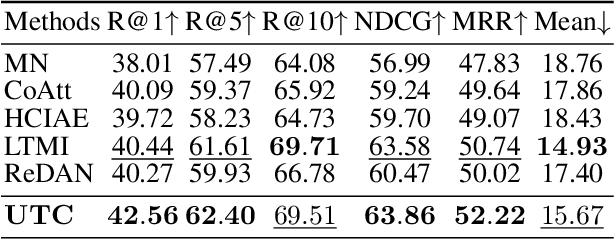
Visual Dialog aims to answer multi-round, interactive questions based on the dialog history and image content. Existing methods either consider answer ranking and generating individually or only weakly capture the relation across the two tasks implicitly by two separate models. The research on a universal framework that jointly learns to rank and generate answers in a single model is seldom explored. In this paper, we propose a contrastive learning-based framework UTC to unify and facilitate both discriminative and generative tasks in visual dialog with a single model. Specifically, considering the inherent limitation of the previous learning paradigm, we devise two inter-task contrastive losses i.e., context contrastive loss and answer contrastive loss to make the discriminative and generative tasks mutually reinforce each other. These two complementary contrastive losses exploit dialog context and target answer as anchor points to provide representation learning signals from different perspectives. We evaluate our proposed UTC on the VisDial v1.0 dataset, where our method outperforms the state-of-the-art on both discriminative and generative tasks and surpasses previous state-of-the-art generative methods by more than 2 absolute points on Recall@1.