 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Instance-based Plus Ensemble Learning Method for Classification of Scientific Papers
Sep 21, 2024
The exponential growth of scientific publications in recent years has posed a significant challenge in effective and efficient categorization. This paper introduces a novel approach that combines instance-based learning and ensemble learning techniques for classifying scientific papers into relevant research fields. Working with a classification system with a group of research fields, first a number of typical seed papers are allocated to each of the fields manually. Then for each paper that needs to be classified, we compare it with all the seed papers in every field. Contents and citations are considered separately. An ensemble-based method is then employed to make the final decision. Experimenting with the datasets from DBLP, our experimental results demonstrate that the proposed classification method is effective and efficient in categorizing papers into various research areas. We also find that both content and citation features are useful for the classification of scientific papers.
Streamlined Data Fusion: Unleashing the Power of Linear Combination with Minimal Relevance Judgments
Sep 21, 2023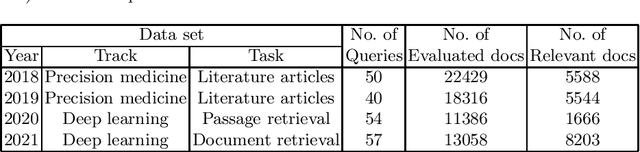



Linear combination is a potent data fusion method in information retrieval tasks, thanks to its ability to adjust weights for diverse scenarios. However, achieving optimal weight training has traditionally required manual relevance judgments on a large percentage of documents, a labor-intensive and expensive process. In this study, we investigate the feasibility of obtaining near-optimal weights using a mere 20\%-50\% of relevant documents. Through experiments on four TREC datasets, we find that weights trained with multiple linear regression using this reduced set closely rival those obtained with TREC's official "qrels." Our findings unlock the potential for more efficient and affordable data fusion, empowering researchers and practitioners to reap its full benefits with significantly less effort.
A Dataset-Level Geometric Framework for Ensemble Classifiers
Jun 16, 2021
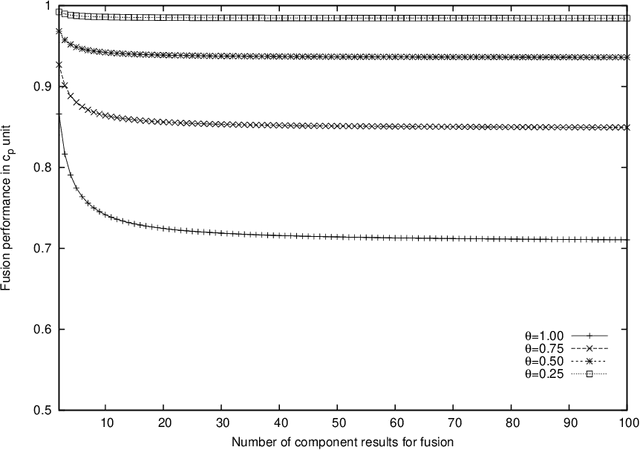
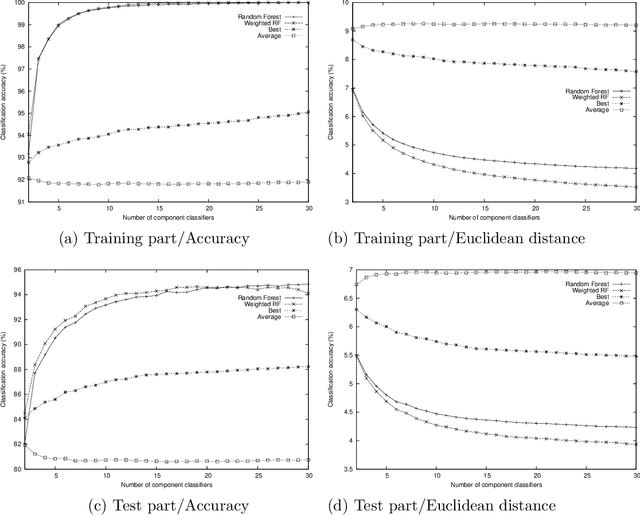
Ensemble classifiers have been investigated by many in the artificial intelligence and machine learning community. Majority voting and weighted majority voting are two commonly used combination schemes in ensemble learning. However, understanding of them is incomplete at best, with some properties even misunderstood. In this paper, we present a group of properties of these two schemes formally under a dataset-level geometric framework. Two key factors, every component base classifier's performance and dissimilarity between each pair of component classifiers are evaluated by the same metric - the Euclidean distance. Consequently, ensembling becomes a deterministic problem and the performance of an ensemble can be calculated directly by a formula. We prove several theorems of interest and explain their implications for ensembles. In particular, we compare and contrast the effect of the number of component classifiers on these two types of ensemble schemes. Empirical investigation is also conducted to verify the theoretical results when other metrics such as accuracy are used. We believe that the results from this paper are very useful for us to understand the fundamental properties of these two combination schemes and the principles of ensemble classifiers in general. The results are also helpful for us to investigate some issues in ensemble classifiers, such as ensemble performance prediction, selecting a small number of base classifiers to obtain efficient and effective ensembles.