 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyMotion: Structured 3D Motion Reward for Physics-Grounded Human Video Generation
May 14, 2026Generating realistic human motion is a central yet unsolved challenge in video generation. While reinforcement learning (RL)-based post-training has driven recent gains in general video quality, extending it to human motion remains bottlenecked by a reward signal that cannot reliably score motion realism. Existing video rewards primarily rely on 2D perceptual signals, without explicitly modeling the 3D body state, contact, and dynamics underlying articulated human motion, and often assign high scores to videos with floating bodies or physically implausible movements. To address this, we propose PhyMotion, a structured, fine-grained motion reward that grounds recovered 3D human trajectories in a physics simulator and evaluates motion quality along multiple dimensions of physical feasibility. Concretely, we recover SMPL body meshes from generated videos, retarget them onto a humanoid in the MuJoCo physics simulator, and evaluate the resulting motion along three axes: kinematic plausibility, contact and balance consistency, and dynamic feasibility. Each component provides a continuous and interpretable signal tied to a specific aspect of motion quality, allowing the reward to capture which aspects of motion are physically correct or violated. Experiments show that PhyMotion achieves stronger correlation with human judgments than existing reward formulations. These gains carry over to RL-based post-training, where optimizing PhyMotion leads to larger and more consistent improvements than optimizing existing rewards, improving motion realism across both autoregressive and bidirectional video generators under both automatic metrics and blind human evaluation (+68 Elo gain). Ablations show that the three axes provide complementary supervision signals, while the reward preserves overall video generation quality with only modest training overhead.
DriVLMe: Enhancing LLM-based Autonomous Driving Agents with Embodied and Social Experiences
Jun 05, 2024



Recent advancements in foundation models (FMs) have unlocked new prospects in autonomous driving, yet the experimental settings of these studies are preliminary, over-simplified, and fail to capture the complexity of real-world driving scenarios in human environments. It remains under-explored whether FM agents can handle long-horizon navigation tasks with free-from dialogue and deal with unexpected situations caused by environmental dynamics or task changes. To explore the capabilities and boundaries of FMs faced with the challenges above, we introduce DriVLMe, a video-language-model-based agent to facilitate natural and effective communication between humans and autonomous vehicles that perceive the environment and navigate. We develop DriVLMe from both embodied experiences in a simulated environment and social experiences from real human dialogue. While DriVLMe demonstrates competitive performance in both open-loop benchmarks and closed-loop human studies, we reveal several limitations and challenges, including unacceptable inference time, imbalanced training data, limited visual understanding, challenges with multi-turn interactions, simplified language generation from robotic experiences, and difficulties in handling on-the-fly unexpected situations like environmental dynamics and task changes.
Map Optical Properties to Subwavelength Structures Directly via a Diffusion Model
Apr 09, 2024



Subwavelength photonic structures and metamaterials provide revolutionary approaches for controlling light. The inverse design methods proposed for these subwavelength structures are vital to the development of new photonic devices. However, most of the existing inverse design methods cannot realize direct mapping from optical properties to photonic structures but instead rely on forward simulation methods to perform iterative optimization. In this work, we exploit the powerful generative abilities of artificial intelligence (AI) and propose a practical inverse design method based on latent diffusion models. Our method maps directly the optical properties to structures without the requirement of forward simulation and iterative optimization. Here, the given optical properties can work as "prompts" and guide the constructed model to correctly "draw" the required photonic structures. Experiments show that our direct mapping-based inverse design method can generate subwavelength photonic structures at high fidelity while following the given optical properties. This may change the method used for optical design and greatly accelerate the research on new photonic devices.
Inversion-Free Image Editing with Natural Language
Dec 07, 2023



Despite recent advances in inversion-based editing, text-guided image manipulation remains challenging for diffusion models. The primary bottlenecks include 1) the time-consuming nature of the inversion process; 2) the struggle to balance consistency with accuracy; 3) the lack of compatibility with efficient consistency sampling methods used in consistency models. To address the above issues, we start by asking ourselves if the inversion process can be eliminated for editing. We show that when the initial sample is known, a special variance schedule reduces the denoising step to the same form as the multi-step consistency sampling. We name this Denoising Diffusion Consistent Model (DDCM), and note that it implies a virtual inversion strategy without explicit inversion in sampling. We further unify the attention control mechanisms in a tuning-free framework for text-guided editing. Combining them, we present inversion-free editing (InfEdit), which allows for consistent and faithful editing for both rigid and non-rigid semantic changes, catering to intricate modifications without compromising on the image's integrity and explicit inversion. Through extensive experiments, InfEdit shows strong performance in various editing tasks and also maintains a seamless workflow (less than 3 seconds on one single A40), demonstrating the potential for real-time applications. Project Page: https://sled-group.github.io/InfEdit/
CycleNet: Rethinking Cycle Consistency in Text-Guided Diffusion for Image Manipulation
Oct 19, 2023
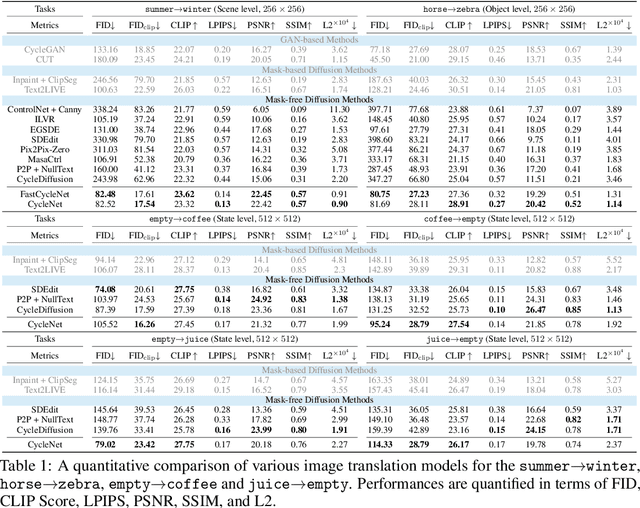
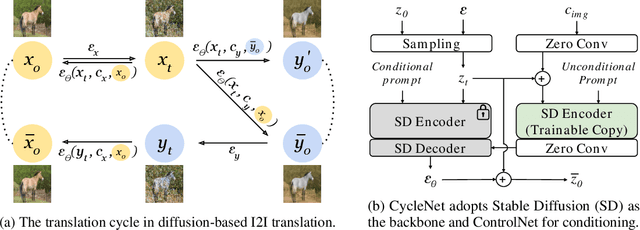

Diffusion models (DMs) have enabled breakthroughs in image synthesis tasks but lack an intuitive interface for consistent image-to-image (I2I) translation. Various methods have been explored to address this issue, including mask-based methods, attention-based methods, and image-conditioning. However, it remains a critical challenge to enable unpaired I2I translation with pre-trained DMs while maintaining satisfying consistency. This paper introduces Cyclenet, a novel but simple method that incorporates cycle consistency into DMs to regularize image manipulation. We validate Cyclenet on unpaired I2I tasks of different granularities. Besides the scene and object level translation, we additionally contribute a multi-domain I2I translation dataset to study the physical state changes of objects. Our empirical studies show that Cyclenet is superior in translation consistency and quality, and can generate high-quality images for out-of-domain distributions with a simple change of the textual prompt. Cyclenet is a practical framework, which is robust even with very limited training data (around 2k) and requires minimal computational resources (1 GPU) to train. Project homepage: https://cyclenetweb.github.io/
Streamlined Data Fusion: Unleashing the Power of Linear Combination with Minimal Relevance Judgments
Sep 21, 2023



Linear combination is a potent data fusion method in information retrieval tasks, thanks to its ability to adjust weights for diverse scenarios. However, achieving optimal weight training has traditionally required manual relevance judgments on a large percentage of documents, a labor-intensive and expensive process. In this study, we investigate the feasibility of obtaining near-optimal weights using a mere 20\%-50\% of relevant documents. Through experiments on four TREC datasets, we find that weights trained with multiple linear regression using this reduced set closely rival those obtained with TREC's official "qrels." Our findings unlock the potential for more efficient and affordable data fusion, empowering researchers and practitioners to reap its full benefits with significantly less effort.
Deep-learning-based on-chip rapid spectral imaging with high spatial resolution
Jan 16, 2023Spectral imaging extends the concept of traditional color cameras to capture images across multiple spectral channels and has broad application prospects. Conventional spectral cameras based on scanning methods suffer from low acquisition speed and large volume. On-chip computational spectral imaging based on metasurface filters provides a promising scheme for portable applications, but endures long computation time for point-by-point iterative spectral reconstruction and mosaic effect in the reconstructed spectral images. In this study, we demonstrated on-chip rapid spectral imaging eliminating the mosaic effect in the spectral image by deep-learning-based spectral data cube reconstruction. We experimentally achieved four orders of magnitude speed improvement than iterative spectral reconstruction and high fidelity of spectral reconstruction over 99% for a standard color board. In particular, we demonstrated video-rate spectral imaging for moving objects and outdoor driving scenes with good performance for recognizing metamerism, where the concolorous sky and white cars can be distinguished via their spectra, showing great potential for autonomous driving and other practical applications in the field of intelligent perception.
Discovering Intrinsic Reward with Contrastive Random Walk
Apr 23, 2022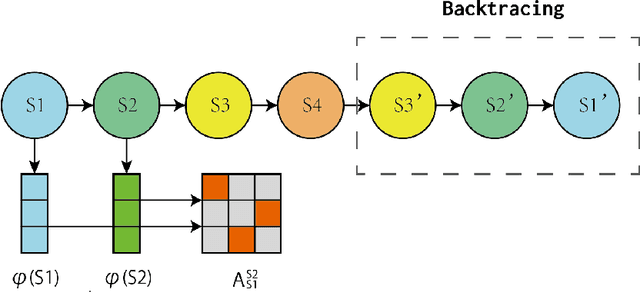

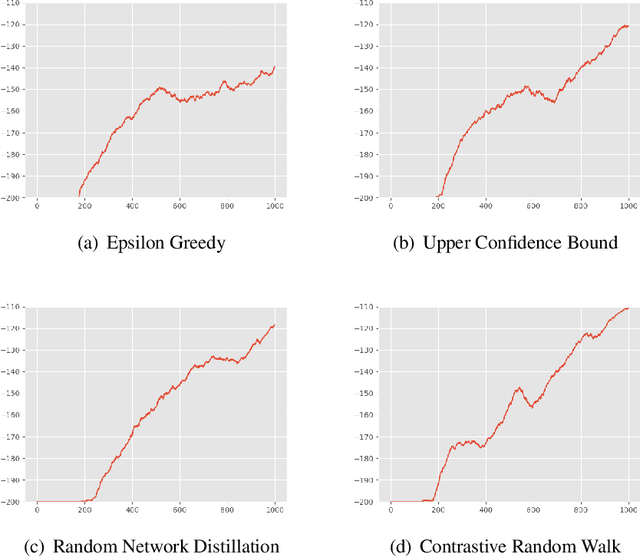
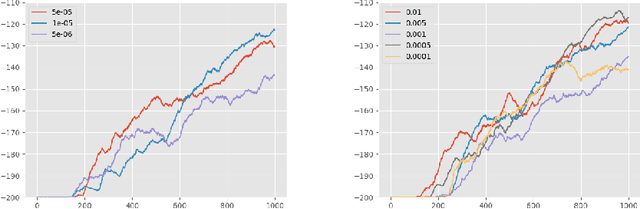
The aim of this paper is to demonstrate the efficacy of using Contrastive Random Walk as a curiosity method to achieve faster convergence to the optimal policy.Contrastive Random Walk defines the transition matrix of a random walk with the help of neural networks. It learns a meaningful state representation with a closed loop. The loss of Contrastive Random Walk serves as an intrinsic reward and is added to the environment reward. Our method works well in non-tabular sparse reward scenarios, in the sense that our method receives the highest reward within the same iterations compared to other methods. Meanwhile, Contrastive Random Walk is more robust. The performance doesn't change much with different random initialization of environments. We also find that adaptive restart and appropriate temperature are crucial to the performance of Contrastive Random Walk.
A-ESRGAN: Training Real-World Blind Super-Resolution with Attention U-Net Discriminators
Dec 19, 2021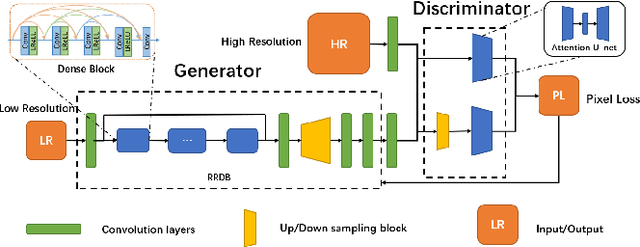

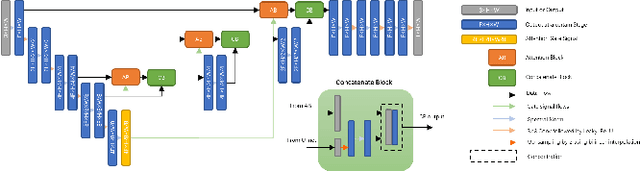
Blind image super-resolution(SR) is a long-standing task in CV that aims to restore low-resolution images suffering from unknown and complex distortions. Recent work has largely focused on adopting more complicated degradation models to emulate real-world degradations. The resulting models have made breakthroughs in perceptual loss and yield perceptually convincing results. However, the limitation brought by current generative adversarial network structures is still significant: treating pixels equally leads to the ignorance of the image's structural features, and results in performance drawbacks such as twisted lines and background over-sharpening or blurring. In this paper, we present A-ESRGAN, a GAN model for blind SR tasks featuring an attention U-Net based, multi-scale discriminator that can be seamlessly integrated with other generators. To our knowledge, this is the first work to introduce attention U-Net structure as the discriminator of GAN to solve blind SR problems. And the paper also gives an interpretation for the mechanism behind multi-scale attention U-Net that brings performance breakthrough to the model. Through comparison experiments with prior works, our model presents state-of-the-art level performance on the non-reference natural image quality evaluator metric. And our ablation studies have shown that with our discriminator, the RRDB based generator can leverage the structural features of an image in multiple scales, and consequently yields more perceptually realistic high-resolution images compared to prior works.
All-Optical Image Identification with Programmable Matrix Transformation
Apr 01, 2021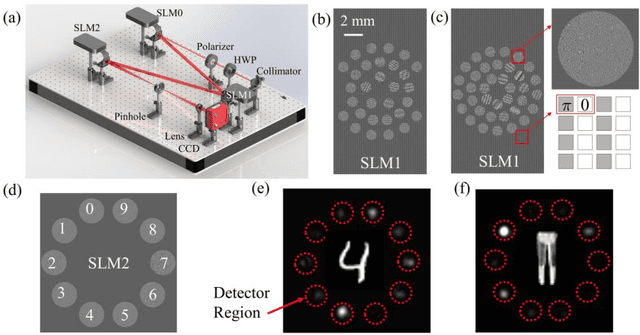
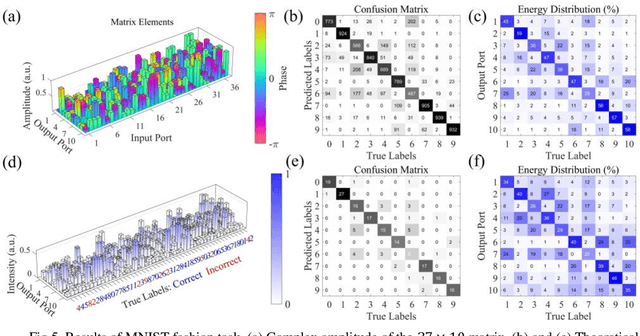
An optical neural network is proposed and demonstrated with programmable matrix transformation and nonlinear activation function of photodetection (square-law detection). Based on discrete phase-coherent spatial modes, the dimensionality of programmable optical matrix operations is 30~37, which is implemented by spatial light modulators. With this architecture, all-optical classification tasks of handwritten digits, objects and depth images are performed on the same platform with high accuracy. Due to the parallel nature of matrix multiplication, the processing speed of our proposed architecture is potentially as high as7.4T~74T FLOPs per second (with 10~100GHz detector)