 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlined Data Fusion: Unleashing the Power of Linear Combination with Minimal Relevance Judgments
Sep 21, 2023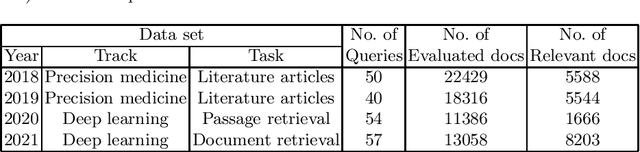



Linear combination is a potent data fusion method in information retrieval tasks, thanks to its ability to adjust weights for diverse scenarios. However, achieving optimal weight training has traditionally required manual relevance judgments on a large percentage of documents, a labor-intensive and expensive process. In this study, we investigate the feasibility of obtaining near-optimal weights using a mere 20\%-50\% of relevant documents. Through experiments on four TREC datasets, we find that weights trained with multiple linear regression using this reduced set closely rival those obtained with TREC's official "qrels." Our findings unlock the potential for more efficient and affordable data fusion, empowering researchers and practitioners to reap its full benefits with significantly less effort.