 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Chain-of-Thought as Planning: Decoupling Reasoning from Verbalization
Jan 29, 2026Chain-of-Thought (CoT) empowers Large Language Models (LLMs) to tackle complex problems, but remains constrained by the computational cost and reasoning path collapse when grounded in discrete token spaces. Recent latent reasoning approaches attempt to optimize efficiency by performing reasoning within continuous hidden states. However, these methods typically operate as opaque end-to-end mappings from explicit reasoning steps to latent states, and often require a pre-defined number of latent steps during inference. In this work, we introduce PLaT (Planning with Latent Thoughts), a framework that reformulates latent reasoning as planning by fundamentally decouple reasoning from verbalization. We model reasoning as a deterministic trajectory of latent planning states, while a separate Decoder grounds these thoughts into text when necessary. This decoupling allows the model to dynamically determine when to terminate reasoning rather than relying on fixed hyperparameters. Empirical results on mathematical benchmarks reveal a distinct trade-off: while PLaT achieves lower greedy accuracy than baselines, it demonstrates superior scalability in terms of reasoning diversity. This indicates that PLaT learns a robust, broader solution space, offering a transparent and scalable foundation for inference-time search.
UniSplat: Unified Spatio-Temporal Fusion via 3D Latent Scaffolds for Dynamic Driving Scene Reconstruction
Nov 06, 2025Feed-forward 3D reconstruction for autonomous driving has advanced rapidly, yet existing methods struggle with the joint challenges of sparse, non-overlapping camera views and complex scene dynamics. We present UniSplat, a general feed-forward framework that learns robust dynamic scene reconstruction through unified latent spatio-temporal fusion. UniSplat constructs a 3D latent scaffold, a structured representation that captures geometric and semantic scene context by leveraging pretrained foundation models. To effectively integrate information across spatial views and temporal frames, we introduce an efficient fusion mechanism that operates directly within the 3D scaffold, enabling consistent spatio-temporal alignment. To ensure complete and detailed reconstructions, we design a dual-branch decoder that generates dynamic-aware Gaussians from the fused scaffold by combining point-anchored refinement with voxel-based generation, and maintain a persistent memory of static Gaussians to enable streaming scene completion beyond current camera coverage. Extensive experiments on real-world datasets demonstrate that UniSplat achieves state-of-the-art performance in novel view synthesis, while providing robust and high-quality renderings even for viewpoints outside the original camera coverage.
CAGE: Continuity-Aware edGE Network Unlocks Robust Floorplan Reconstruction
Sep 18, 2025We present \textbf{CAGE} (\textit{Continuity-Aware edGE}) network, a \textcolor{red}{robust} framework for reconstructing vector floorplans directly from point-cloud density maps. Traditional corner-based polygon representations are highly sensitive to noise and incomplete observations, often resulting in fragmented or implausible layouts. Recent line grouping methods leverage structural cues to improve robustness but still struggle to recover fine geometric details. To address these limitations, we propose a \textit{native} edge-centric formulation, modeling each wall segment as a directed, geometrically continuous edge. This representation enables inference of coherent floorplan structures, ensuring watertight, topologically valid room boundaries while improving robustness and reducing artifacts. Towards this design, we develop a dual-query transformer decoder that integrates perturbed and latent queries within a denoising framework, which not only stabilizes optimization but also accelerates convergence. Extensive experiments on Structured3D and SceneCAD show that \textbf{CAGE} achieves state-of-the-art performance, with F1 scores of 99.1\% (rooms), 91.7\% (corners), and 89.3\% (angles). The method also demonstrates strong cross-dataset generalization, underscoring the efficacy of our architectural innovations. Code and pretrained models will be released upon acceptance.
STAMImputer: Spatio-Temporal Attention MoE for Traffic Data Imputation
Jun 11, 2025Traffic data imputation is fundamentally important to support various applications in intelligent transportation systems such as traffic flow prediction. However, existing time-to-space sequential methods often fail to effectively extract features in block-wise missing data scenarios. Meanwhile, the static graph structure for spatial feature propagation significantly constrains the models flexibility in handling the distribution shift issue for the nonstationary traffic data. To address these issues, this paper proposes a SpatioTemporal Attention Mixture of experts network named STAMImputer for traffic data imputation. Specifically, we introduce a Mixture of Experts (MoE) framework to capture latent spatio-temporal features and their influence weights, effectively imputing block missing. A novel Low-rank guided Sampling Graph ATtention (LrSGAT) mechanism is designed to dynamically balance the local and global correlations across road networks. The sampled attention vectors are utilized to generate dynamic graphs that capture real-time spatial correlations. Extensive experiments are conducted on four traffic datasets for evaluation. The result shows STAMImputer achieves significantly performance improvement compared with existing SOTA approaches. Our codes are available at https://github.com/RingBDStack/STAMImupter.
Unsupervised Graph Clustering with Deep Structural Entropy
May 20, 2025Research on Graph Structure Learning (GSL) provides key insights for graph-based clustering, yet current methods like Graph Neural Networks (GNNs), Graph Attention Networks (GATs), and contrastive learning often rely heavily on the original graph structure. Their performance deteriorates when the original graph's adjacency matrix is too sparse or contains noisy edges unrelated to clustering. Moreover, these methods depend on learning node embeddings and using traditional techniques like k-means to form clusters, which may not fully capture the underlying graph structure between nodes. To address these limitations, this paper introduces DeSE, a novel unsupervised graph clustering framework incorporating Deep Structural Entropy. It enhances the original graph with quantified structural information and deep neural networks to form clusters. Specifically, we first propose a method for calculating structural entropy with soft assignment, which quantifies structure in a differentiable form. Next, we design a Structural Learning layer (SLL) to generate an attributed graph from the original feature data, serving as a target to enhance and optimize the original structural graph, thereby mitigating the issue of sparse connections between graph nodes. Finally, our clustering assignment method (ASS), based on GNNs, learns node embeddings and a soft assignment matrix to cluster on the enhanced graph. The ASS layer can be stacked to meet downstream task requirements, minimizing structural entropy for stable clustering and maximizing node consistency with edge-based cross-entropy loss. Extensive comparative experiments are conducted on four benchmark datasets against eight representative unsupervised graph clustering baselines, demonstrating the superiority of the DeSE in both effectiveness and interpretability.
IsoSEL: Isometric Structural Entropy Learning for Deep Graph Clustering in Hyperbolic Space
Apr 14, 2025Graph clustering is a longstanding topic in machine learning. In recent years, deep learning methods have achieved encouraging results, but they still require predefined cluster numbers K, and typically struggle with imbalanced graphs, especially in identifying minority clusters. The limitations motivate us to study a challenging yet practical problem: deep graph clustering without K considering the imbalance in reality. We approach this problem from a fresh perspective of information theory (i.e., structural information). In the literature, structural information has rarely been touched in deep clustering, and the classic definition falls short in its discrete formulation, neglecting node attributes and exhibiting prohibitive complexity. In this paper, we first establish a new Differentiable Structural Information, generalizing the discrete formalism to continuous realm, so that the optimal partitioning tree, revealing the cluster structure, can be created by the gradient backpropagation. Theoretically, we demonstrate its capability in clustering without requiring K and identifying the minority clusters in imbalanced graphs, while reducing the time complexity to O(N) w.r.t. the number of nodes. Subsequently, we present a novel IsoSEL framework for deep graph clustering, where we design a hyperbolic neural network to learn the partitioning tree in the Lorentz model of hyperbolic space, and further conduct Lorentz Tree Contrastive Learning with isometric augmentation. As a result, the partitioning tree incorporates node attributes via mutual information maximization, while the cluster assignment is refined by the proposed tree contrastive learning. Extensive experiments on five benchmark datasets show the IsoSEL outperforms 14 recent baselines by an average of +1.3% in NMI.
InVDriver: Intra-Instance Aware Vectorized Query-Based Autonomous Driving Transformer
Feb 25, 2025



End-to-end autonomous driving with its holistic optimization capabilities, has gained increasing traction in academia and industry. Vectorized representations, which preserve instance-level topological information while reducing computational overhead, have emerged as a promising paradigm. While existing vectorized query-based frameworks often overlook the inherent spatial correlations among intra-instance points, resulting in geometrically inconsistent outputs (e.g., fragmented HD map elements or oscillatory trajectories). To address these limitations, we propose InVDriver, a novel vectorized query-based system that systematically models intra-instance spatial dependencies through masked self-attention layers, thereby enhancing planning accuracy and trajectory smoothness. Across all core modules, i.e., perception, prediction, and planning, InVDriver incorporates masked self-attention mechanisms that restrict attention to intra-instance point interactions, enabling coordinated refinement of structural elements while suppressing irrelevant inter-instance noise. Experimental results on the nuScenes benchmark demonstrate that InVDriver achieves state-of-the-art performance, surpassing prior methods in both accuracy and safety, while maintaining high computational efficiency. Our work validates that explicit modeling of intra-instance geometric coherence is critical for advancing vectorized autonomous driving systems, bridging the gap between theoretical advantages of end-to-end frameworks and practical deployment requirements.
Motion Forecasting for Autonomous Vehicles: A Survey
Feb 10, 2025In recent years, the field of autonomous driving has attracted increasingly significant public interest. Accurately forecasting the future behavior of various traffic participants is essential for the decision-making of Autonomous Vehicles (AVs). In this paper, we focus on both scenario-based and perception-based motion forecasting for AVs. We propose a formal problem formulation for motion forecasting and summarize the main challenges confronting this area of research. We also detail representative datasets and evaluation metrics pertinent to this field. Furthermore, this study classifies recent research into two main categories: supervised learning and self-supervised learning, reflecting the evolving paradigms in both scenario-based and perception-based motion forecasting. In the context of supervised learning, we thoroughly examine and analyze each key element of the methodology. For self-supervised learning, we summarize commonly adopted techniques. The paper concludes and discusses potential research directions, aiming to propel progress in this vital area of AV technology.
A real-time battle situation intelligent awareness system based on Meta-learning & RNN
Jan 23, 2025



In modern warfare, real-time and accurate battle situation analysis is crucial for making strategic and tactical decisions. The proposed real-time battle situation intelligent awareness system (BSIAS) aims at meta-learning analysis and stepwise RNN (recurrent neural network) modeling, where the former carries out the basic processing and analysis of battlefield data, which includes multi-steps such as data cleansing, data fusion, data mining and continuously updates, and the latter optimizes the battlefield modeling by stepwise capturing the temporal dependencies of data set. BSIAS can predict the possible movement from any side of the fence and attack routes by taking a simulated battle as an example, which can be an intelligent support platform for commanders to make scientific decisions during wartime. This work delivers the potential application of integrated BSIAS in the field of battlefield command & analysis engineering.
Structural Entropy Guided Probabilistic Coding
Dec 12, 2024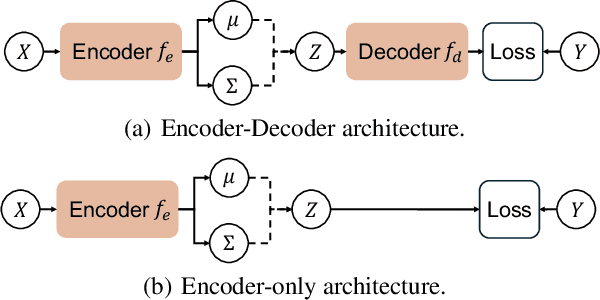



Probabilistic embeddings have several advantages over deterministic embeddings as they map each data point to a distribution, which better describes the uncertainty and complexity of data. Many works focus on adjusting the distribution constraint under the Information Bottleneck (IB) principle to enhance representation learning. However, these proposed regularization terms only consider the constraint of each latent variable, omitting the structural information between latent variables. In this paper, we propose a novel structural entropy-guided probabilistic coding model, named SEPC. Specifically, we incorporate the relationship between latent variables into the optimization by proposing a structural entropy regularization loss. Besides, as traditional structural information theory is not well-suited for regression tasks, we propose a probabilistic encoding tree, transferring regression tasks to classification tasks while diminishing the influence of the transformation. Experimental results across 12 natural language understanding tasks, including both classification and regression tasks, demonstrate the superior performance of SEPC compared to other state-of-the-art models in terms of effectiveness, generalization capability, and robustness to label noise. The codes and datasets are available at https://github.com/SELGroup/SEPC.