 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Multimodal Personality Understanding through Dual Causal Intervention
May 07, 2026Multimodalpersonalityunderstandingplaysacriticalroleinhuman centered artificial intelligence. Previous work mainly focus on learn-ing rich multimodal representations for video personality under standing. However, they often suffer from potential harm caused by subject bias (e.g., observable age and unobservable mental states), as subjects originate from diverse demographic backgrounds. Learn ing such spurious associations between multimodal features and traits may lead to unfair personality understanding. In this work, weconstruct aStructural Causal Model (SCM)toanalyze theimpact of these biases from a causal perspective, and propose a novel Dual Causal Adjustment Network (DCAN) to mitigate the interference of subject attributes on personality understanding. Specifically, we design a Back-door Adjustment Causal Learning (BACL) module to block spurious correlations from observable demographic factors via a prototype-based confounder dictionary, and subsequently ap ply a Front-door Adjustment Causal Learning (FACL) module to ad dress latent and unobservable biases throughalearnedmediatordic tionary intervention, thereby achieving causal disentanglement of representations for deconfounded reasoning. Importantly, we con struct a Demographic-annotated Multimodal Student Personality (DMSP) dataset to support the analysis and discussion of fairness related factors. Extensive experiments on the benchmark dataset CFI-V2 and our DMSPdataset demonstrate that DCAN consistently improves prediction accuracy, reaching 92.11% and 92.90%, respec tively. Meanwhile, the improvementsinthefairnessmetricsofequal opportunity and demographic parity are 6.57% and 7.97% on CFI-V2, and 15.38% and 20.06% on the DMSP dataset. Our code and DMSP dataset are available at https://github.com/Sabrina-han/DCAN
Eq.Bot: Enhance Robotic Manipulation Learning via Group Equivariant Canonicalization
Nov 19, 2025Robotic manipulation systems are increasingly deployed across diverse domains. Yet existing multi-modal learning frameworks lack inherent guarantees of geometric consistency, struggling to handle spatial transformations such as rotations and translations. While recent works attempt to introduce equivariance through bespoke architectural modifications, these methods suffer from high implementation complexity, computational cost, and poor portability. Inspired by human cognitive processes in spatial reasoning, we propose Eq.Bot, a universal canonicalization framework grounded in SE(2) group equivariant theory for robotic manipulation learning. Our framework transforms observations into a canonical space, applies an existing policy, and maps the resulting actions back to the original space. As a model-agnostic solution, Eq.Bot aims to endow models with spatial equivariance without requiring architectural modifications. Extensive experiments demonstrate the superiority of Eq.Bot under both CNN-based (e.g., CLIPort) and Transformer-based (e.g., OpenVLA-OFT) architectures over existing methods on various robotic manipulation tasks, where the most significant improvement can reach 50.0%.
Motion Forecasting for Autonomous Vehicles: A Survey
Feb 10, 2025In recent years, the field of autonomous driving has attracted increasingly significant public interest. Accurately forecasting the future behavior of various traffic participants is essential for the decision-making of Autonomous Vehicles (AVs). In this paper, we focus on both scenario-based and perception-based motion forecasting for AVs. We propose a formal problem formulation for motion forecasting and summarize the main challenges confronting this area of research. We also detail representative datasets and evaluation metrics pertinent to this field. Furthermore, this study classifies recent research into two main categories: supervised learning and self-supervised learning, reflecting the evolving paradigms in both scenario-based and perception-based motion forecasting. In the context of supervised learning, we thoroughly examine and analyze each key element of the methodology. For self-supervised learning, we summarize commonly adopted techniques. The paper concludes and discusses potential research directions, aiming to propel progress in this vital area of AV technology.
Parameter-Efficient Fine-Tuning for Foundation Models
Jan 23, 2025This survey delves into the realm of Parameter-Efficient Fine-Tuning (PEFT) within the context of Foundation Models (FMs). PEFT, a cost-effective fine-tuning technique, minimizes parameters and computational complexity while striving for optimal downstream task performance. FMs, like ChatGPT, DALL-E, and LLaVA specialize in language understanding, generative tasks, and multimodal tasks, trained on diverse datasets spanning text, images, and videos. The diversity of FMs guides various adaptation strategies for PEFT. Therefore, this survey aims to provide a comprehensive overview of PEFT techniques applied to diverse FMs and address critical gaps in understanding the techniques, trends, and applications. We start by providing a detailed development of FMs and PEFT. Subsequently, we systematically review the key categories and core mechanisms of PEFT across diverse FMs to offer a comprehensive understanding of trends. We also explore the most recent applications across various FMs to demonstrate the versatility of PEFT, shedding light on the integration of systematic PEFT methods with a range of FMs. Furthermore, we identify potential research and development directions for improving PEFTs in the future. This survey provides a valuable resource for both newcomers and experts seeking to understand and use the power of PEFT across FMs. All reviewed papers are listed at \url{https://github.com/THUDM/Awesome-Parameter-Efficient-Fine-Tuning-for-Foundation-Models}.
Multi-turn Response Selection with Commonsense-enhanced Language Models
Jul 26, 2024



As a branch of advanced artificial intelligence, dialogue systems are prospering. Multi-turn response selection is a general research problem in dialogue systems. With the assistance of background information and pre-trained language models, the performance of state-of-the-art methods on this problem gains impressive improvement. However, existing studies neglect the importance of external commonsense knowledge. Hence, we design a Siamese network where a pre-trained Language model merges with a Graph neural network (SinLG). SinLG takes advantage of Pre-trained Language Models (PLMs) to catch the word correlations in the context and response candidates and utilizes a Graph Neural Network (GNN) to reason helpful common sense from an external knowledge graph. The GNN aims to assist the PLM in fine-tuning, and arousing its related memories to attain better performance. Specifically, we first extract related concepts as nodes from an external knowledge graph to construct a subgraph with the context response pair as a super node for each sample. Next, we learn two representations for the context response pair via both the PLM and GNN. A similarity loss between the two representations is utilized to transfer the commonsense knowledge from the GNN to the PLM. Then only the PLM is used to infer online so that efficiency can be guaranteed. Finally, we conduct extensive experiments on two variants of the PERSONA-CHAT dataset, which proves that our solution can not only improve the performance of the PLM but also achieve an efficient inference.
MultiSPANS: A Multi-range Spatial-Temporal Transformer Network for Traffic Forecast via Structural Entropy Optimization
Nov 06, 2023



Traffic forecasting is a complex multivariate time-series regression task of paramount importance for traffic management and planning. However, existing approaches often struggle to model complex multi-range dependencies using local spatiotemporal features and road network hierarchical knowledge. To address this, we propose MultiSPANS. First, considering that an individual recording point cannot reflect critical spatiotemporal local patterns, we design multi-filter convolution modules for generating informative ST-token embeddings to facilitate attention computation. Then, based on ST-token and spatial-temporal position encoding, we employ the Transformers to capture long-range temporal and spatial dependencies. Furthermore, we introduce structural entropy theory to optimize the spatial attention mechanism. Specifically, The structural entropy minimization algorithm is used to generate optimal road network hierarchies, i.e., encoding trees. Based on this, we propose a relative structural entropy-based position encoding and a multi-head attention masking scheme based on multi-layer encoding trees. Extensive experiments demonstrate the superiority of the presented framework over several state-of-the-art methods in real-world traffic datasets, and the longer historical windows are effectively utilized. The code is available at https://github.com/SELGroup/MultiSPANS.
Secure Your Ride: Real-time Matching Success Rate Prediction for Passenger-Driver Pairs
Sep 14, 2021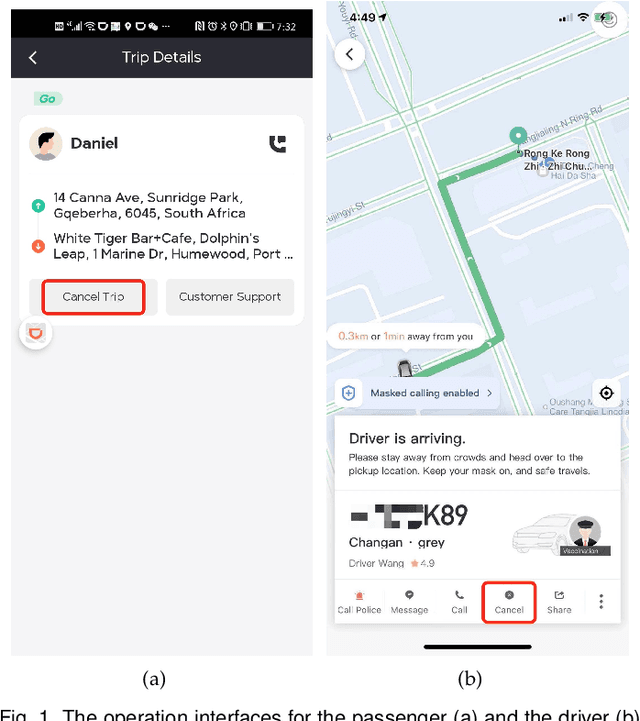

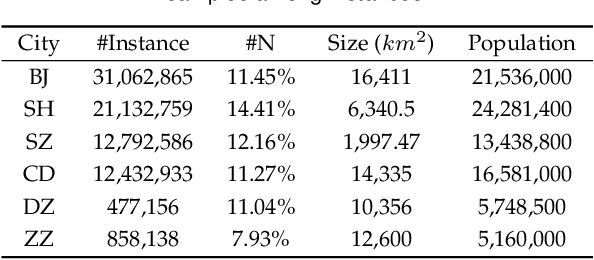
In recent years, online ride-hailing platforms have become an indispensable part of urban transportation. After a passenger is matched up with a driver by the platform, both the passenger and the driver have the freedom to simply accept or cancel a ride with one click. Hence, accurately predicting whether a passenger-driver pair is a good match turns out to be crucial for ride-hailing platforms to devise instant order assignments. However, since the users of ride-hailing platforms consist of two parties, decision-making needs to simultaneously account for the dynamics from both the driver and the passenger sides. This makes it more challenging than traditional online advertising tasks. Moreover, the amount of available data is severely imbalanced across different cities, creating difficulties for training an accurate model for smaller cities with scarce data. Though a sophisticated neural network architecture can help improve the prediction accuracy under data scarcity, the overly complex design will impede the model's capacity of delivering timely predictions in a production environment. In the paper, to accurately predict the MSR of passenger-driver, we propose the Multi-View model (MV) which comprehensively learns the interactions among the dynamic features of the passenger, driver, trip order, as well as context. Regarding the data imbalance problem, we further design the Knowledge Distillation framework (KD) to supplement the model's predictive power for smaller cities using the knowledge from cities with denser data and also generate a simple model to support efficient deployment. Finally, we conduct extensive experiments on real-world datasets from several different cities, which demonstrates the superiority of our solution.
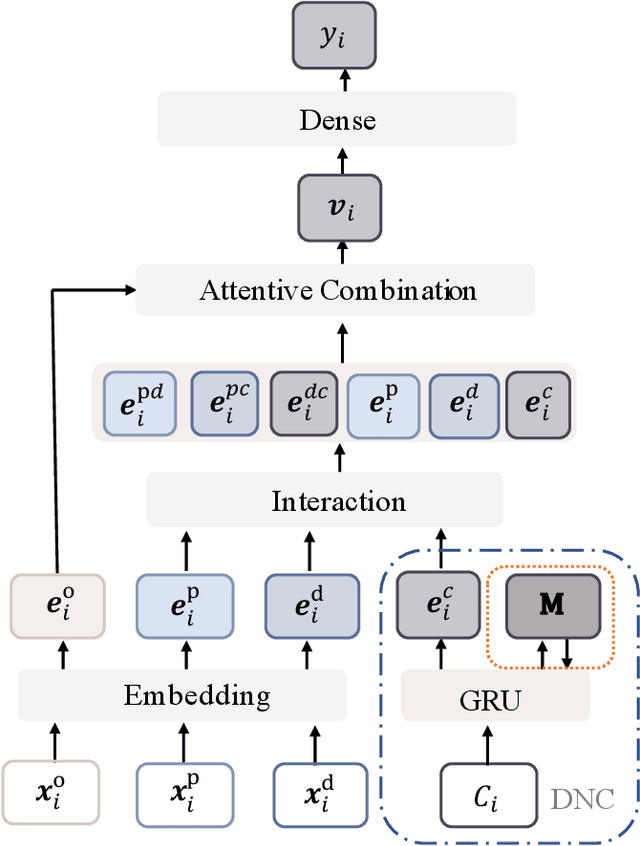
Passenger Mobility Prediction via Representation Learning for Dynamic Directed and Weighted Graph
Jan 04, 2021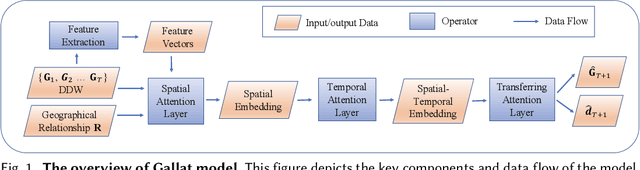
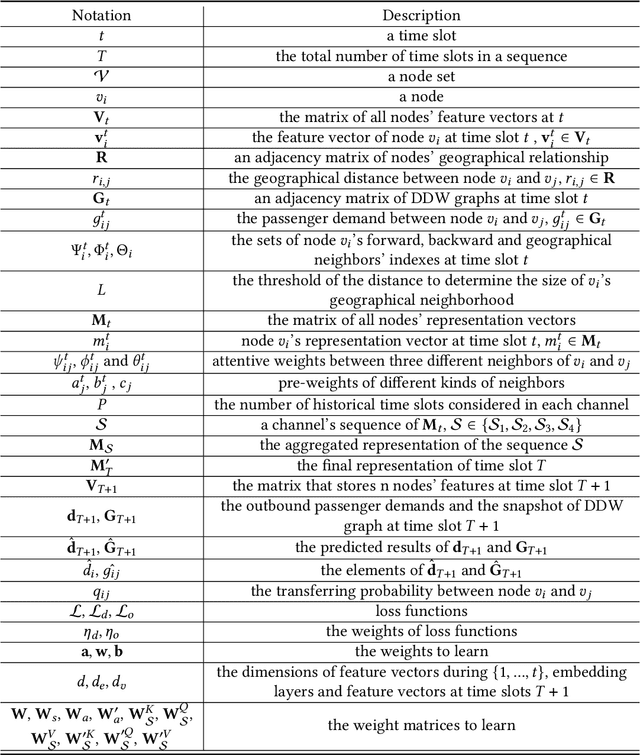
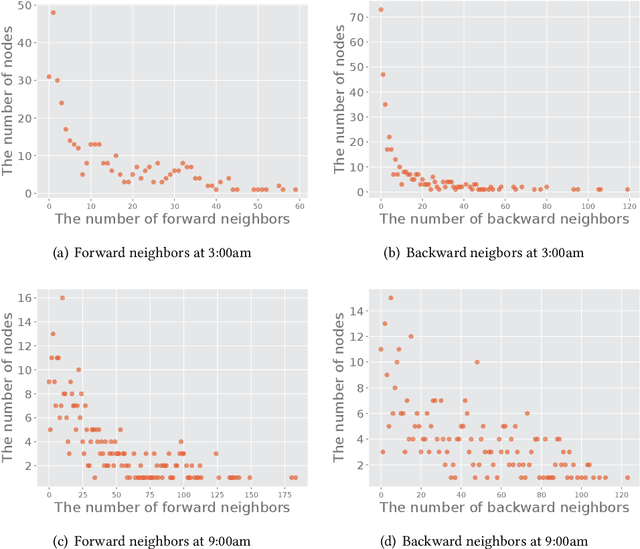
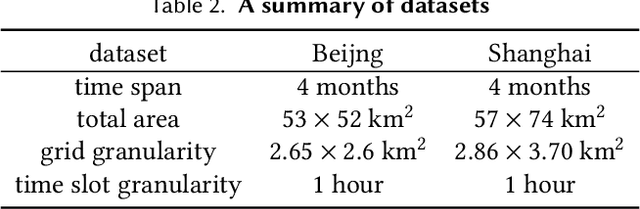
In recent years, ride-hailing services have been increasingly prevalent as they provide huge convenience for passengers. As a fundamental problem, the timely prediction of passenger demands in different regions is vital for effective traffic flow control and route planning. As both spatial and temporal patterns are indispensable passenger demand prediction, relevant research has evolved from pure time series to graph-structured data for modeling historical passenger demand data, where a snapshot graph is constructed for each time slot by connecting region nodes via different relational edges (e.g., origin-destination relationship, geographical distance, etc.). Consequently, the spatiotemporal passenger demand records naturally carry dynamic patterns in the constructed graphs, where the edges also encode important information about the directions and volume (i.e., weights) of passenger demands between two connected regions. However, existing graph-based solutions fail to simultaneously consider those three crucial aspects of dynamic, directed, and weighted (DDW) graphs, leading to limited expressiveness when learning graph representations for passenger demand prediction. Therefore, we propose a novel spatiotemporal graph attention network, namely Gallat (Graph prediction with all attention) as a solution. In Gallat, by comprehensively incorporating those three intrinsic properties of DDW graphs, we build three attention layers to fully capture the spatiotemporal dependencies among different regions across all historical time slots. Moreover, the model employs a subtask to conduct pretraining so that it can obtain accurate results more quickly. We evaluate the proposed model on real-world datasets, and our experimental results demonstrate that Gallat outperforms the state-of-the-art approaches.