 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Large Language Model-based Time Series Forecasting
Jul 28, 2025Large Language Model-based Time Series Forecasting (LLMTS) has shown remarkable promise in handling complex and diverse temporal data, representing a significant step toward foundation models for time series analysis. However, this emerging paradigm introduces two critical challenges. First, the substantial commercial potential and resource-intensive development raise urgent concerns about intellectual property (IP) protection. Second, their powerful time series forecasting capabilities may be misused to produce misleading or fabricated deepfake time series data. To address these concerns, we explore watermarking the outputs of LLMTS models, that is, embedding imperceptible signals into the generated time series data that remain detectable by specialized algorithms. We propose a novel post-hoc watermarking framework, Waltz, which is broadly compatible with existing LLMTS models. Waltz is inspired by the empirical observation that time series patch embeddings are rarely aligned with a specific set of LLM tokens, which we term ``cold tokens''. Leveraging this insight, Waltz embeds watermarks by rewiring the similarity statistics between patch embeddings and cold token embeddings, and detects watermarks using similarity z-scores. To minimize potential side effects, we introduce a similarity-based embedding position identification strategy and employ projected gradient descent to constrain the watermark noise within a defined boundary. Extensive experiments using two popular LLMTS models across seven benchmark datasets demonstrate that Waltz achieves high watermark detection accuracy with minimal impact on the quality of the generated time series.
M2Rec: Multi-scale Mamba for Efficient Sequential Recommendation
May 07, 2025Sequential recommendation systems aim to predict users' next preferences based on their interaction histories, but existing approaches face critical limitations in efficiency and multi-scale pattern recognition. While Transformer-based methods struggle with quadratic computational complexity, recent Mamba-based models improve efficiency but fail to capture periodic user behaviors, leverage rich semantic information, or effectively fuse multimodal features. To address these challenges, we propose \model, a novel sequential recommendation framework that integrates multi-scale Mamba with Fourier analysis, Large Language Models (LLMs), and adaptive gating. First, we enhance Mamba with Fast Fourier Transform (FFT) to explicitly model periodic patterns in the frequency domain, separating meaningful trends from noise. Second, we incorporate LLM-based text embeddings to enrich sparse interaction data with semantic context from item descriptions. Finally, we introduce a learnable gate mechanism to dynamically balance temporal (Mamba), frequency (FFT), and semantic (LLM) features, ensuring harmonious multimodal fusion. Extensive experiments demonstrate that \model\ achieves state-of-the-art performance, improving Hit Rate@10 by 3.2\% over existing Mamba-based models while maintaining 20\% faster inference than Transformer baselines. Our results highlight the effectiveness of combining frequency analysis, semantic understanding, and adaptive fusion for sequential recommendation. Code and datasets are available at: https://anonymous.4open.science/r/M2Rec.
Multi-agents based User Values Mining for Recommendation
May 02, 2025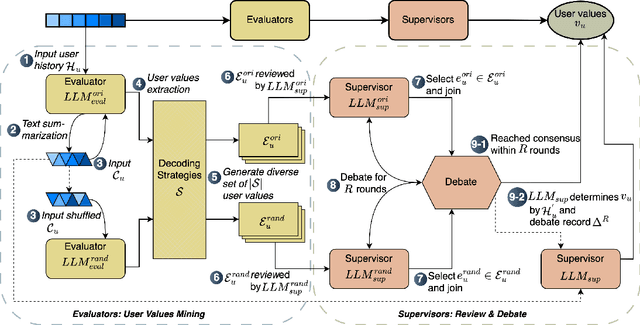

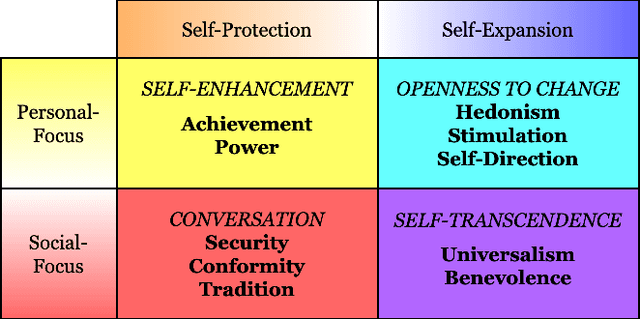
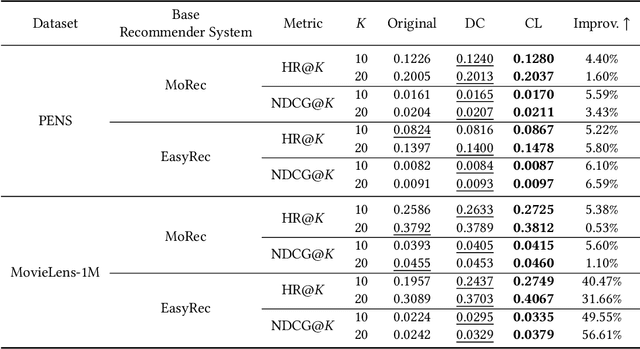
Recommender systems have rapidly evolved and become integral to many online services. However, existing systems sometimes produce unstable and unsatisfactory recommendations that fail to align with users' fundamental and long-term preferences. This is because they primarily focus on extracting shallow and short-term interests from user behavior data, which is inherently dynamic and challenging to model. Unlike these transient interests, user values are more stable and play a crucial role in shaping user behaviors, such as purchasing items and consuming content. Incorporating user values into recommender systems can help stabilize recommendation performance and ensure results better reflect users' latent preferences. However, acquiring user values is typically difficult and costly. To address this challenge, we leverage the strong language understanding, zero-shot inference, and generalization capabilities of Large Language Models (LLMs) to extract user values from users' historical interactions. Unfortunately, direct extraction using LLMs presents several challenges such as length constraints and hallucination. To overcome these issues, we propose ZOOM, a zero-shot multi-LLM collaborative framework for effective and accurate user value extraction. In ZOOM, we apply text summarization techniques to condense item content while preserving essential meaning. To mitigate hallucinations, ZOOM introduces two specialized agent roles: evaluators and supervisors, to collaboratively generate accurate user values. Extensive experiments on two widely used recommendation datasets with two state-of-the-art recommendation models demonstrate the effectiveness and generalization of our framework in automatic user value mining and recommendation performance improvement.
Memory-enhanced Invariant Prompt Learning for Urban Flow Prediction under Distribution Shifts
Dec 07, 2024



Urban flow prediction is a classic spatial-temporal forecasting task that estimates the amount of future traffic flow for a given location. Though models represented by Spatial-Temporal Graph Neural Networks (STGNNs) have established themselves as capable predictors, they tend to suffer from distribution shifts that are common with the urban flow data due to the dynamics and unpredictability of spatial-temporal events. Unfortunately, in spatial-temporal applications, the dynamic environments can hardly be quantified via a fixed number of parameters, whereas learning time- and location-specific environments can quickly become computationally prohibitive. In this paper, we propose a novel framework named Memory-enhanced Invariant Prompt learning (MIP) for urban flow prediction under constant distribution shifts. Specifically, MIP is equipped with a learnable memory bank that is trained to memorize the causal features within the spatial-temporal graph. By querying a trainable memory bank that stores the causal features, we adaptively extract invariant and variant prompts (i.e., patterns) for a given location at every time step. Then, instead of intervening the raw data based on simulated environments, we directly perform intervention on variant prompts across space and time. With the intervened variant prompts in place, we use invariant learning to minimize the variance of predictions, so as to ensure that the predictions are only made with invariant features. With extensive comparative experiments on two public urban flow datasets, we thoroughly demonstrate the robustness of MIP against OOD data.
Epidemiology-informed Graph Neural Network for Heterogeneity-aware Epidemic Forecasting
Nov 26, 2024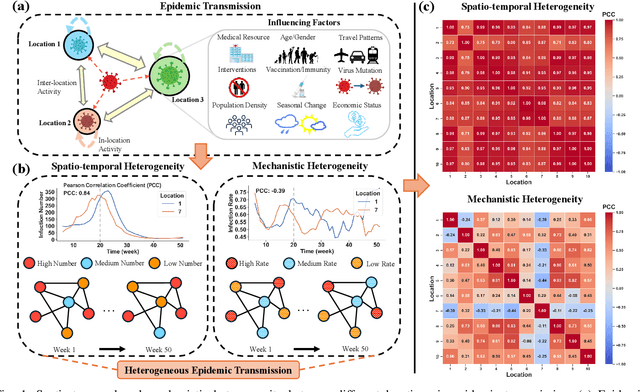
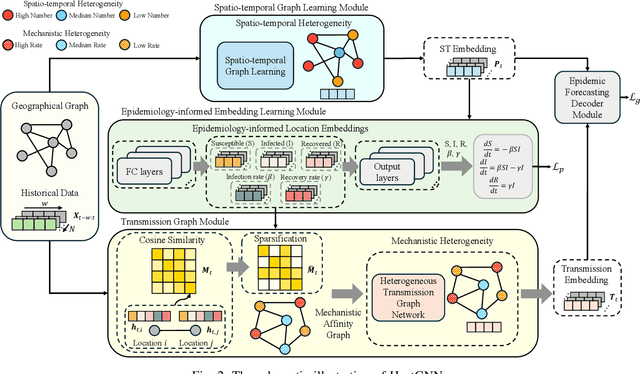
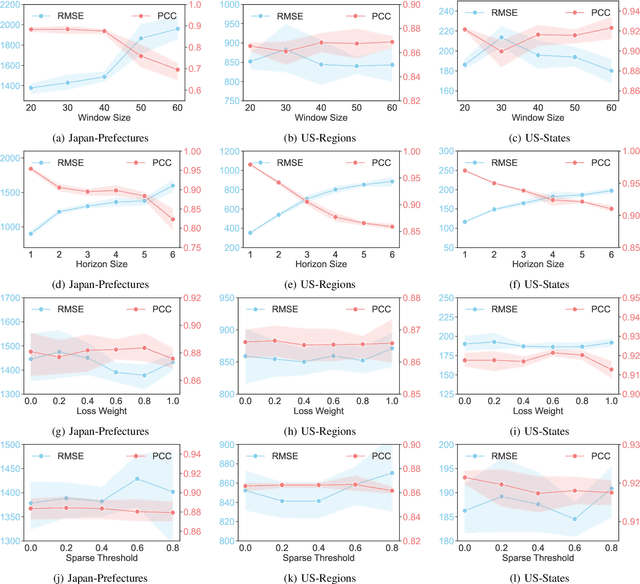
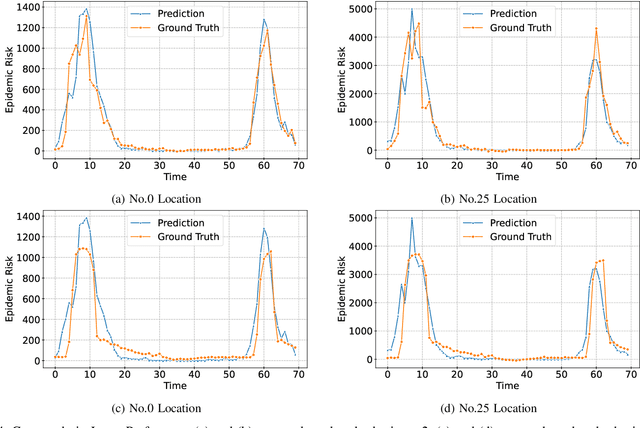
Among various spatio-temporal prediction tasks, epidemic forecasting plays a critical role in public health management. Recent studies have demonstrated the strong potential of spatio-temporal graph neural networks (STGNNs) in extracting heterogeneous spatio-temporal patterns for epidemic forecasting. However, most of these methods bear an over-simplified assumption that two locations (e.g., cities) with similar observed features in previous time steps will develop similar infection numbers in the future. In fact, for any epidemic disease, there exists strong heterogeneity of its intrinsic evolution mechanisms across geolocation and time, which can eventually lead to diverged infection numbers in two ``similar'' locations. However, such mechanistic heterogeneity is non-trivial to be captured due to the existence of numerous influencing factors like medical resource accessibility, virus mutations, mobility patterns, etc., most of which are spatio-temporal yet unreachable or even unobservable. To address this challenge, we propose a Heterogeneous Epidemic-Aware Transmission Graph Neural Network (HeatGNN), a novel epidemic forecasting framework. By binding the epidemiology mechanistic model into a GNN, HeatGNN learns epidemiology-informed location embeddings of different locations that reflect their own transmission mechanisms over time. With the time-varying mechanistic affinity graphs computed with the epidemiology-informed location embeddings, a heterogeneous transmission graph network is designed to encode the mechanistic heterogeneity among locations, providing additional predictive signals to facilitate accurate forecasting. Experiments on three benchmark datasets have revealed that HeatGNN outperforms various strong baselines. Moreover, our efficiency analysis verifies the real-world practicality of HeatGNN on datasets of different sizes.
Multi-turn Response Selection with Commonsense-enhanced Language Models
Jul 26, 2024



As a branch of advanced artificial intelligence, dialogue systems are prospering. Multi-turn response selection is a general research problem in dialogue systems. With the assistance of background information and pre-trained language models, the performance of state-of-the-art methods on this problem gains impressive improvement. However, existing studies neglect the importance of external commonsense knowledge. Hence, we design a Siamese network where a pre-trained Language model merges with a Graph neural network (SinLG). SinLG takes advantage of Pre-trained Language Models (PLMs) to catch the word correlations in the context and response candidates and utilizes a Graph Neural Network (GNN) to reason helpful common sense from an external knowledge graph. The GNN aims to assist the PLM in fine-tuning, and arousing its related memories to attain better performance. Specifically, we first extract related concepts as nodes from an external knowledge graph to construct a subgraph with the context response pair as a super node for each sample. Next, we learn two representations for the context response pair via both the PLM and GNN. A similarity loss between the two representations is utilized to transfer the commonsense knowledge from the GNN to the PLM. Then only the PLM is used to infer online so that efficiency can be guaranteed. Finally, we conduct extensive experiments on two variants of the PERSONA-CHAT dataset, which proves that our solution can not only improve the performance of the PLM but also achieve an efficient inference.
Prompt-enhanced Federated Content Representation Learning for Cross-domain Recommendation
Jan 31, 2024



Cross-domain Recommendation (CDR) as one of the effective techniques in alleviating the data sparsity issues has been widely studied in recent years. However, previous works may cause domain privacy leakage since they necessitate the aggregation of diverse domain data into a centralized server during the training process. Though several studies have conducted privacy preserving CDR via Federated Learning (FL), they still have the following limitations: 1) They need to upload users' personal information to the central server, posing the risk of leaking user privacy. 2) Existing federated methods mainly rely on atomic item IDs to represent items, which prevents them from modeling items in a unified feature space, increasing the challenge of knowledge transfer among domains. 3) They are all based on the premise of knowing overlapped users between domains, which proves impractical in real-world applications. To address the above limitations, we focus on Privacy-preserving Cross-domain Recommendation (PCDR) and propose PFCR as our solution. For Limitation 1, we develop a FL schema by exclusively utilizing users' interactions with local clients and devising an encryption method for gradient encryption. For Limitation 2, we model items in a universal feature space by their description texts. For Limitation 3, we initially learn federated content representations, harnessing the generality of natural language to establish bridges between domains. Subsequently, we craft two prompt fine-tuning strategies to tailor the pre-trained model to the target domain. Extensive experiments on two real-world datasets demonstrate the superiority of our PFCR method compared to the SOTA approaches.
Physical Trajectory Inference Attack and Defense in Decentralized POI Recommendation
Jan 26, 2024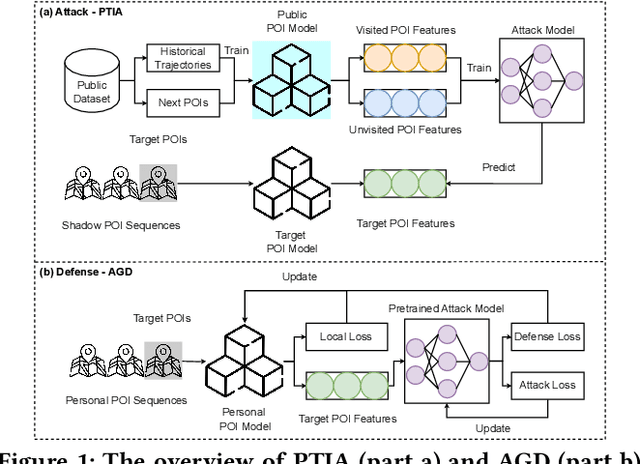
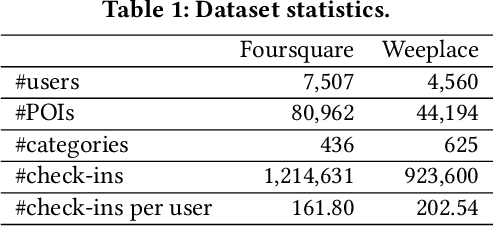
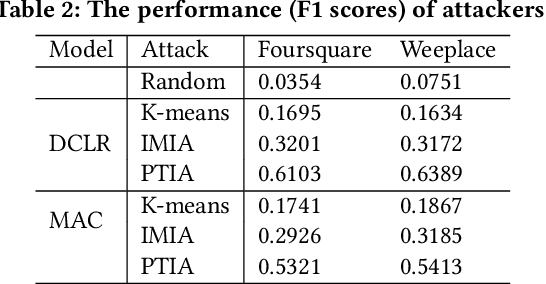
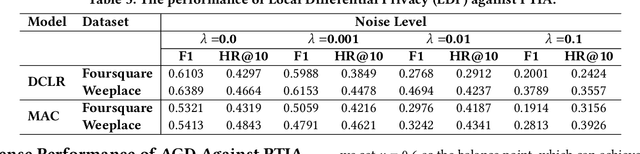
As an indispensable personalized service within Location-Based Social Networks (LBSNs), the Point-of-Interest (POI) recommendation aims to assist individuals in discovering attractive and engaging places. However, the accurate recommendation capability relies on the powerful server collecting a vast amount of users' historical check-in data, posing significant risks of privacy breaches. Although several collaborative learning (CL) frameworks for POI recommendation enhance recommendation resilience and allow users to keep personal data on-device, they still share personal knowledge to improve recommendation performance, thus leaving vulnerabilities for potential attackers. Given this, we design a new Physical Trajectory Inference Attack (PTIA) to expose users' historical trajectories. Specifically, for each user, we identify the set of interacted POIs by analyzing the aggregated information from the target POIs and their correlated POIs. We evaluate the effectiveness of PTIA on two real-world datasets across two types of decentralized CL frameworks for POI recommendation. Empirical results demonstrate that PTIA poses a significant threat to users' historical trajectories. Furthermore, Local Differential Privacy (LDP), the traditional privacy-preserving method for CL frameworks, has also been proven ineffective against PTIA. In light of this, we propose a novel defense mechanism (AGD) against PTIA based on an adversarial game to eliminate sensitive POIs and their information in correlated POIs. After conducting intensive experiments, AGD has been proven precise and practical, with minimal impact on recommendation performance.
Imbalanced Node Classification Beyond Homophilic Assumption
Apr 28, 2023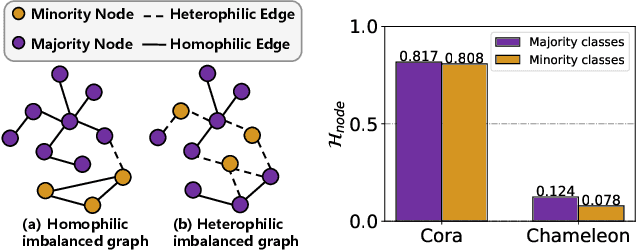
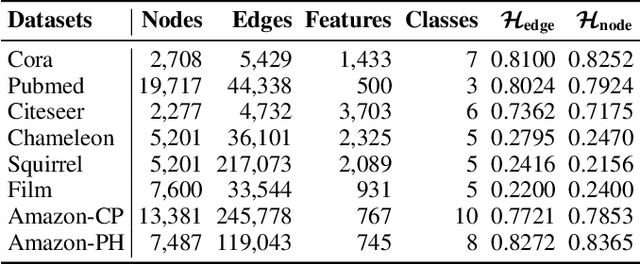
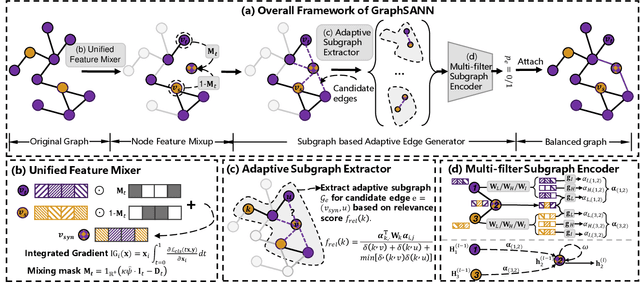
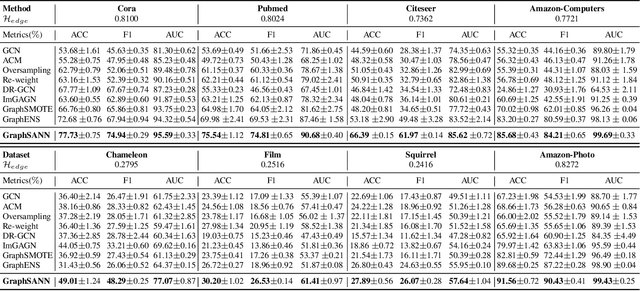
Imbalanced node classification widely exists in real-world networks where graph neural networks (GNNs) are usually highly inclined to majority classes and suffer from severe performance degradation on classifying minority class nodes. Various imbalanced node classification methods have been proposed recently which construct synthetic nodes and edges w.r.t. minority classes to balance the label and topology distribution. However, they are all based on the homophilic assumption that nodes of the same label tend to connect despite the wide existence of heterophilic edges in real-world graphs. Thus, they uniformly aggregate features from both homophilic and heterophilic neighbors and rely on feature similarity to generate synthetic edges, which cannot be applied to imbalanced graphs in high heterophily. To address this problem, we propose a novel GraphSANN for imbalanced node classification on both homophilic and heterophilic graphs. Firstly, we propose a unified feature mixer to generate synthetic nodes with both homophilic and heterophilic interpolation in a unified way. Next, by randomly sampling edges between synthetic nodes and existing nodes as candidate edges, we design an adaptive subgraph extractor to adaptively extract the contextual subgraphs of candidate edges with flexible ranges. Finally, we develop a multi-filter subgraph encoder that constructs different filter channels to discriminatively aggregate neighbor's information along the homophilic and heterophilic edges. Extensive experiments on eight datasets demonstrate the superiority of our model for imbalanced node classification on both homophilic and heterophilic graphs.
Model-Agnostic Decentralized Collaborative Learning for On-Device POI Recommendation
Apr 08, 2023
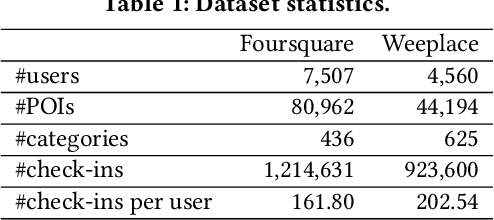
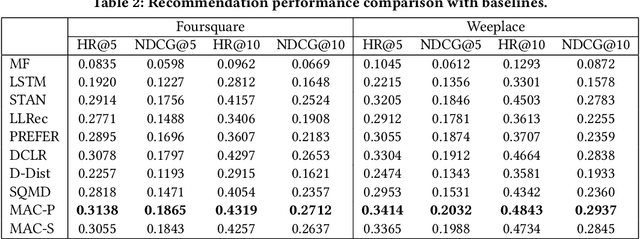
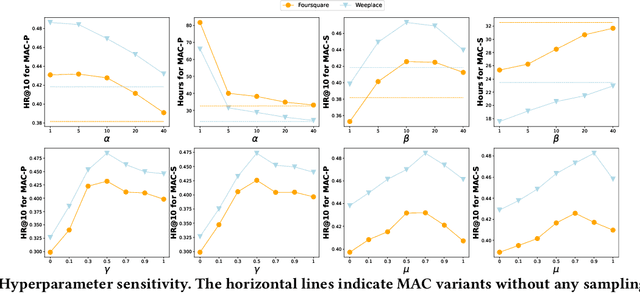
As an indispensable personalized service in Location-based Social Networks (LBSNs), the next Point-of-Interest (POI) recommendation aims to help people discover attractive and interesting places. Currently, most POI recommenders are based on the conventional centralized paradigm that heavily relies on the cloud to train the recommendation models with large volumes of collected users' sensitive check-in data. Although a few recent works have explored on-device frameworks for resilient and privacy-preserving POI recommendations, they invariably hold the assumption of model homogeneity for parameters/gradients aggregation and collaboration. However, users' mobile devices in the real world have various hardware configurations (e.g., compute resources), leading to heterogeneous on-device models with different architectures and sizes. In light of this, We propose a novel on-device POI recommendation framework, namely Model-Agnostic Collaborative learning for on-device POI recommendation (MAC), allowing users to customize their own model structures (e.g., dimension \& number of hidden layers). To counteract the sparsity of on-device user data, we propose to pre-select neighbors for collaboration based on physical distances, category-level preferences, and social networks. To assimilate knowledge from the above-selected neighbors in an efficient and secure way, we adopt the knowledge distillation framework with mutual information maximization. Instead of sharing sensitive models/gradients, clients in MAC only share their soft decisions on a preloaded reference dataset. To filter out low-quality neighbors, we propose two sampling strategies, performance-triggered sampling and similarity-based sampling, to speed up the training process and obtain optimal recommenders. In addition, we design two novel approaches to generate more effective reference datasets while protecting users' privacy.