 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCTEA: Richness-guided Co-training for Temporal Entity Alignment
May 18, 2026Temporal Entity Alignment (TEA), which aims to identify equivalent entities across Temporal Knowledge Graphs (TKGs), is crucial for integrating knowledge facts from multiple sources. However, existing TEA models often fail to capture the orthogonal yet complementary effects between structural and temporal features, and typically overlook the importance of information richness, a key factor for effective message passing in neural feature encoders. To address these limitations, we propose the RCTEA framework, which jointly models both structural and temporal aspects of TKGs for entity alignment. Specifically, we design a richness-guided attention mechanism along with an adaptive weighting strategy to facilitate effective feature fusion. To ensure robust alignment despite noisy entity contexts, we introduce a dual-view neighborhood consensus algorithm that jointly refines the feature encoders to enforce local structural consistency of the predicted alignments. Extensive experiments demonstrate the superiority of RCTEA, achieving state-of-the-art performance on public TEA benchmarks.
Evolutionary Router Feature Generation for Zero-Shot Graph Anomaly Detection with Mixture-of-Experts
Feb 12, 2026Zero-shot graph anomaly detection (GAD) has attracted increasing attention recent years, yet the heterogeneity of graph structures, features, and anomaly patterns across graphs make existing single GNN methods insufficiently expressive to model diverse anomaly mechanisms. In this regard, Mixture-of-experts (MoE) architectures provide a promising paradigm by integrating diverse GNN experts with complementary inductive biases, yet their effectiveness in zero-shot GAD is severely constrained by distribution shifts, leading to two key routing challenges. First, nodes often carry vastly different semantics across graphs, and straightforwardly performing routing based on their features is prone to generating biased or suboptimal expert assignments. Second, as anomalous graphs often exhibit pronounced distributional discrepancies, existing router designs fall short in capturing domain-invariant routing principles that generalize beyond the training graphs. To address these challenges, we propose a novel MoE framework with evolutionary router feature generation (EvoFG) for zero-shot GAD. To enhance MoE routing, we propose an evolutionary feature generation scheme that iteratively constructs and selects informative structural features via an LLM-based generator and Shapley-guided evaluation. Moreover, a memory-enhanced router with an invariant learning objective is designed to capture transferable routing patterns under distribution shifts. Extensive experiments on six benchmarks show that EvoFG consistently outperforms state-of-the-art baselines, achieving strong and stable zero-shot GAD performance.
Noise Modeling in One Hour: Minimizing Preparation Efforts for Self-supervised Low-Light RAW Image Denoising
Apr 30, 2025

Noise synthesis is a promising solution for addressing the data shortage problem in data-driven low-light RAW image denoising. However, accurate noise synthesis methods often necessitate labor-intensive calibration and profiling procedures during preparation, preventing them from landing to practice at scale. This work introduces a practically simple noise synthesis pipeline based on detailed analyses of noise properties and extensive justification of widespread techniques. Compared to other approaches, our proposed pipeline eliminates the cumbersome system gain calibration and signal-independent noise profiling steps, reducing the preparation time for noise synthesis from days to hours. Meanwhile, our method exhibits strong denoising performance, showing an up to 0.54dB PSNR improvement over the current state-of-the-art noise synthesis technique. Code is released at https://github.com/SonyResearch/raw_image_denoising
Memory-enhanced Invariant Prompt Learning for Urban Flow Prediction under Distribution Shifts
Dec 07, 2024



Urban flow prediction is a classic spatial-temporal forecasting task that estimates the amount of future traffic flow for a given location. Though models represented by Spatial-Temporal Graph Neural Networks (STGNNs) have established themselves as capable predictors, they tend to suffer from distribution shifts that are common with the urban flow data due to the dynamics and unpredictability of spatial-temporal events. Unfortunately, in spatial-temporal applications, the dynamic environments can hardly be quantified via a fixed number of parameters, whereas learning time- and location-specific environments can quickly become computationally prohibitive. In this paper, we propose a novel framework named Memory-enhanced Invariant Prompt learning (MIP) for urban flow prediction under constant distribution shifts. Specifically, MIP is equipped with a learnable memory bank that is trained to memorize the causal features within the spatial-temporal graph. By querying a trainable memory bank that stores the causal features, we adaptively extract invariant and variant prompts (i.e., patterns) for a given location at every time step. Then, instead of intervening the raw data based on simulated environments, we directly perform intervention on variant prompts across space and time. With the intervened variant prompts in place, we use invariant learning to minimize the variance of predictions, so as to ensure that the predictions are only made with invariant features. With extensive comparative experiments on two public urban flow datasets, we thoroughly demonstrate the robustness of MIP against OOD data.
Motion Blur Decomposition with Cross-shutter Guidance
Apr 01, 2024



Motion blur is a frequently observed image artifact, especially under insufficient illumination where exposure time has to be prolonged so as to collect more photons for a bright enough image. Rather than simply removing such blurring effects, recent researches have aimed at decomposing a blurry image into multiple sharp images with spatial and temporal coherence. Since motion blur decomposition itself is highly ambiguous, priors from neighbouring frames or human annotation are usually needed for motion disambiguation. In this paper, inspired by the complementary exposure characteristics of a global shutter (GS) camera and a rolling shutter (RS) camera, we propose to utilize the ordered scanline-wise delay in a rolling shutter image to robustify motion decomposition of a single blurry image. To evaluate this novel dual imaging setting, we construct a triaxial system to collect realistic data, as well as a deep network architecture that explicitly addresses temporal and contextual information through reciprocal branches for cross-shutter motion blur decomposition. Experiment results have verified the effectiveness of our proposed algorithm, as well as the validity of our dual imaging setting.
Polarized Color Image Denoising using Pocoformer
Jul 01, 2022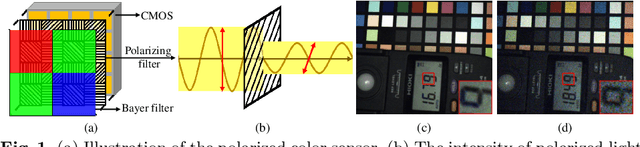


Polarized color photography provides both visual textures and object surficial information in one single snapshot. However, the use of the directional polarizing filter array causes extremely lower photon count and SNR compared to conventional color imaging. Thus, the feature essentially leads to unpleasant noisy images and destroys polarization analysis performance. It is a challenge for traditional image processing pipelines owing to the fact that the physical constraints exerted implicitly in the channels are excessively complicated. To address this issue, we propose a learning-based approach to simultaneously restore clean signals and precise polarization information. A real-world polarized color image dataset of paired raw short-exposed noisy and long-exposed reference images are captured to support the learning-based pipeline. Moreover, we embrace the development of vision Transformer and propose a hybrid transformer model for the Polarized Color image denoising, namely PoCoformer, for a better restoration performance. Abundant experiments demonstrate the effectiveness of proposed method and key factors that affect results are analyzed.
A novel approach for multi-agent cooperative pursuit to capture grouped evaders
Jun 27, 2020

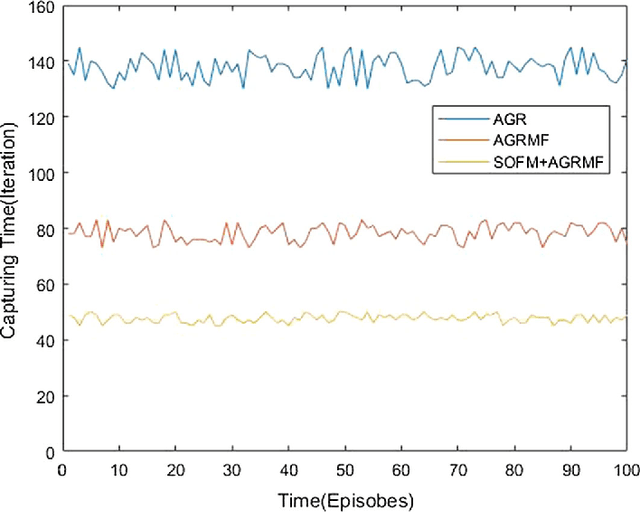
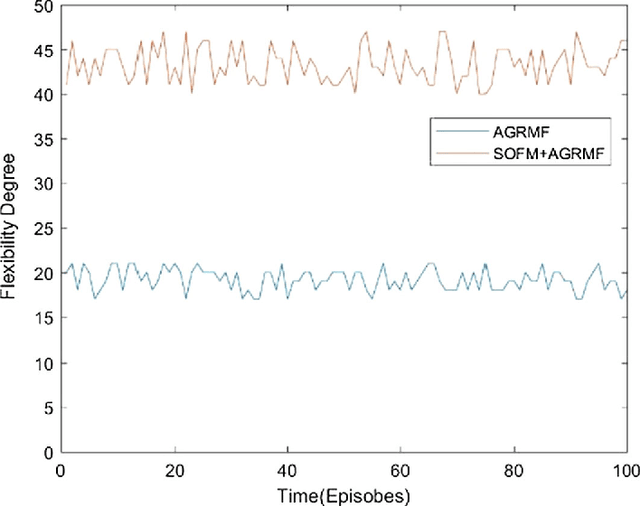
An approach of mobile multi-agent pursuit based on application of self-organizing feature map (SOFM) and along with that reinforcement learning based on agent group role membership function (AGRMF) model is proposed. This method promotes dynamic organization of the pursuers' groups and also makes pursuers' group evader according to their desire based on SOFM and AGRMF techniques. This helps to overcome the shortcomings of the pursuers that they cannot fully reorganize when the goal is too independent in process of AGRMF models operation. Besides, we also discuss a new reward function. After the formation of the group, reinforcement learning is applied to get the optimal solution for each agent. The results of each step in capturing process will finally affect the AGR membership function to speed up the convergence of the competitive neural network. The experiments result shows that this approach is more effective for the mobile agents to capture evaders.
* published paper's draft version