 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA novel approach for multi-agent cooperative pursuit to capture grouped evaders
Jun 27, 2020

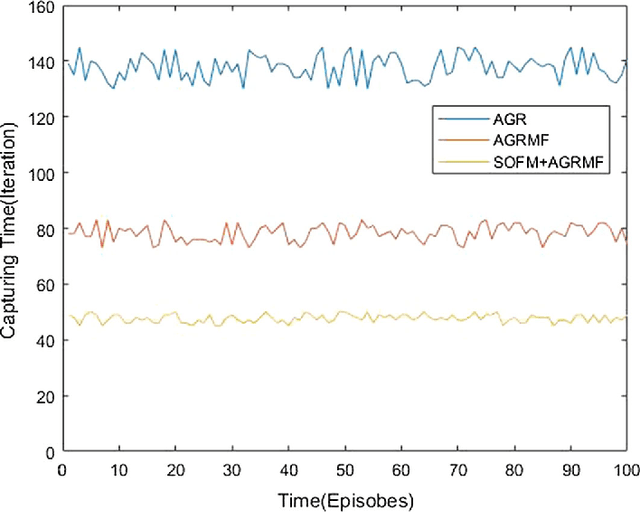
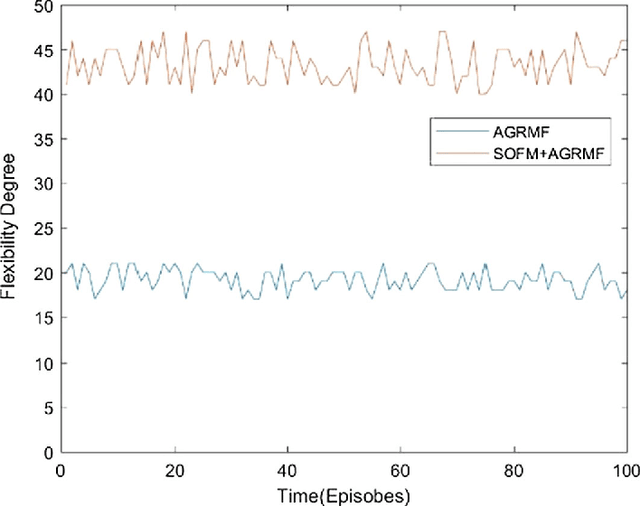
An approach of mobile multi-agent pursuit based on application of self-organizing feature map (SOFM) and along with that reinforcement learning based on agent group role membership function (AGRMF) model is proposed. This method promotes dynamic organization of the pursuers' groups and also makes pursuers' group evader according to their desire based on SOFM and AGRMF techniques. This helps to overcome the shortcomings of the pursuers that they cannot fully reorganize when the goal is too independent in process of AGRMF models operation. Besides, we also discuss a new reward function. After the formation of the group, reinforcement learning is applied to get the optimal solution for each agent. The results of each step in capturing process will finally affect the AGR membership function to speed up the convergence of the competitive neural network. The experiments result shows that this approach is more effective for the mobile agents to capture evaders.
* published paper's draft version
Active collaboration in relative observation for Multi-agent visual SLAM based on Deep Q Network
Sep 23, 2019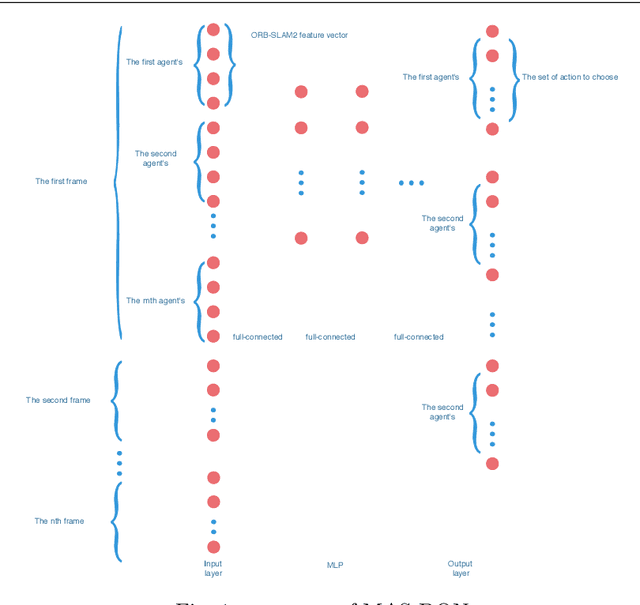

This paper proposes a unique active relative localization mechanism for multi-agent Simultaneous Localization and Mapping(SLAM),in which a agent to be observed are considered as a task, which is performed by others assisting that agent by relative observation. A task allocation algorithm based on deep reinforcement learning are proposed for this mechanism. Each agent can choose whether to localize other agents or to continue independent SLAM on it own initiative. By this way, the process of each agent SLAM will be interacted by the collaboration. Firstly, based on the characteristics of ORBSLAM, a unique observation function which models the whole MAS is obtained. Secondly, a novel type of Deep Q network(DQN) called MAS-DQN is deployed to learn correspondence between Q Value and state-action pair,abstract representation of agents in MAS are learned in the process of collaboration among agents. Finally, each agent must act with a certain degree of freedom according to MAS-DQN. The simulation results of comparative experiments prove that this mechanism improves the efficiency of cooperation in the process of multi-agent SLAM.