 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape of Thought: Progressive Object Assembly via Visual Chain-of-Thought
Jan 28, 2026Multimodal models for text-to-image generation have achieved strong visual fidelity, yet they remain brittle under compositional structural constraints-notably generative numeracy, attribute binding, and part-level relations. To address these challenges, we propose Shape-of-Thought (SoT), a visual CoT framework that enables progressive shape assembly via coherent 2D projections without external engines at inference time. SoT trains a unified multimodal autoregressive model to generate interleaved textual plans and rendered intermediate states, helping the model capture shape-assembly logic without producing explicit geometric representations. To support this paradigm, we introduce SoT-26K, a large-scale dataset of grounded assembly traces derived from part-based CAD hierarchies, and T2S-CompBench, a benchmark for evaluating structural integrity and trace faithfulness. Fine-tuning on SoT-26K achieves 88.4% on component numeracy and 84.8% on structural topology, outperforming text-only baselines by around 20%. SoT establishes a new paradigm for transparent, process-supervised compositional generation. The code is available at https://anonymous.4open.science/r/16FE/. The SoT-26K dataset will be released upon acceptance.
DreamLight: Towards Harmonious and Consistent Image Relighting
Jun 17, 2025We introduce a model named DreamLight for universal image relighting in this work, which can seamlessly composite subjects into a new background while maintaining aesthetic uniformity in terms of lighting and color tone. The background can be specified by natural images (image-based relighting) or generated from unlimited text prompts (text-based relighting). Existing studies primarily focus on image-based relighting, while with scant exploration into text-based scenarios. Some works employ intricate disentanglement pipeline designs relying on environment maps to provide relevant information, which grapples with the expensive data cost required for intrinsic decomposition and light source. Other methods take this task as an image translation problem and perform pixel-level transformation with autoencoder architecture. While these methods have achieved decent harmonization effects, they struggle to generate realistic and natural light interaction effects between the foreground and background. To alleviate these challenges, we reorganize the input data into a unified format and leverage the semantic prior provided by the pretrained diffusion model to facilitate the generation of natural results. Moreover, we propose a Position-Guided Light Adapter (PGLA) that condenses light information from different directions in the background into designed light query embeddings, and modulates the foreground with direction-biased masked attention. In addition, we present a post-processing module named Spectral Foreground Fixer (SFF) to adaptively reorganize different frequency components of subject and relighted background, which helps enhance the consistency of foreground appearance. Extensive comparisons and user study demonstrate that our DreamLight achieves remarkable relighting performance.
Tuning-Free Long Video Generation via Global-Local Collaborative Diffusion
Jan 08, 2025



Creating high-fidelity, coherent long videos is a sought-after aspiration. While recent video diffusion models have shown promising potential, they still grapple with spatiotemporal inconsistencies and high computational resource demands. We propose GLC-Diffusion, a tuning-free method for long video generation. It models the long video denoising process by establishing denoising trajectories through Global-Local Collaborative Denoising to ensure overall content consistency and temporal coherence between frames. Additionally, we introduce a Noise Reinitialization strategy which combines local noise shuffling with frequency fusion to improve global content consistency and visual diversity. Further, we propose a Video Motion Consistency Refinement (VMCR) module that computes the gradient of pixel-wise and frequency-wise losses to enhance visual consistency and temporal smoothness. Extensive experiments, including quantitative and qualitative evaluations on videos of varying lengths (\textit{e.g.}, 3\times and 6\times longer), demonstrate that our method effectively integrates with existing video diffusion models, producing coherent, high-fidelity long videos superior to previous approaches.
Flatten: Video Action Recognition is an Image Classification task
Aug 17, 2024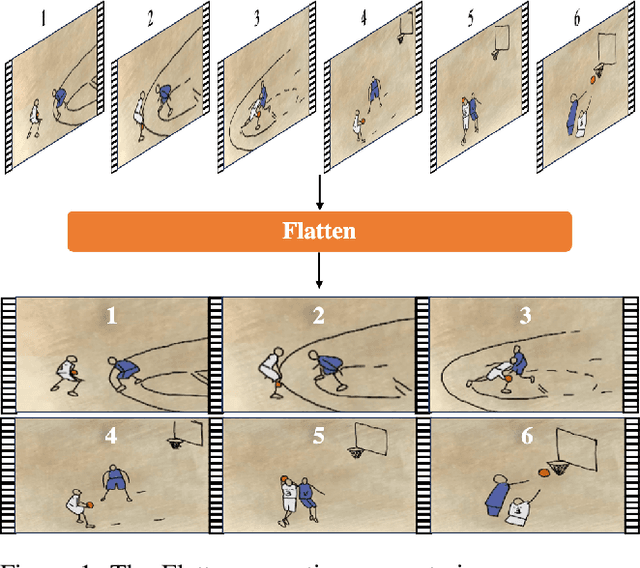
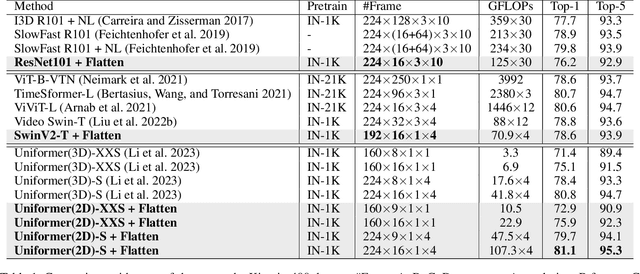
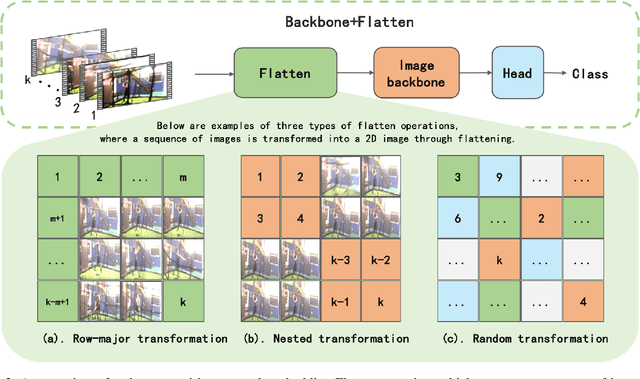
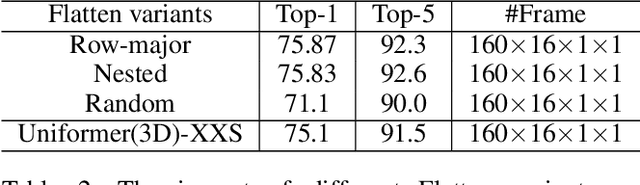
In recent years, video action recognition, as a fundamental task in the field of video understanding, has been deeply explored by numerous researchers.Most traditional video action recognition methods typically involve converting videos into three-dimensional data that encapsulates both spatial and temporal information, subsequently leveraging prevalent image understanding models to model and analyze these data. However,these methods have significant drawbacks. Firstly, when delving into video action recognition tasks, image understanding models often need to be adapted accordingly in terms of model architecture and preprocessing for these spatiotemporal tasks; Secondly, dealing with high-dimensional data often poses greater challenges and incurs higher time costs compared to its lower-dimensional counterparts.To bridge the gap between image-understanding and video-understanding tasks while simplifying the complexity of video comprehension, we introduce a novel video representation architecture, Flatten, which serves as a plug-and-play module that can be seamlessly integrated into any image-understanding network for efficient and effective 3D temporal data modeling.Specifically, by applying specific flattening operations (e.g., row-major transform), 3D spatiotemporal data is transformed into 2D spatial information, and then ordinary image understanding models are used to capture temporal dynamic and spatial semantic information, which in turn accomplishes effective and efficient video action recognition. Extensive experiments on commonly used datasets (Kinetics-400, Something-Something v2, and HMDB-51) and three classical image classification models (Uniformer, SwinV2, and ResNet), have demonstrated that embedding Flatten provides a significant performance improvements over original model.