 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation Equivariant Arbitrary-scale Image Super-Resolution
Aug 07, 2025The arbitrary-scale image super-resolution (ASISR), a recent popular topic in computer vision, aims to achieve arbitrary-scale high-resolution recoveries from a low-resolution input image. This task is realized by representing the image as a continuous implicit function through two fundamental modules, a deep-network-based encoder and an implicit neural representation (INR) module. Despite achieving notable progress, a crucial challenge of such a highly ill-posed setting is that many common geometric patterns, such as repetitive textures, edges, or shapes, are seriously warped and deformed in the low-resolution images, naturally leading to unexpected artifacts appearing in their high-resolution recoveries. Embedding rotation equivariance into the ASISR network is thus necessary, as it has been widely demonstrated that this enhancement enables the recovery to faithfully maintain the original orientations and structural integrity of geometric patterns underlying the input image. Motivated by this, we make efforts to construct a rotation equivariant ASISR method in this study. Specifically, we elaborately redesign the basic architectures of INR and encoder modules, incorporating intrinsic rotation equivariance capabilities beyond those of conventional ASISR networks. Through such amelioration, the ASISR network can, for the first time, be implemented with end-to-end rotational equivariance maintained from input to output. We also provide a solid theoretical analysis to evaluate its intrinsic equivariance error, demonstrating its inherent nature of embedding such an equivariance structure. The superiority of the proposed method is substantiated by experiments conducted on both simulated and real datasets. We also validate that the proposed framework can be readily integrated into current ASISR methods in a plug \& play manner to further enhance their performance.
DUN-SRE: Deep Unrolling Network with Spatiotemporal Rotation Equivariance for Dynamic MRI Reconstruction
Jun 12, 2025Dynamic Magnetic Resonance Imaging (MRI) exhibits transformation symmetries, including spatial rotation symmetry within individual frames and temporal symmetry along the time dimension. Explicit incorporation of these symmetry priors in the reconstruction model can significantly improve image quality, especially under aggressive undersampling scenarios. Recently, Equivariant convolutional neural network (ECNN) has shown great promise in exploiting spatial symmetry priors. However, existing ECNNs critically fail to model temporal symmetry, arguably the most universal and informative structural prior in dynamic MRI reconstruction. To tackle this issue, we propose a novel Deep Unrolling Network with Spatiotemporal Rotation Equivariance (DUN-SRE) for Dynamic MRI Reconstruction. The DUN-SRE establishes spatiotemporal equivariance through a (2+1)D equivariant convolutional architecture. In particular, it integrates both the data consistency and proximal mapping module into a unified deep unrolling framework. This architecture ensures rigorous propagation of spatiotemporal rotation symmetry constraints throughout the reconstruction process, enabling more physically accurate modeling of cardiac motion dynamics in cine MRI. In addition, a high-fidelity group filter parameterization mechanism is developed to maintain representation precision while enforcing symmetry constraints. Comprehensive experiments on Cardiac CINE MRI datasets demonstrate that DUN-SRE achieves state-of-the-art performance, particularly in preserving rotation-symmetric structures, offering strong generalization capability to a broad range of dynamic MRI reconstruction tasks.
Rotation-Equivariant Self-Supervised Method in Image Denoising
May 26, 2025Self-supervised image denoising methods have garnered significant research attention in recent years, for this kind of method reduces the requirement of large training datasets. Compared to supervised methods, self-supervised methods rely more on the prior embedded in deep networks themselves. As a result, most of the self-supervised methods are designed with Convolution Neural Networks (CNNs) architectures, which well capture one of the most important image prior, translation equivariant prior. Inspired by the great success achieved by the introduction of translational equivariance, in this paper, we explore the way to further incorporate another important image prior. Specifically, we first apply high-accuracy rotation equivariant convolution to self-supervised image denoising. Through rigorous theoretical analysis, we have proved that simply replacing all the convolution layers with rotation equivariant convolution layers would modify the network into its rotation equivariant version. To the best of our knowledge, this is the first time that rotation equivariant image prior is introduced to self-supervised image denoising at the network architecture level with a comprehensive theoretical analysis of equivariance errors, which offers a new perspective to the field of self-supervised image denoising. Moreover, to further improve the performance, we design a new mask mechanism to fusion the output of rotation equivariant network and vanilla CNN-based network, and construct an adaptive rotation equivariant framework. Through extensive experiments on three typical methods, we have demonstrated the effectiveness of the proposed method.
A Regularization-Guided Equivariant Approach for Image Restoration
May 26, 2025Equivariant and invariant deep learning models have been developed to exploit intrinsic symmetries in data, demonstrating significant effectiveness in certain scenarios. However, these methods often suffer from limited representation accuracy and rely on strict symmetry assumptions that may not hold in practice. These limitations pose a significant drawback for image restoration tasks, which demands high accuracy and precise symmetry representation. To address these challenges, we propose a rotation-equivariant regularization strategy that adaptively enforces the appropriate symmetry constraints on the data while preserving the network's representational accuracy. Specifically, we introduce EQ-Reg, a regularizer designed to enhance rotation equivariance, which innovatively extends the insights of data-augmentation-based and equivariant-based methodologies. This is achieved through self-supervised learning and the spatial rotation and cyclic channel shift of feature maps deduce in the equivariant framework. Our approach firstly enables a non-strictly equivariant network suitable for image restoration, providing a simple and adaptive mechanism for adjusting equivariance based on task. Extensive experiments across three low-level tasks demonstrate the superior accuracy and generalization capability of our method, outperforming state-of-the-art approaches.
Continuous Filtered Backprojection by Learnable Interpolation Network
May 03, 2025Accurate reconstruction of computed tomography (CT) images is crucial in medical imaging field. However, there are unavoidable interpolation errors in the backprojection step of the conventional reconstruction methods, i.e., filtered-back-projection based methods, which are detrimental to the accurate reconstruction. In this study, to address this issue, we propose a novel deep learning model, named Leanable-Interpolation-based FBP or LInFBP shortly, to enhance the reconstructed CT image quality, which achieves learnable interpolation in the backprojection step of filtered backprojection (FBP) and alleviates the interpolation errors. Specifically, in the proposed LInFBP, we formulate every local piece of the latent continuous function of discrete sinogram data as a linear combination of selected basis functions, and learn this continuous function by exploiting a deep network to predict the linear combination coefficients. Then, the learned latent continuous function is exploited for interpolation in backprojection step, which first time takes the advantage of deep learning for the interpolation in FBP. Extensive experiments, which encompass diverse CT scenarios, demonstrate the effectiveness of the proposed LInFBP in terms of enhanced reconstructed image quality, plug-and-play ability and generalization capability.
Feature Alignment with Equivariant Convolutions for Burst Image Super-Resolution
Mar 11, 2025Burst image processing (BIP), which captures and integrates multiple frames into a single high-quality image, is widely used in consumer cameras. As a typical BIP task, Burst Image Super-Resolution (BISR) has achieved notable progress through deep learning in recent years. Existing BISR methods typically involve three key stages: alignment, upsampling, and fusion, often in varying orders and implementations. Among these stages, alignment is particularly critical for ensuring accurate feature matching and further reconstruction. However, existing methods often rely on techniques such as deformable convolutions and optical flow to realize alignment, which either focus only on local transformations or lack theoretical grounding, thereby limiting their performance. To alleviate these issues, we propose a novel framework for BISR, featuring an equivariant convolution-based alignment, ensuring consistent transformations between the image and feature domains. This enables the alignment transformation to be learned via explicit supervision in the image domain and easily applied in the feature domain in a theoretically sound way, effectively improving alignment accuracy. Additionally, we design an effective reconstruction module with advanced deep architectures for upsampling and fusion to obtain the final BISR result. Extensive experiments on BISR benchmarks show the superior performance of our approach in both quantitative metrics and visual quality.
Tuning-Free Long Video Generation via Global-Local Collaborative Diffusion
Jan 08, 2025



Creating high-fidelity, coherent long videos is a sought-after aspiration. While recent video diffusion models have shown promising potential, they still grapple with spatiotemporal inconsistencies and high computational resource demands. We propose GLC-Diffusion, a tuning-free method for long video generation. It models the long video denoising process by establishing denoising trajectories through Global-Local Collaborative Denoising to ensure overall content consistency and temporal coherence between frames. Additionally, we introduce a Noise Reinitialization strategy which combines local noise shuffling with frequency fusion to improve global content consistency and visual diversity. Further, we propose a Video Motion Consistency Refinement (VMCR) module that computes the gradient of pixel-wise and frequency-wise losses to enhance visual consistency and temporal smoothness. Extensive experiments, including quantitative and qualitative evaluations on videos of varying lengths (\textit{e.g.}, 3\times and 6\times longer), demonstrate that our method effectively integrates with existing video diffusion models, producing coherent, high-fidelity long videos superior to previous approaches.
M2Diffuser: Diffusion-based Trajectory Optimization for Mobile Manipulation in 3D Scenes
Oct 15, 2024



Recent advances in diffusion models have opened new avenues for research into embodied AI agents and robotics. Despite significant achievements in complex robotic locomotion and skills, mobile manipulation-a capability that requires the coordination of navigation and manipulation-remains a challenge for generative AI techniques. This is primarily due to the high-dimensional action space, extended motion trajectories, and interactions with the surrounding environment. In this paper, we introduce M2Diffuser, a diffusion-based, scene-conditioned generative model that directly generates coordinated and efficient whole-body motion trajectories for mobile manipulation based on robot-centric 3D scans. M2Diffuser first learns trajectory-level distributions from mobile manipulation trajectories provided by an expert planner. Crucially, it incorporates an optimization module that can flexibly accommodate physical constraints and task objectives, modeled as cost and energy functions, during the inference process. This enables the reduction of physical violations and execution errors at each denoising step in a fully differentiable manner. Through benchmarking on three types of mobile manipulation tasks across over 20 scenes, we demonstrate that M2Diffuser outperforms state-of-the-art neural planners and successfully transfers the generated trajectories to a real-world robot. Our evaluations underscore the potential of generative AI to enhance the generalization of traditional planning and learning-based robotic methods, while also highlighting the critical role of enforcing physical constraints for safe and robust execution.
PR2: A Physics- and Photo-realistic Testbed for Embodied AI and Humanoid Robots
Sep 03, 2024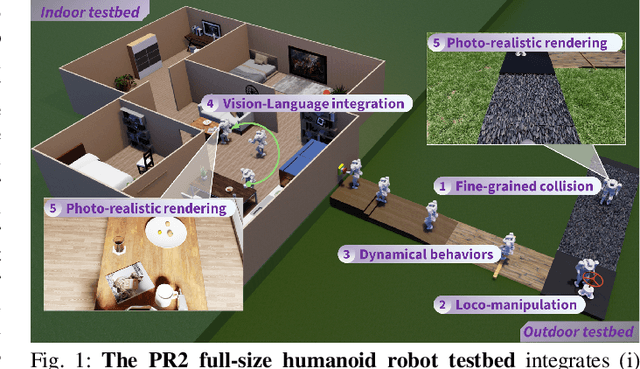



This paper presents the development of a Physics-realistic and Photo-\underline{r}ealistic humanoid robot testbed, PR2, to facilitate collaborative research between Embodied Artificial Intelligence (Embodied AI) and robotics. PR2 offers high-quality scene rendering and robot dynamic simulation, enabling (i) the creation of diverse scenes using various digital assets, (ii) the integration of advanced perception or foundation models, and (iii) the implementation of planning and control algorithms for dynamic humanoid robot behaviors based on environmental feedback. The beta version of PR2 has been deployed for the simulation track of a nationwide full-size humanoid robot competition for college students, attracting 137 teams and over 400 participants within four months. This competition covered traditional tasks in bipedal walking, as well as novel challenges in loco-manipulation and language-instruction-based object search, marking a first for public college robotics competitions. A retrospective analysis of the competition suggests that future events should emphasize the integration of locomotion with manipulation and perception. By making the PR2 testbed publicly available at https://github.com/pr2-humanoid/PR2-Platform, we aim to further advance education and training in humanoid robotics.
TRG-Net: An Interpretable and Controllable Rain Generator
Mar 15, 2024Exploring and modeling rain generation mechanism is critical for augmenting paired data to ease training of rainy image processing models. Against this task, this study proposes a novel deep learning based rain generator, which fully takes the physical generation mechanism underlying rains into consideration and well encodes the learning of the fundamental rain factors (i.e., shape, orientation, length, width and sparsity) explicitly into the deep network. Its significance lies in that the generator not only elaborately design essential elements of the rain to simulate expected rains, like conventional artificial strategies, but also finely adapt to complicated and diverse practical rainy images, like deep learning methods. By rationally adopting filter parameterization technique, we first time achieve a deep network that is finely controllable with respect to rain factors and able to learn the distribution of these factors purely from data. Our unpaired generation experiments demonstrate that the rain generated by the proposed rain generator is not only of higher quality, but also more effective for deraining and downstream tasks compared to current state-of-the-art rain generation methods. Besides, the paired data augmentation experiments, including both in-distribution and out-of-distribution (OOD), further validate the diversity of samples generated by our model for in-distribution deraining and OOD generalization tasks.