 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2Diffuser: Diffusion-based Trajectory Optimization for Mobile Manipulation in 3D Scenes
Oct 15, 2024



Recent advances in diffusion models have opened new avenues for research into embodied AI agents and robotics. Despite significant achievements in complex robotic locomotion and skills, mobile manipulation-a capability that requires the coordination of navigation and manipulation-remains a challenge for generative AI techniques. This is primarily due to the high-dimensional action space, extended motion trajectories, and interactions with the surrounding environment. In this paper, we introduce M2Diffuser, a diffusion-based, scene-conditioned generative model that directly generates coordinated and efficient whole-body motion trajectories for mobile manipulation based on robot-centric 3D scans. M2Diffuser first learns trajectory-level distributions from mobile manipulation trajectories provided by an expert planner. Crucially, it incorporates an optimization module that can flexibly accommodate physical constraints and task objectives, modeled as cost and energy functions, during the inference process. This enables the reduction of physical violations and execution errors at each denoising step in a fully differentiable manner. Through benchmarking on three types of mobile manipulation tasks across over 20 scenes, we demonstrate that M2Diffuser outperforms state-of-the-art neural planners and successfully transfers the generated trajectories to a real-world robot. Our evaluations underscore the potential of generative AI to enhance the generalization of traditional planning and learning-based robotic methods, while also highlighting the critical role of enforcing physical constraints for safe and robust execution.
M3Bench: Benchmarking Whole-body Motion Generation for Mobile Manipulation in 3D Scenes
Oct 15, 2024



We propose M^3Bench, a new benchmark of whole-body motion generation for mobile manipulation tasks. Given a 3D scene context, M^3Bench requires an embodied agent to understand its configuration, environmental constraints and task objectives, then generate coordinated whole-body motion trajectories for object rearrangement tasks. M^3Bench features 30k object rearrangement tasks across 119 diverse scenes, providing expert demonstrations generated by our newly developed M^3BenchMaker. This automatic data generation tool produces coordinated whole-body motion trajectories from high-level task instructions, requiring only basic scene and robot information. Our benchmark incorporates various task splits to assess generalization across different dimensions and leverages realistic physics simulation for trajectory evaluation. Through extensive experimental analyses, we reveal that state-of-the-art models still struggle with coordinated base-arm motion while adhering to environment-context and task-specific constraints, highlighting the need to develop new models that address this gap. Through M^3Bench, we aim to facilitate future robotics research towards more adaptive and capable mobile manipulation in diverse, real-world environments.
M${}^{3}$Bench: Benchmarking Whole-body Motion Generation for Mobile Manipulation in 3D Scenes
Oct 09, 2024We propose M^3Bench, a new benchmark for whole-body motion generation for mobile manipulation tasks. Given a 3D scene context, M^3Bench requires an embodied agent to understand its configuration, environmental constraints and task objectives, then generate coordinated whole-body motion trajectories for object rearrangement tasks. M^3Bench features 30k object rearrangement tasks across 119 diverse scenes, providing expert demonstrations generated by our newly developed M^3BenchMaker. This automatic data generation tool produces coordinated whole-body motion trajectories from high-level task instructions, requiring only basic scene and robot information. Our benchmark incorporates various task splits to assess generalization across different dimensions and leverages realistic physics simulation for trajectory evaluation. Through extensive experimental analyses, we reveal that state-of-the-art models still struggle with coordinated base-arm motion while adhering to environment-context and task-specific constraints, highlighting the need to develop new models that address this gap. Through M^3Bench, we aim to facilitate future robotics research towards more adaptive and capable mobile manipulation in diverse, real-world environments.
InterPreT: Interactive Predicate Learning from Language Feedback for Generalizable Task Planning
May 30, 2024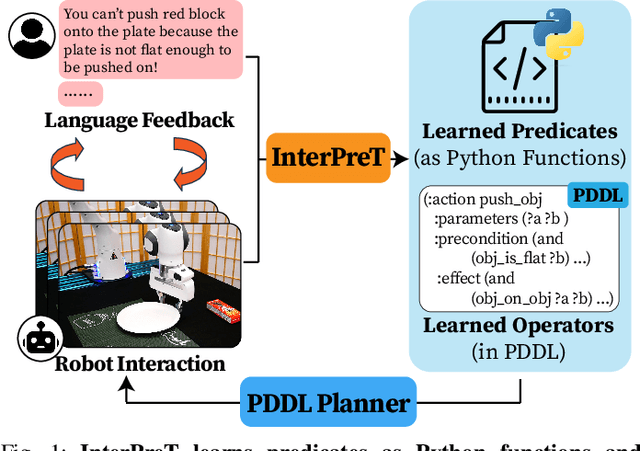
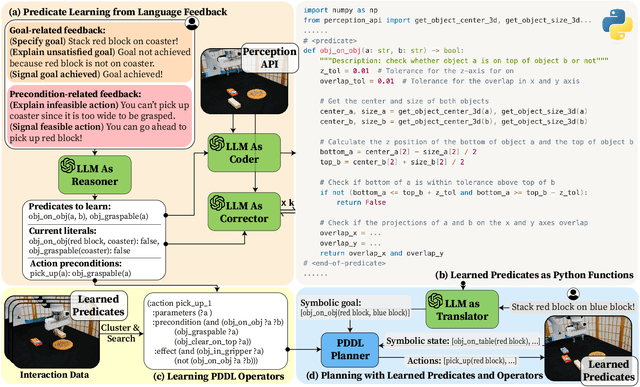
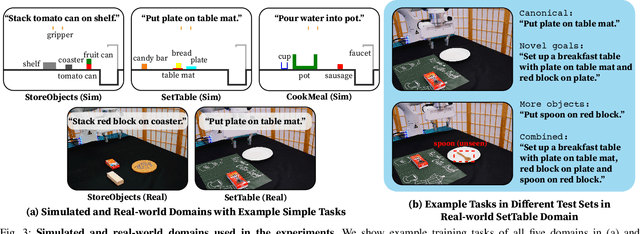

Learning abstract state representations and knowledge is crucial for long-horizon robot planning. We present InterPreT, an LLM-powered framework for robots to learn symbolic predicates from language feedback of human non-experts during embodied interaction. The learned predicates provide relational abstractions of the environment state, facilitating the learning of symbolic operators that capture action preconditions and effects. By compiling the learned predicates and operators into a PDDL domain on-the-fly, InterPreT allows effective planning toward arbitrary in-domain goals using a PDDL planner. In both simulated and real-world robot manipulation domains, we demonstrate that InterPreT reliably uncovers the key predicates and operators governing the environment dynamics. Although learned from simple training tasks, these predicates and operators exhibit strong generalization to novel tasks with significantly higher complexity. In the most challenging generalization setting, InterPreT attains success rates of 73% in simulation and 40% in the real world, substantially outperforming baseline methods.
Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations
Apr 26, 2024



Autonomous robotic systems capable of learning novel manipulation tasks are poised to transform industries from manufacturing to service automation. However, modern methods (e.g., VIP and R3M) still face significant hurdles, notably the domain gap among robotic embodiments and the sparsity of successful task executions within specific action spaces, resulting in misaligned and ambiguous task representations. We introduce Ag2Manip (Agent-Agnostic representations for Manipulation), a framework aimed at surmounting these challenges through two key innovations: a novel agent-agnostic visual representation derived from human manipulation videos, with the specifics of embodiments obscured to enhance generalizability; and an agent-agnostic action representation abstracting a robot's kinematics to a universal agent proxy, emphasizing crucial interactions between end-effector and object. Ag2Manip's empirical validation across simulated benchmarks like FrankaKitchen, ManiSkill, and PartManip shows a 325% increase in performance, achieved without domain-specific demonstrations. Ablation studies underline the essential contributions of the visual and action representations to this success. Extending our evaluations to the real world, Ag2Manip significantly improves imitation learning success rates from 50% to 77.5%, demonstrating its effectiveness and generalizability across both simulated and physical environments.
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Apr 16, 2024



Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. We present COME-robot, the first closed-loop framework utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. We meticulously construct a library of action primitives for robot exploration, navigation, and manipulation, serving as callable execution modules for GPT-4V in task planning. On top of these modules, GPT-4V serves as the brain that can accomplish multimodal reasoning, generate action policy with code, verify the task progress, and provide feedback for replanning. Such design enables COME-robot to (i) actively perceive the environments, (ii) perform situated reasoning, and (iii) recover from failures. Through comprehensive experiments involving 8 challenging real-world tabletop and manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~25%) compared to state-of-the-art baseline methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
LLM3:Large Language Model-based Task and Motion Planning with Motion Failure Reasoning
Mar 20, 2024



Conventional Task and Motion Planning (TAMP) approaches rely on manually crafted interfaces connecting symbolic task planning with continuous motion generation. These domain-specific and labor-intensive modules are limited in addressing emerging tasks in real-world settings. Here, we present LLM^3, a novel Large Language Model (LLM)-based TAMP framework featuring a domain-independent interface. Specifically, we leverage the powerful reasoning and planning capabilities of pre-trained LLMs to propose symbolic action sequences and select continuous action parameters for motion planning. Crucially, LLM^3 incorporates motion planning feedback through prompting, allowing the LLM to iteratively refine its proposals by reasoning about motion failure. Consequently, LLM^3 interfaces between task planning and motion planning, alleviating the intricate design process of handling domain-specific messages between them. Through a series of simulations in a box-packing domain, we quantitatively demonstrate the effectiveness of LLM^3 in solving TAMP problems and the efficiency in selecting action parameters. Ablation studies underscore the significant contribution of motion failure reasoning to the success of LLM^3. Furthermore, we conduct qualitative experiments on a physical manipulator, demonstrating the practical applicability of our approach in real-world settings.
Part-level Scene Reconstruction Affords Robot Interaction
Aug 01, 2023
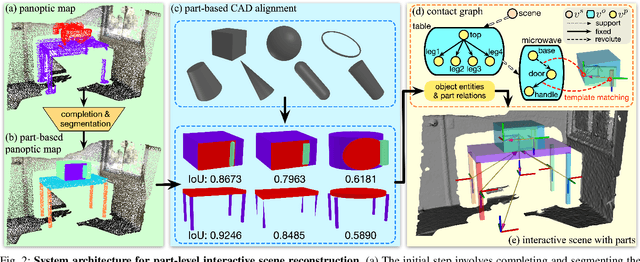
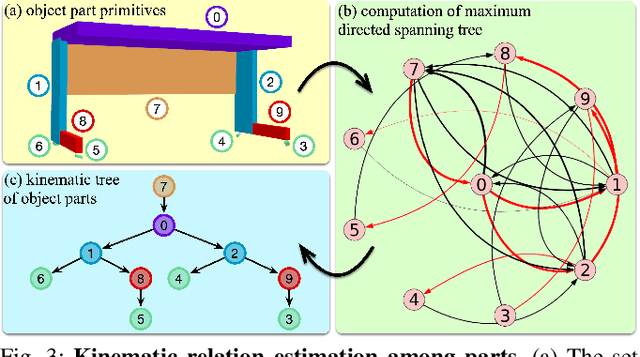
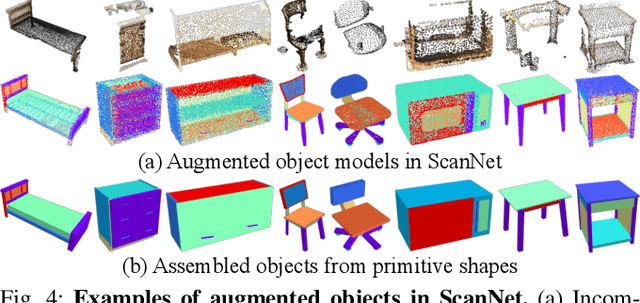
Existing methods for reconstructing interactive scenes primarily focus on replacing reconstructed objects with CAD models retrieved from a limited database, resulting in significant discrepancies between the reconstructed and observed scenes. To address this issue, our work introduces a part-level reconstruction approach that reassembles objects using primitive shapes. This enables us to precisely replicate the observed physical scenes and simulate robot interactions with both rigid and articulated objects. By segmenting reconstructed objects into semantic parts and aligning primitive shapes to these parts, we assemble them as CAD models while estimating kinematic relations, including parent-child contact relations, joint types, and parameters. Specifically, we derive the optimal primitive alignment by solving a series of optimization problems, and estimate kinematic relations based on part semantics and geometry. Our experiments demonstrate that part-level scene reconstruction outperforms object-level reconstruction by accurately capturing finer details and improving precision. These reconstructed part-level interactive scenes provide valuable kinematic information for various robotic applications; we showcase the feasibility of certifying mobile manipulation planning in these interactive scenes before executing tasks in the physical world.
Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments
Mar 30, 2021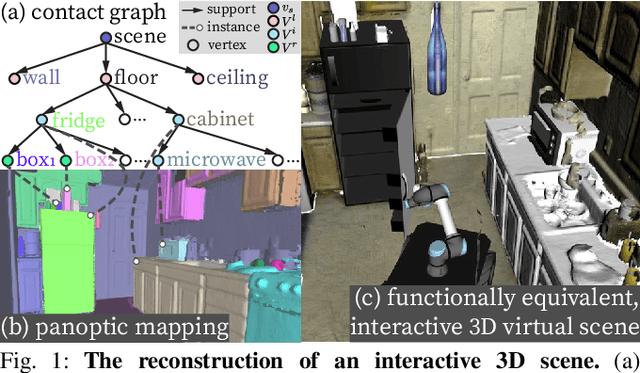
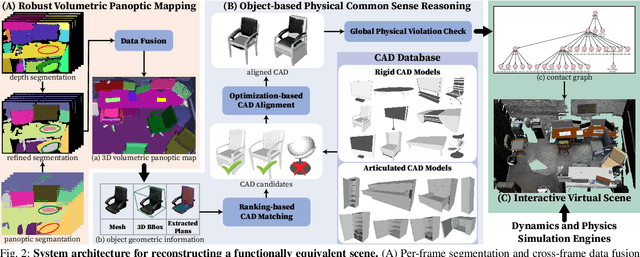
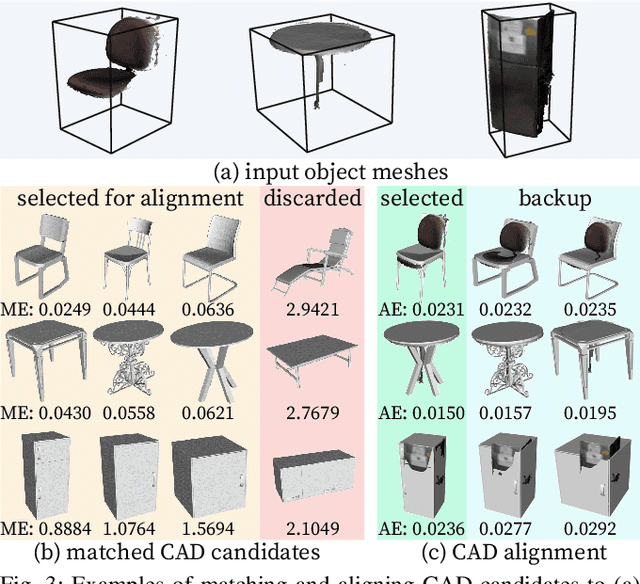
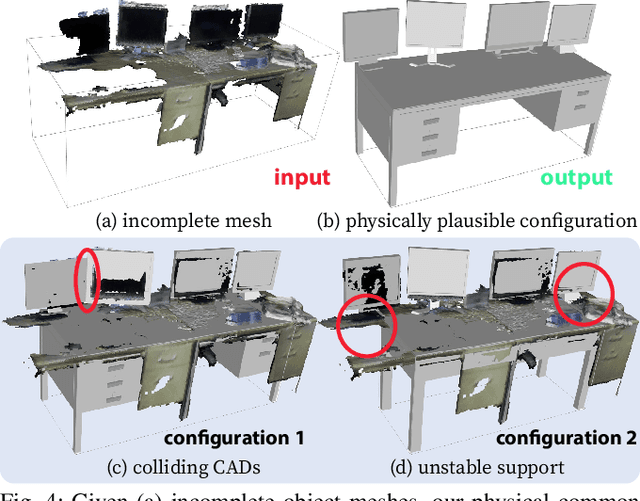
In this paper, we rethink the problem of scene reconstruction from an embodied agent's perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints such that the reconstructed scenes provide \em{actionable} information for simulating \em{interactions} with agents. Here, we address this challenging problem by reconstructing an interactive scene using RGB-D data stream, which captures (i) the semantics and geometry of objects and layouts by a 3D volumetric panoptic mapping module, and (ii) object affordance and contextual relations by reasoning over physical common sense among objects, organized by a graph-based scene representation. Crucially, this reconstructed scene replaces the object meshes in the dense panoptic map with part-based articulated CAD models for finer-grained robot interactions. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods, (ii) a high-performant physical reasoning procedure that matches, aligns, and replaces objects' meshes with best-fitted CAD models, and (iii) reconstructed scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based simulators and virtual environments for complex robot task executions.