 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTrack: General Motion Tracking via Physics-Consistent Reference
Feb 27, 2026Learning motion tracking from rich human motion data is a foundational task for achieving general control in humanoid robots, enabling them to perform diverse behaviors. However, discrepancies in morphology and dynamics between humans and robots, combined with data noise, introduce physically infeasible artifacts in reference motions, such as floating and penetration. During both training and execution, these artifacts create a conflict between following inaccurate reference motions and maintaining the robot's stability, hindering the development of a generalizable motion tracking policy. To address these challenges, we introduce OmniTrack, a general tracking framework that explicitly decouples physical feasibility from general motion tracking. In the first stage, a privileged generalist policy generates physically plausible motions that strictly adhere to the robot's dynamics via trajectory rollout in simulation. In the second stage, the general control policy is trained to track these physically feasible motions, ensuring stable and coherent control transfer to the real robot. Experiments show that OmniTrack improves tracking accuracy and demonstrates strong generalization to unseen motions. In real-world tests, OmniTrack achieves hour-long, consistent, and stable tracking, including complex acrobatic motions such as flips and cartwheels. Additionally, we show that OmniTrack supports human-style stable and dynamic online teleoperation, highlighting its robustness and adaptability to varying user inputs.
OmniXtreme: Breaking the Generality Barrier in High-Dynamic Humanoid Control
Feb 27, 2026High-fidelity motion tracking serves as the ultimate litmus test for generalizable, human-level motor skills. However, current policies often hit a "generality barrier": as motion libraries scale in diversity, tracking fidelity inevitably collapses - especially for real-world deployment of high-dynamic motions. We identify this failure as the result of two compounding factors: the learning bottleneck in scaling multi-motion optimization and the physical executability constraints that arise in real-world actuation. To overcome these challenges, we introduce OmniXtreme, a scalable framework that decouples general motor skill learning from sim-to-real physical skill refinement. Our approach uses a flow-matching policy with high-capacity architectures to scale representation capacity without interference-intensive multi-motion RL optimization, followed by an actuation-aware refinement phase that ensures robust performance on physical hardware. Extensive experiments demonstrate that OmniXtreme maintains high-fidelity tracking across diverse, high-difficulty datasets. On real robots, the unified policy successfully executes multiple extreme motions, effectively breaking the long-standing fidelity-scalability trade-off in high-dynamic humanoid control.
Learning Unified Force and Position Control for Legged Loco-Manipulation
May 27, 2025Robotic loco-manipulation tasks often involve contact-rich interactions with the environment, requiring the joint modeling of contact force and robot position. However, recent visuomotor policies often focus solely on learning position or force control, overlooking their co-learning. In this work, we propose the first unified policy for legged robots that jointly models force and position control learned without reliance on force sensors. By simulating diverse combinations of position and force commands alongside external disturbance forces, we use reinforcement learning to learn a policy that estimates forces from historical robot states and compensates for them through position and velocity adjustments. This policy enables a wide range of manipulation behaviors under varying force and position inputs, including position tracking, force application, force tracking, and compliant interactions. Furthermore, we demonstrate that the learned policy enhances trajectory-based imitation learning pipelines by incorporating essential contact information through its force estimation module, achieving approximately 39.5% higher success rates across four challenging contact-rich manipulation tasks compared to position-control policies. Extensive experiments on both a quadrupedal manipulator and a humanoid robot validate the versatility and robustness of the proposed policy across diverse scenarios.
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Apr 16, 2024



Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. We present COME-robot, the first closed-loop framework utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. We meticulously construct a library of action primitives for robot exploration, navigation, and manipulation, serving as callable execution modules for GPT-4V in task planning. On top of these modules, GPT-4V serves as the brain that can accomplish multimodal reasoning, generate action policy with code, verify the task progress, and provide feedback for replanning. Such design enables COME-robot to (i) actively perceive the environments, (ii) perform situated reasoning, and (iii) recover from failures. Through comprehensive experiments involving 8 challenging real-world tabletop and manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~25%) compared to state-of-the-art baseline methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
PhyScene: Physically Interactable 3D Scene Synthesis for Embodied AI
Apr 15, 2024With recent developments in Embodied Artificial Intelligence (EAI) research, there has been a growing demand for high-quality, large-scale interactive scene generation. While prior methods in scene synthesis have prioritized the naturalness and realism of the generated scenes, the physical plausibility and interactivity of scenes have been largely left unexplored. To address this disparity, we introduce PhyScene, a novel method dedicated to generating interactive 3D scenes characterized by realistic layouts, articulated objects, and rich physical interactivity tailored for embodied agents. Based on a conditional diffusion model for capturing scene layouts, we devise novel physics- and interactivity-based guidance mechanisms that integrate constraints from object collision, room layout, and object reachability. Through extensive experiments, we demonstrate that PhyScene effectively leverages these guidance functions for physically interactable scene synthesis, outperforming existing state-of-the-art scene synthesis methods by a large margin. Our findings suggest that the scenes generated by PhyScene hold considerable potential for facilitating diverse skill acquisition among agents within interactive environments, thereby catalyzing further advancements in embodied AI research. Project website: http://physcene.github.io.
Joint Learning for Scattered Point Cloud Understanding with Hierarchical Self-Distillation
Dec 28, 2023Numerous point-cloud understanding techniques focus on whole entities and have succeeded in obtaining satisfactory results and limited sparsity tolerance. However, these methods are generally sensitive to incomplete point clouds that are scanned with flaws or large gaps. To address this issue, in this paper, we propose an end-to-end architecture that compensates for and identifies partial point clouds on the fly. First, we propose a cascaded solution that integrates both the upstream and downstream networks simultaneously, allowing the task-oriented downstream to identify the points generated by the completion-oriented upstream. These two streams complement each other, resulting in improved performance for both completion and downstream-dependent tasks. Second, to explicitly understand the predicted points' pattern, we introduce hierarchical self-distillation (HSD), which can be applied to arbitrary hierarchy-based point cloud methods. HSD ensures that the deepest classifier with a larger perceptual field and longer code length provides additional regularization to intermediate ones rather than simply aggregating the multi-scale features, and therefore maximizing the mutual information between a teacher and students. We show the advantage of the self-distillation process in the hyperspaces based on the information bottleneck principle. On the classification task, our proposed method performs competitively on the synthetic dataset and achieves superior results on the challenging real-world benchmark when compared to the state-of-the-art models. Additional experiments also demonstrate the superior performance and generality of our framework on the part segmentation task.
Hybrid Physical Metric For 6-DoF Grasp Pose Detection
Jun 22, 2022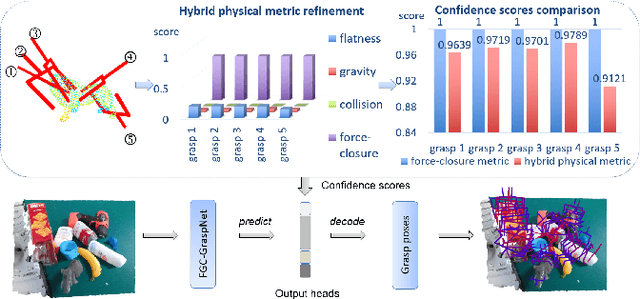
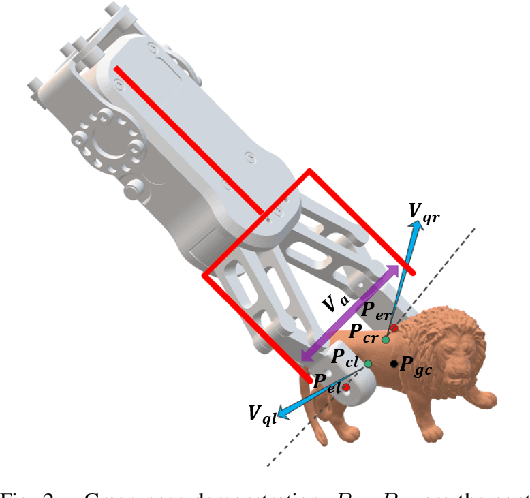
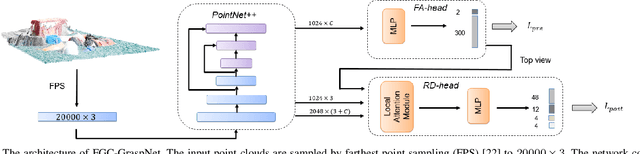
6-DoF grasp pose detection of multi-grasp and multi-object is a challenge task in the field of intelligent robot. To imitate human reasoning ability for grasping objects, data driven methods are widely studied. With the introduction of large-scale datasets, we discover that a single physical metric usually generates several discrete levels of grasp confidence scores, which cannot finely distinguish millions of grasp poses and leads to inaccurate prediction results. In this paper, we propose a hybrid physical metric to solve this evaluation insufficiency. First, we define a novel metric is based on the force-closure metric, supplemented by the measurement of the object flatness, gravity and collision. Second, we leverage this hybrid physical metric to generate elaborate confidence scores. Third, to learn the new confidence scores effectively, we design a multi-resolution network called Flatness Gravity Collision GraspNet (FGC-GraspNet). FGC-GraspNet proposes a multi-resolution features learning architecture for multiple tasks and introduces a new joint loss function that enhances the average precision of the grasp detection. The network evaluation and adequate real robot experiments demonstrate the effectiveness of our hybrid physical metric and FGC-GraspNet. Our method achieves 90.5\% success rate in real-world cluttered scenes. Our code is available at https://github.com/luyh20/FGC-GraspNet.