 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Knowledge Editing for Detoxification
Feb 11, 2026Knowledge-Editing-based (KE-based) detoxification has emerged as a promising approach for mitigating harmful behaviours in Large Language Models. Existing evaluations, however, largely rely on automatic toxicity classifiers, implicitly assuming that reduced toxicity scores reflect genuine behavioural suppression. In this work, we propose a robustness-oriented evaluation framework for KE-based detoxification that examines its reliability beyond standard classifier-based metrics along three dimensions: optimisation robustness, compositional robustness, and cross-lingual robustness. We identify pseudo-detoxification as a common failure mode, where apparent toxicity reductions arise from degenerate generation behaviours rather than meaningful suppression of unsafe content. We further show that detoxification effectiveness degrades when multiple unsafe behaviours are edited jointly, and that both monolingual and cross-lingual detoxification remain effective only under specific model-method combinations. Overall, our results indicate that KE-based detoxification is robust only for certain models, limited numbers of detoxification objectives, and a subset of languages.
From Horizontal Layering to Vertical Integration: A Comparative Study of the AI-Driven Software Development Paradigm
Jan 30, 2026This paper examines the organizational implications of Generative AI adoption in software engineering through a multiple-case comparative study. We contrast two development environments: a traditional enterprise (brownfield) and an AI-native startup (greenfield). Our analysis reveals that transitioning from Horizontal Layering (functional specialization) to Vertical Integration (end-to-end ownership) yields 8-fold to 33-fold reductions in resource consumption. We attribute these gains to the emergence of Super Employees, AI-augmented engineers who span traditional role boundaries, and the elimination of inter-functional coordination overhead. Theoretically, we propose Human-AI Collaboration Efficacy as the primary optimization target for engineering organizations, supplanting individual productivity metrics. Our Total Factor Productivity analysis identifies an AI Distortion Effect that diminishes returns to labor scale while amplifying technological leverage. We conclude with managerial strategies for organizational redesign, including the reactivation of idle cognitive bandwidth in senior engineers and the suppression of blind scale expansion.
Deterministic Image-to-Image Translation via Denoising Brownian Bridge Models with Dual Approximators
Dec 29, 2025Image-to-Image (I2I) translation involves converting an image from one domain to another. Deterministic I2I translation, such as in image super-resolution, extends this concept by guaranteeing that each input generates a consistent and predictable output, closely matching the ground truth (GT) with high fidelity. In this paper, we propose a denoising Brownian bridge model with dual approximators (Dual-approx Bridge), a novel generative model that exploits the Brownian bridge dynamics and two neural network-based approximators (one for forward and one for reverse process) to produce faithful output with negligible variance and high image quality in I2I translations. Our extensive experiments on benchmark datasets including image generation and super-resolution demonstrate the consistent and superior performance of Dual-approx Bridge in terms of image quality and faithfulness to GT when compared to both stochastic and deterministic baselines. Project page and code: https://github.com/bohan95/dual-app-bridge
Regularized Schrödinger Bridge: Alleviating Distortion and Exposure Bias in Solving Inverse Problems
Nov 19, 2025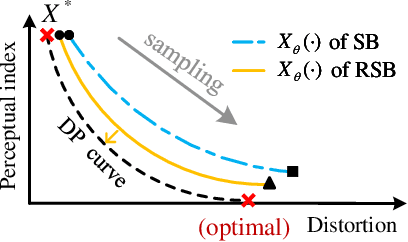
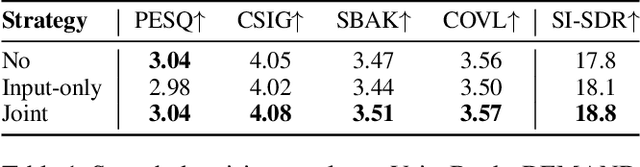
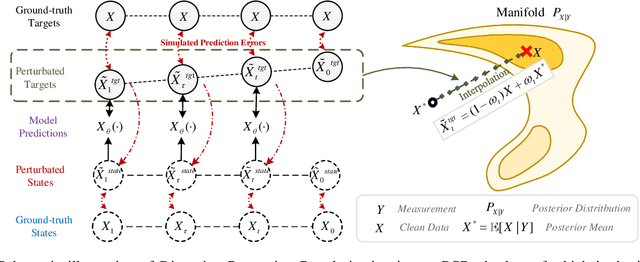

Diffusion models serve as a powerful generative framework for solving inverse problems. However, they still face two key challenges: 1) the distortion-perception tradeoff, where improving perceptual quality often degrades reconstruction fidelity, and 2) the exposure bias problem, where the training-inference input mismatch leads to prediction error accumulation and reduced reconstruction quality. In this work, we propose the Regularized Schrödinger Bridge (RSB), an adaptation of Schrödinger Bridge tailored for inverse problems that addresses the above limitations. RSB employs a novel regularized training strategy that perturbs both the input states and targets, effectively mitigating exposure bias by exposing the model to simulated prediction errors and also alleviating distortion by well-designed interpolation via the posterior mean. Extensive experiments on two typical inverse problems for speech enhancement demonstrate that RSB outperforms state-of-the-art methods, significantly improving distortion metrics and effectively reducing exposure bias.
Modality-AGnostic Image Cascade (MAGIC) for Multi-Modality Cardiac Substructure Segmentation
Jun 12, 2025Cardiac substructures are essential in thoracic radiation therapy planning to minimize risk of radiation-induced heart disease. Deep learning (DL) offers efficient methods to reduce contouring burden but lacks generalizability across different modalities and overlapping structures. This work introduces and validates a Modality-AGnostic Image Cascade (MAGIC) for comprehensive and multi-modal cardiac substructure segmentation. MAGIC is implemented through replicated encoding and decoding branches of an nnU-Net-based, U-shaped backbone conserving the function of a single model. Twenty cardiac substructures (heart, chambers, great vessels (GVs), valves, coronary arteries (CAs), and conduction nodes) from simulation CT (Sim-CT), low-field MR-Linac, and cardiac CT angiography (CCTA) modalities were manually delineated and used to train (n=76), validate (n=15), and test (n=30) MAGIC. Twelve comparison models (four segmentation subgroups across three modalities) were equivalently trained. All methods were compared for training efficiency and against reference contours using the Dice Similarity Coefficient (DSC) and two-tailed Wilcoxon Signed-Rank test (threshold, p<0.05). Average DSC scores were 0.75(0.16) for Sim-CT, 0.68(0.21) for MR-Linac, and 0.80(0.16) for CCTA. MAGIC outperforms the comparison in 57% of cases, with limited statistical differences. MAGIC offers an effective and accurate segmentation solution that is lightweight and capable of segmenting multiple modalities and overlapping structures in a single model. MAGIC further enables clinical implementation by simplifying the computational requirements and offering unparalleled flexibility for clinical settings.
FISH-Tuning: Enhancing PEFT Methods with Fisher Information
Apr 05, 2025The rapid growth in the parameter size of Large Language Models (LLMs) has led to the development of Parameter-Efficient Fine-Tuning (PEFT) methods to alleviate the computational costs of fine-tuning. Among these, Fisher Induced Sparse uncHanging (FISH) Mask is a selection-based PEFT technique that identifies a subset of pre-trained parameters for fine-tuning based on approximate Fisher information. However, the integration of FISH Mask with other PEFT methods, such as LoRA and Adapters, remains underexplored. In this paper, we propose FISH-Tuning, a novel approach that incorporates FISH Mask into addition-based and reparameterization-based PEFT methods, including LoRA, Adapters, and their variants. By leveraging Fisher information to select critical parameters within these methods, FISH-Tuning achieves superior performance without additional memory overhead or inference latency. Experimental results across various datasets and pre-trained models demonstrate that FISH-Tuning consistently outperforms the vanilla PEFT methods with the same proportion of trainable parameters.
Deterministic Medical Image Translation via High-fidelity Brownian Bridges
Mar 28, 2025Recent studies have shown that diffusion models produce superior synthetic images when compared to Generative Adversarial Networks (GANs). However, their outputs are often non-deterministic and lack high fidelity to the ground truth due to the inherent randomness. In this paper, we propose a novel High-fidelity Brownian bridge model (HiFi-BBrg) for deterministic medical image translations. Our model comprises two distinct yet mutually beneficial mappings: a generation mapping and a reconstruction mapping. The Brownian bridge training process is guided by the fidelity loss and adversarial training in the reconstruction mapping. This ensures that translated images can be accurately reversed to their original forms, thereby achieving consistent translations with high fidelity to the ground truth. Our extensive experiments on multiple datasets show HiFi-BBrg outperforms state-of-the-art methods in multi-modal image translation and multi-image super-resolution.
Conditional diffusion model with spatial attention and latent embedding for medical image segmentation
Feb 10, 2025Diffusion models have been used extensively for high quality image and video generation tasks. In this paper, we propose a novel conditional diffusion model with spatial attention and latent embedding (cDAL) for medical image segmentation. In cDAL, a convolutional neural network (CNN) based discriminator is used at every time-step of the diffusion process to distinguish between the generated labels and the real ones. A spatial attention map is computed based on the features learned by the discriminator to help cDAL generate more accurate segmentation of discriminative regions in an input image. Additionally, we incorporated a random latent embedding into each layer of our model to significantly reduce the number of training and sampling time-steps, thereby making it much faster than other diffusion models for image segmentation. We applied cDAL on 3 publicly available medical image segmentation datasets (MoNuSeg, Chest X-ray and Hippocampus) and observed significant qualitative and quantitative improvements with higher Dice scores and mIoU over the state-of-the-art algorithms. The source code is publicly available at https://github.com/Hejrati/cDAL/.
Data-oriented Dynamic Fine-tuning Parameter Selection Strategy for FISH Mask based Efficient Fine-tuning
Mar 13, 2024



In view of the huge number of parameters of Large language models (LLMs) , tuning all parameters is very costly, and accordingly fine-tuning specific parameters is more sensible. Most of parameter efficient fine-tuning (PEFT) concentrate on parameter selection strategies, such as additive method, selective method and reparametrization-based method. However, there are few methods that consider the impact of data samples on parameter selecting, such as Fish Mask based method. Fish Mask randomly choose a part of data samples and treat them equally during parameter selection, which is unable to dynamically select optimal parameters for inconstant data distributions. In this work, we adopt a data-oriented perspective, then proposing an IRD ($\mathrm{\underline I}$terative sample-parameter $\mathrm{\underline R}$ange $\mathrm{\underline D}$ecreasing) algorithm to search the best setting of sample-parameter pair for FISH Mask. In each iteration, by searching the set of samples and parameters with larger Fish information, IRD can find better sample-parameter pair in most scale. We demonstrate the effectiveness and rationality of proposed strategy by conducting experiments on GLUE benchmark. Experimental results show our strategy optimizes the parameter selection and achieves preferable performance.
Rich Semantic Knowledge Enhanced Large Language Models for Few-shot Chinese Spell Checking
Mar 13, 2024



Chinese Spell Checking (CSC) is a widely used technology, which plays a vital role in speech to text (STT) and optical character recognition (OCR). Most of the existing CSC approaches relying on BERT architecture achieve excellent performance. However, limited by the scale of the foundation model, BERT-based method does not work well in few-shot scenarios, showing certain limitations in practical applications. In this paper, we explore using an in-context learning method named RS-LLM (Rich Semantic based LLMs) to introduce large language models (LLMs) as the foundation model. Besides, we study the impact of introducing various Chinese rich semantic information in our framework. We found that by introducing a small number of specific Chinese rich semantic structures, LLMs achieve better performance than the BERT-based model on few-shot CSC task. Furthermore, we conduct experiments on multiple datasets, and the experimental results verified the superiority of our proposed framework.