 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich Semantic Knowledge Enhanced Large Language Models for Few-shot Chinese Spell Checking
Mar 13, 2024



Chinese Spell Checking (CSC) is a widely used technology, which plays a vital role in speech to text (STT) and optical character recognition (OCR). Most of the existing CSC approaches relying on BERT architecture achieve excellent performance. However, limited by the scale of the foundation model, BERT-based method does not work well in few-shot scenarios, showing certain limitations in practical applications. In this paper, we explore using an in-context learning method named RS-LLM (Rich Semantic based LLMs) to introduce large language models (LLMs) as the foundation model. Besides, we study the impact of introducing various Chinese rich semantic information in our framework. We found that by introducing a small number of specific Chinese rich semantic structures, LLMs achieve better performance than the BERT-based model on few-shot CSC task. Furthermore, we conduct experiments on multiple datasets, and the experimental results verified the superiority of our proposed framework.
Asynchronous Federated Learning for Sensor Data with Concept Drift
Sep 01, 2021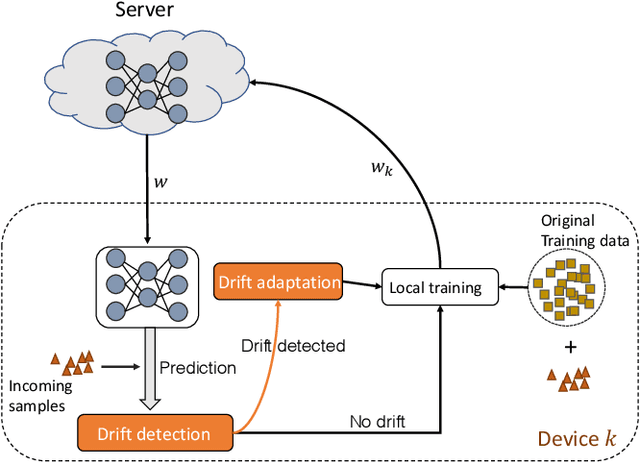
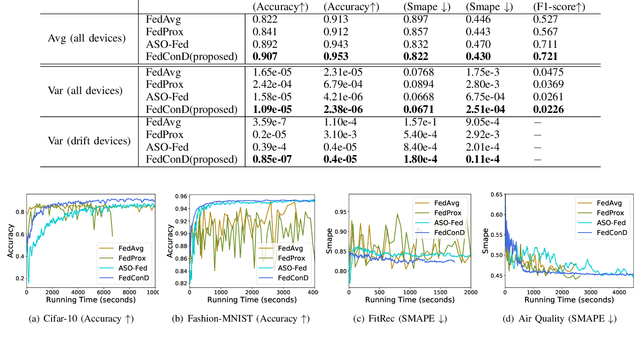
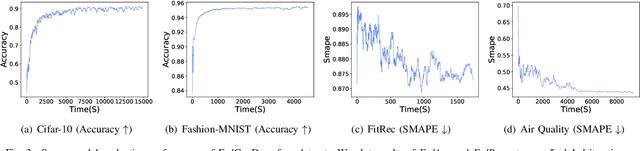
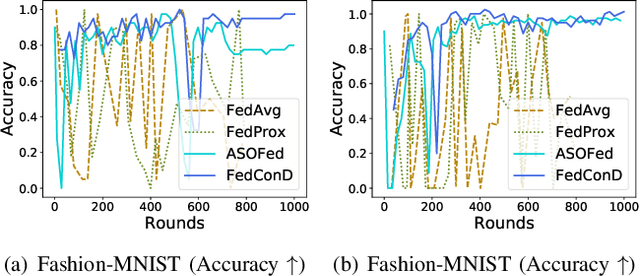
Federated learning (FL) involves multiple distributed devices jointly training a shared model without any of the participants having to reveal their local data to a centralized server. Most of previous FL approaches assume that data on devices are fixed and stationary during the training process. However, this assumption is unrealistic because these devices usually have varying sampling rates and different system configurations. In addition, the underlying distribution of the device data can change dynamically over time, which is known as concept drift. Concept drift makes the learning process complicated because of the inconsistency between existing and upcoming data. Traditional concept drift handling techniques such as chunk based and ensemble learning-based methods are not suitable in the federated learning frameworks due to the heterogeneity of local devices. We propose a novel approach, FedConD, to detect and deal with the concept drift on local devices and minimize the effect on the performance of models in asynchronous FL. The drift detection strategy is based on an adaptive mechanism which uses the historical performance of the local models. The drift adaptation is realized by adjusting the regularization parameter of objective function on each local device. Additionally, we design a communication strategy on the server side to select local updates in a prudent fashion and speed up model convergence. Experimental evaluations on three evolving data streams and two image datasets show that \model~detects and handles concept drift, and also reduces the overall communication cost compared to other baseline methods.
PointCutMix: Regularization Strategy for Point Cloud Classification
Feb 05, 2021
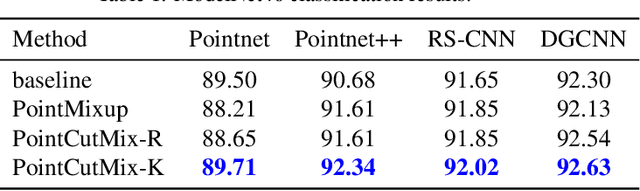

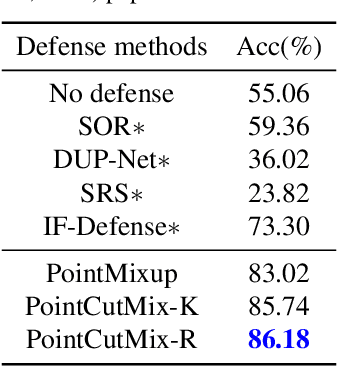
As 3D point cloud analysis has received increasing attention, the insufficient scale of point cloud datasets and the weak generalization ability of networks become prominent. In this paper, we propose a simple and effective augmentation method for the point cloud data, named PointCutMix, to alleviate those problems. It finds the optimal assignment between two point clouds and generates new training data by replacing the points in one sample with their optimal assigned pairs. Two replacement strategies are proposed to adapt to the accuracy or robustness requirement for different tasks, one of which is to randomly select all replacing points while the other one is to select k nearest neighbors of a single random point. Both strategies consistently and significantly improve the performance of various models on point cloud classification problems. By introducing the saliency maps to guide the selection of replacing points, the performance further improves. Moreover, PointCutMix is validated to enhance the model robustness against the point attack. It is worth noting that when using as a defense method, our method outperforms the state-of-the-art defense algorithms. The code is available at:https://github.com/cuge1995/PointCutMix
FedAT: A Communication-Efficient Federated Learning Method with Asynchronous Tiers under Non-IID Data
Oct 12, 2020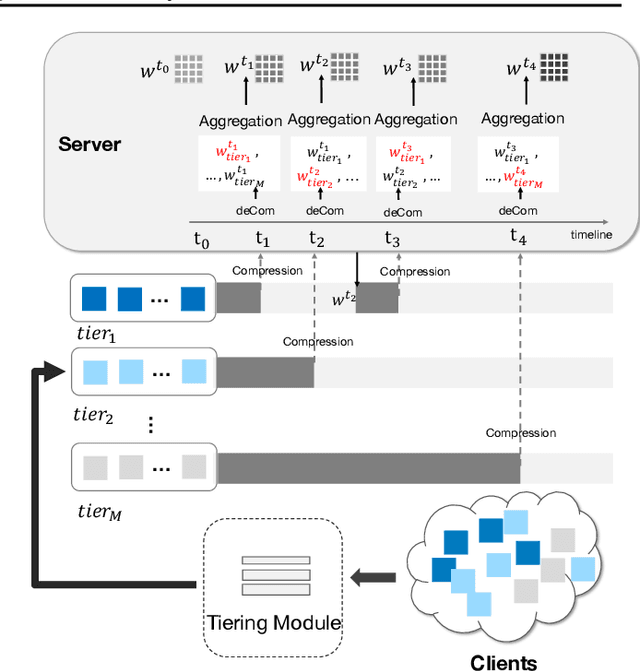
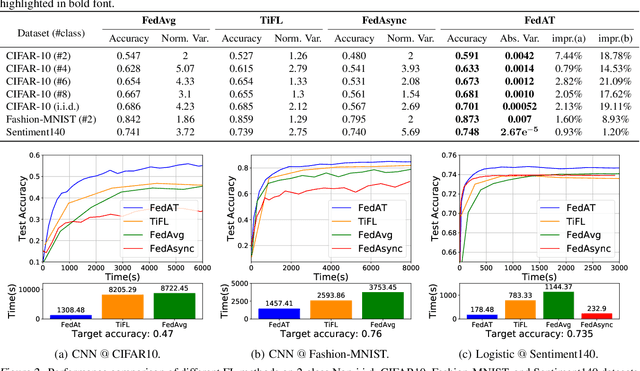
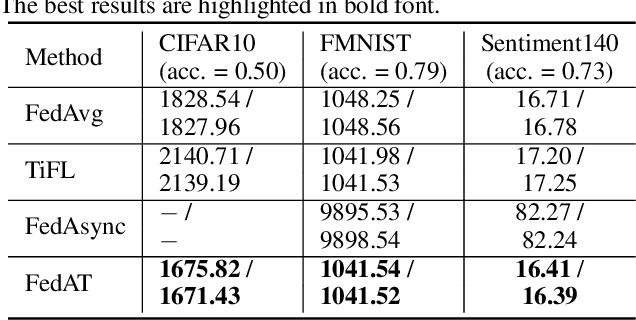
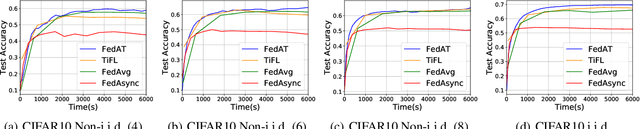
Federated learning (FL) involves training a model over massive distributed devices, while keeping the training data localized. This form of collaborative learning exposes new tradeoffs among model convergence speed, model accuracy, balance across clients, and communication cost, with new challenges including: (1) straggler problem, where the clients lag due to data or (computing and network) resource heterogeneity, and (2) communication bottleneck, where a large number of clients communicate their local updates to a central server and bottleneck the server. Many existing FL methods focus on optimizing along only one dimension of the tradeoff space. Existing solutions use asynchronous model updating or tiering-based synchronous mechanisms to tackle the straggler problem. However, the asynchronous methods can easily create a network communication bottleneck, while tiering may introduce biases as tiering favors faster tiers with shorter response latencies. To address these issues, we present FedAT, a novel Federated learning method with Asynchronous Tiers under Non-i.i.d. data. FedAT synergistically combines synchronous intra-tier training and asynchronous cross-tier training. By bridging the synchronous and asynchronous training through tiering, FedAT minimizes the straggler effect with improved convergence speed and test accuracy. FedAT uses a straggler-aware, weighted aggregation heuristic to steer and balance the training for further accuracy improvement. FedAT compresses the uplink and downlink communications using an efficient, polyline-encoding-based compression algorithm, therefore minimizing the communication cost. Results show that FedAT improves the prediction performance by up to 21.09%, and reduces the communication cost by up to 8.5x, compared to state-of-the-art FL methods.
Asynchronous Online Federated Learning for Edge Devices
Nov 05, 2019
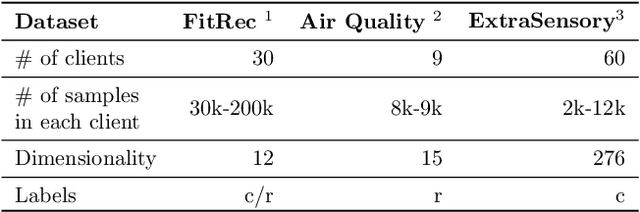
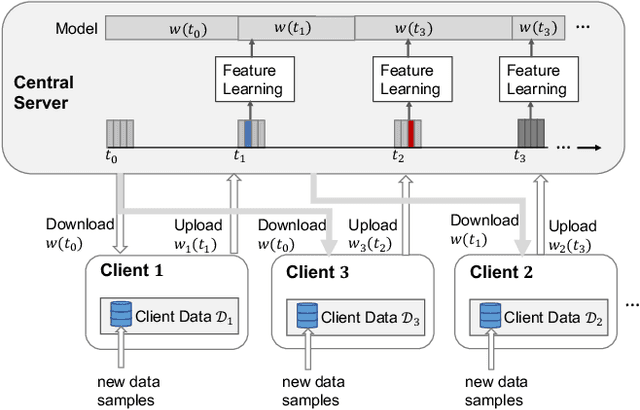
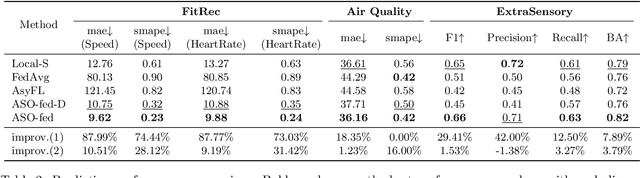
Federated learning (FL) is a machine learning paradigm where a shared central model is learned across multiple distributed client devices while the training data remains on edge devices or local clients. Most prior work on federated learning uses Federated Averaging (FedAvg) as an optimization method for training in a synchronized fashion. This involves independent training at multiple edge devices with synchronous aggregation steps. However, the assumptions made by FedAvg are not realistic given the heterogeneity of devices. In particular, the volume and distribution of collected data vary in the training process due to different sampling rates of edge devices. The edge devices themselves also vary in their available communication bandwidth and system configurations, such as memory, processor speed, and power requirements. This leads to vastly different training times as well as model/data transfer times. Furthermore, availability issues at edge devices can lead to a lack of contribution from specific edge devices to the federated model. In this paper, we present an Asynchronous Online Federated Learning (ASO- fed) framework, where the edge devices perform online learning with continuous streaming local data and a central server aggregates model parameters from local clients. Our framework updates the central model in an asynchronous manner to tackle the challenges associated with both varying computational loads at heterogeneous edge devices and edge devices that lag behind or dropout. Experiments on three real-world datasets show the effectiveness of ASO-fed on lowering the overall training cost and maintaining good prediction performance.
Federated Multi-task Hierarchical Attention Model for Sensor Analytics
May 13, 2019
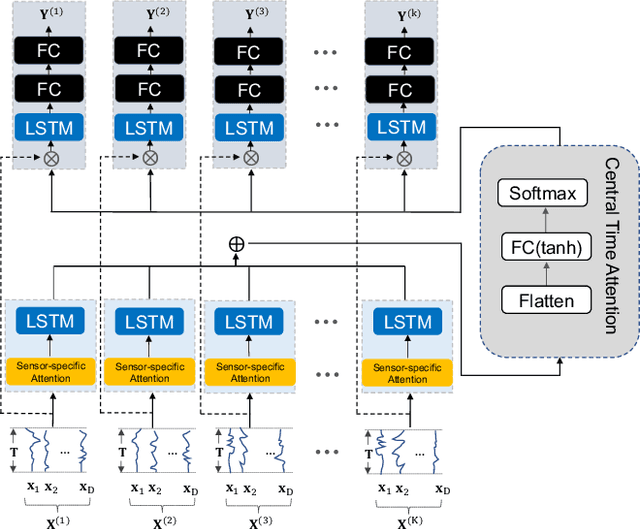
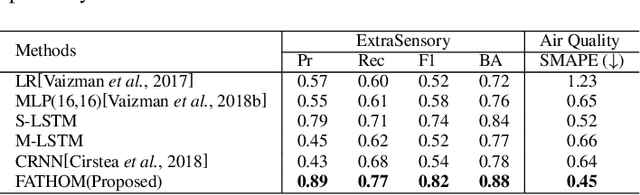
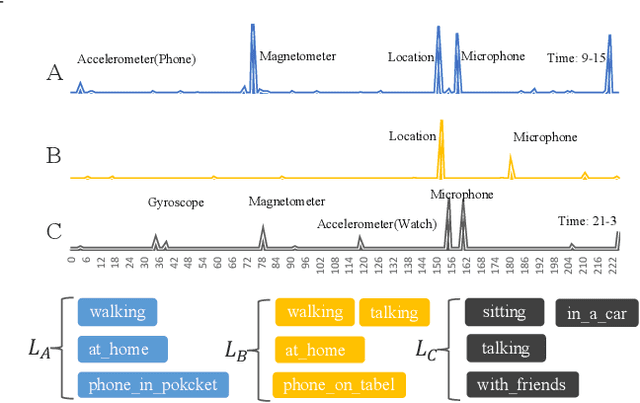
Sensors are an integral part of modern Internet of Things (IoT) applications. There is a critical need for the analysis of heterogeneous multivariate temporal data obtained from the individual sensors of these systems. In this paper we particularly focus on the problem of the scarce amount of training data available per sensor. We propose a novel federated multi-task hierarchical attention model (FATHOM) that jointly trains classification/regression models from multiple sensors. The attention mechanism of the proposed model seeks to extract feature representations from the input and learn a shared representation focused on time dimensions across multiple sensors. The underlying temporal and non-linear relationships are modeled using a combination of attention mechanism and long-short term memory (LSTM) networks. We find that our proposed method outperforms a wide range of competitive baselines in both classification and regression settings on activity recognition and environment monitoring datasets. We further provide visualization of feature representations learned by our model at the input sensor level and central time level.