 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders
Feb 15, 2026As industrial recommender systems enter a scaling-driven regime, Transformer architectures have become increasingly attractive for scaling models towards larger capacity and longer sequence. However, existing Transformer-based recommendation models remain structurally fragmented, where sequence modeling and feature interaction are implemented as separate modules with independent parameterization. Such designs introduce a fundamental co-scaling challenge, as model capacity must be suboptimally allocated between dense feature interaction and sequence modeling under a limited computational budget. In this work, we propose MixFormer, a unified Transformer-style architecture tailored for recommender systems, which jointly models sequential behaviors and feature interactions within a single backbone. Through a unified parameterization, MixFormer enables effective co-scaling across both dense capacity and sequence length, mitigating the trade-off observed in decoupled designs. Moreover, the integrated architecture facilitates deep interaction between sequential and non-sequential representations, allowing high-order feature semantics to directly inform sequence aggregation and enhancing overall expressiveness. To ensure industrial practicality, we further introduce a user-item decoupling strategy for efficiency optimizations that significantly reduce redundant computation and inference latency. Extensive experiments on large-scale industrial datasets demonstrate that MixFormer consistently exhibits superior accuracy and efficiency. Furthermore, large-scale online A/B tests on two production recommender systems, Douyin and Douyin Lite, show consistent improvements in user engagement metrics, including active days and in-app usage duration.
Compute Only Once: UG-Separation for Efficient Large Recommendation Models
Feb 11, 2026Driven by scaling laws, recommender systems increasingly rely on large-scale models to capture complex feature interactions and user behaviors, but this trend also leads to prohibitive training and inference costs. While long-sequence models(e.g., LONGER) can reuse user-side computation through KV caching, such reuse is difficult in dense feature interaction architectures(e.g., RankMixer), where user and group (candidate item) features are deeply entangled across layers. In this work, we propose User-Group Separation (UG-Sep), a novel framework that enables reusable user-side computation in dense interaction models for the first time. UG-Sep introduces a masking mechanism that explicitly disentangles user-side and item-side information flows within token-mixing layers, ensuring that a subset of tokens to preserve purely user-side representations across layers. This design enables corresponding token computations to be reused across multiple samples, significantly reducing redundant inference cost. To compensate for potential expressiveness loss induced by masking, we further propose an Information Compensation strategy that adaptively reconstructs suppressed user-item interactions. Moreover, as UG-Sep substantially reduces user-side FLOPs and exposes memory-bound components, we incorporate W8A16 (8-bit weight, 16-bit activation) weight-only quantization to alleviate memory bandwidth bottlenecks and achieve additional acceleration. We conduct extensive offline evaluations and large-scale online A/B experiments at ByteDance, demonstrating that UG-Sep reduces inference latency by up to 20 percent without degrading online user experience or commercial metrics across multiple business scenarios, including feed recommendation and advertising systems.
MSN: A Memory-based Sparse Activation Scaling Framework for Large-scale Industrial Recommendation
Feb 07, 2026Scaling deep learning recommendation models is an effective way to improve model expressiveness. Existing approaches often incur substantial computational overhead, making them difficult to deploy in large-scale industrial systems under strict latency constraints. Recent sparse activation scaling methods, such as Sparse Mixture-of-Experts, reduce computation by activating only a subset of parameters, but still suffer from high memory access costs and limited personalization capacity due to the large size and small number of experts. To address these challenges, we propose MSN, a memory-based sparse activation scaling framework for recommendation models. MSN dynamically retrieves personalized representations from a large parameterized memory and integrates them into downstream feature interaction modules via a memory gating mechanism, enabling fine-grained personalization with low computational overhead. To enable further expansion of the memory capacity while keeping both computational and memory access costs under control, MSN adopts a Product-Key Memory (PKM) mechanism, which factorizes the memory retrieval complexity from linear time to sub-linear complexity. In addition, normalization and over-parameterization techniques are introduced to maintain balanced memory utilization and prevent memory retrieval collapse. We further design customized Sparse-Gather operator and adopt the AirTopK operator to improve training and inference efficiency in industrial settings. Extensive experiments demonstrate that MSN consistently improves recommendation performance while maintaining high efficiency. Moreover, MSN has been successfully deployed in the Douyin Search Ranking System, achieving significant gains over deployed state-of-the-art models in both offline evaluation metrics and large-scale online A/B test.
TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders
Feb 06, 2026In recent years, the study of scaling laws for large recommendation models has gradually gained attention. Works such as Wukong, HiFormer, and DHEN have attempted to increase the complexity of interaction structures in ranking models and validate scaling laws between performance and parameters/FLOPs by stacking multiple layers. However, their experimental scale remains relatively limited. Our previous work introduced the TokenMixer architecture, an efficient variant of the standard Transformer where the self-attention mechanism is replaced by a simple reshape operation, and the feed-forward network is adapted to a pertoken FFN. The effectiveness of this architecture was demonstrated in the ranking stage by the model presented in the RankMixer paper. However, this foundational TokenMixer architecture itself has several design limitations. In this paper, we propose TokenMixer-Large, which systematically addresses these core issues: sub-optimal residual design, insufficient gradient updates in deep models, incomplete MoE sparsification, and limited exploration of scalability. By leveraging a mixing-and-reverting operation, inter-layer residuals, the auxiliary loss and a novel Sparse-Pertoken MoE architecture, TokenMixer-Large successfully scales its parameters to 7-billion and 15-billion on online traffic and offline experiments, respectively. Currently deployed in multiple scenarios at ByteDance, TokenMixer -Large has achieved significant offline and online performance gains.
HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction
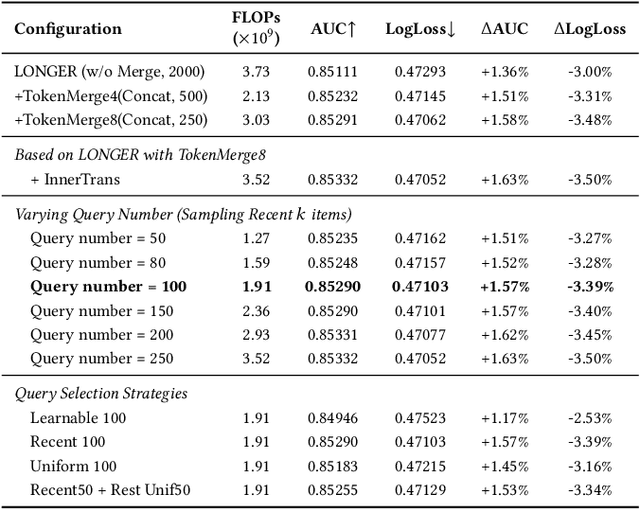
Jan 19, 2026Industrial large-scale recommendation models (LRMs) face the challenge of jointly modeling long-range user behavior sequences and heterogeneous non-sequential features under strict efficiency constraints. However, most existing architectures employ a decoupled pipeline: long sequences are first compressed with a query-token based sequence compressor like LONGER, followed by fusion with dense features through token-mixing modules like RankMixer, which thereby limits both the representation capacity and the interaction flexibility. This paper presents HyFormer, a unified hybrid transformer architecture that tightly integrates long-sequence modeling and feature interaction into a single backbone. From the perspective of sequence modeling, we revisit and redesign query tokens in LRMs, and frame the LRM modeling task as an alternating optimization process that integrates two core components: Query Decoding which expands non-sequential features into Global Tokens and performs long sequence decoding over layer-wise key-value representations of long behavioral sequences; and Query Boosting which enhances cross-query and cross-sequence heterogeneous interactions via efficient token mixing. The two complementary mechanisms are performed iteratively to refine semantic representations across layers. Extensive experiments on billion-scale industrial datasets demonstrate that HyFormer consistently outperforms strong LONGER and RankMixer baselines under comparable parameter and FLOPs budgets, while exhibiting superior scaling behavior with increasing parameters and FLOPs. Large-scale online A/B tests in high-traffic production systems further validate its effectiveness, showing significant gains over deployed state-of-the-art models. These results highlight the practicality and scalability of HyFormer as a unified modeling framework for industrial LRMs.
LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders
May 07, 2025

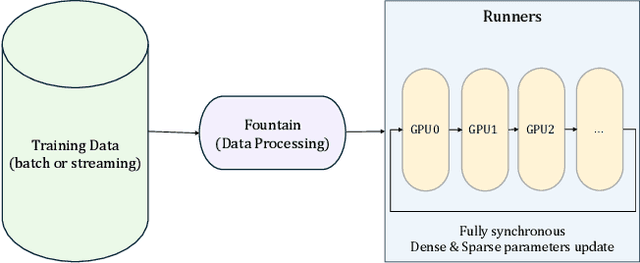
Modeling ultra-long user behavior sequences is critical for capturing both long- and short-term preferences in industrial recommender systems. Existing solutions typically rely on two-stage retrieval or indirect modeling paradigms, incuring upstream-downstream inconsistency and computational inefficiency. In this paper, we present LONGER, a Long-sequence Optimized traNsformer for GPU-Efficient Recommenders. LONGER incorporates (i) a global token mechanism for stabilizing attention over long contexts, (ii) a token merge module with lightweight InnerTransformers and hybrid attention strategy to reduce quadratic complexity, and (iii) a series of engineering optimizations, including training with mixed-precision and activation recomputation, KV cache serving, and the fully synchronous model training and serving framework for unified GPU-based dense and sparse parameter updates. LONGER consistently outperforms strong baselines in both offline metrics and online A/B testing in both advertising and e-commerce services at ByteDance, validating its consistent effectiveness and industrial-level scaling laws. Currently, LONGER has been fully deployed at more than 10 influential scenarios at ByteDance, serving billion users.
Large Memory Network for Recommendation
Feb 08, 2025



Modeling user behavior sequences in recommender systems is essential for understanding user preferences over time, enabling personalized and accurate recommendations for improving user retention and enhancing business values. Despite its significance, there are two challenges for current sequential modeling approaches. From the spatial dimension, it is difficult to mutually perceive similar users' interests for a generalized intention understanding; from the temporal dimension, current methods are generally prone to forgetting long-term interests due to the fixed-length input sequence. In this paper, we present Large Memory Network (LMN), providing a novel idea by compressing and storing user history behavior information in a large-scale memory block. With the elaborated online deployment strategy, the memory block can be easily scaled up to million-scale in the industry. Extensive offline comparison experiments, memory scaling up experiments, and online A/B test on Douyin E-Commerce Search (ECS) are performed, validating the superior performance of LMN. Currently, LMN has been fully deployed in Douyin ECS, serving millions of users each day.
Adaptive Domain Scaling for Personalized Sequential Modeling in Recommenders
Feb 08, 2025



Users generally exhibit complex behavioral patterns and diverse intentions in multiple business scenarios of super applications like Douyin, presenting great challenges to current industrial multi-domain recommenders. To mitigate the discrepancies across diverse domains, researches and industrial practices generally emphasize sophisticated network structures to accomodate diverse data distributions, while neglecting the inherent understanding of user behavioral sequence from the multi-domain perspective. In this paper, we present Adaptive Domain Scaling (ADS) model, which comprehensively enhances the personalization capability in target-aware sequence modeling across multiple domains. Specifically, ADS comprises of two major modules, including personalized sequence representation generation (PSRG) and personalized candidate representation generation (PCRG). The modules contribute to the tailored multi-domain learning by dynamically learning both the user behavioral sequence item representation and the candidate target item representation under different domains, facilitating adaptive user intention understanding. Experiments are performed on both a public dataset and two billion-scaled industrial datasets, and the extensive results verify the high effectiveness and compatibility of ADS. Besides, we conduct online experiments on two influential business scenarios including Douyin Advertisement Platform and Douyin E-commerce Service Platform, both of which show substantial business improvements. Currently, ADS has been fully deployed in many recommendation services at ByteDance, serving billions of users.
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models
Jan 04, 2024The burgeoning field of Large Language Models (LLMs), exemplified by sophisticated models like OpenAI's ChatGPT, represents a significant advancement in artificial intelligence. These models, however, bring forth substantial challenges in the high consumption of computational, memory, energy, and financial resources, especially in environments with limited resource capabilities. This survey aims to systematically address these challenges by reviewing a broad spectrum of techniques designed to enhance the resource efficiency of LLMs. We categorize methods based on their optimization focus: computational, memory, energy, financial, and network resources and their applicability across various stages of an LLM's lifecycle, including architecture design, pretraining, finetuning, and system design. Additionally, the survey introduces a nuanced categorization of resource efficiency techniques by their specific resource types, which uncovers the intricate relationships and mappings between various resources and corresponding optimization techniques. A standardized set of evaluation metrics and datasets is also presented to facilitate consistent and fair comparisons across different models and techniques. By offering a comprehensive overview of the current sota and identifying open research avenues, this survey serves as a foundational reference for researchers and practitioners, aiding them in developing more sustainable and efficient LLMs in a rapidly evolving landscape.
Staleness-Alleviated Distributed GNN Training via Online Dynamic-Embedding Prediction
Aug 25, 2023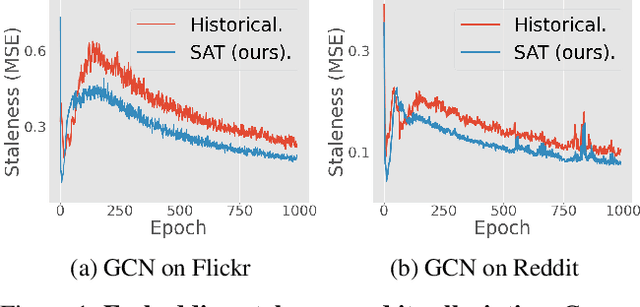
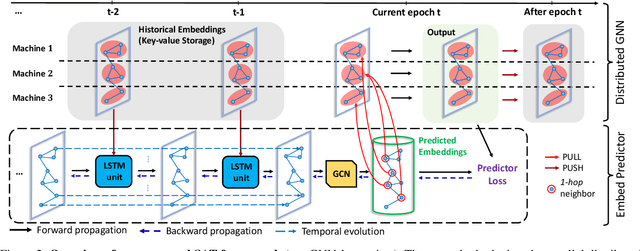
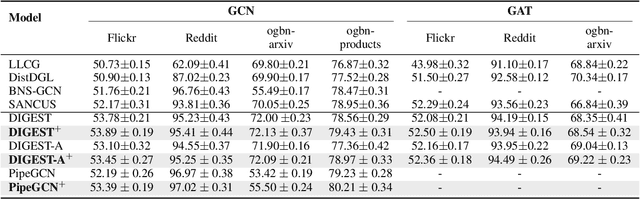
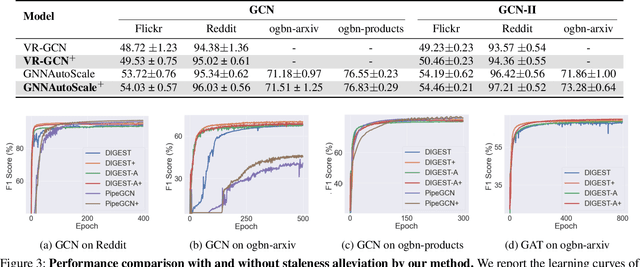
Despite the recent success of Graph Neural Networks (GNNs), it remains challenging to train GNNs on large-scale graphs due to neighbor explosions. As a remedy, distributed computing becomes a promising solution by leveraging abundant computing resources (e.g., GPU). However, the node dependency of graph data increases the difficulty of achieving high concurrency in distributed GNN training, which suffers from the massive communication overhead. To address it, Historical value approximation is deemed a promising class of distributed training techniques. It utilizes an offline memory to cache historical information (e.g., node embedding) as an affordable approximation of the exact value and achieves high concurrency. However, such benefits come at the cost of involving dated training information, leading to staleness, imprecision, and convergence issues. To overcome these challenges, this paper proposes SAT (Staleness-Alleviated Training), a novel and scalable distributed GNN training framework that reduces the embedding staleness adaptively. The key idea of SAT is to model the GNN's embedding evolution as a temporal graph and build a model upon it to predict future embedding, which effectively alleviates the staleness of the cached historical embedding. We propose an online algorithm to train the embedding predictor and the distributed GNN alternatively and further provide a convergence analysis. Empirically, we demonstrate that SAT can effectively reduce embedding staleness and thus achieve better performance and convergence speed on multiple large-scale graph datasets.