 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Graph Neural Network Training with Periodic Historical Embedding Synchronization
Paper and Code
May 31, 2022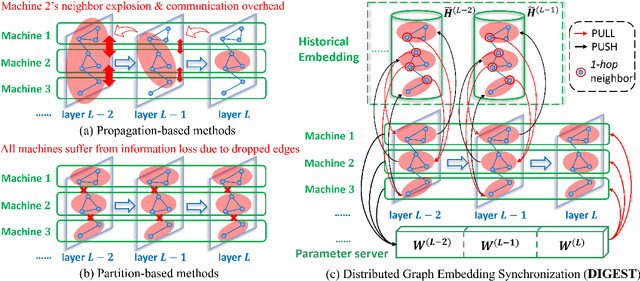

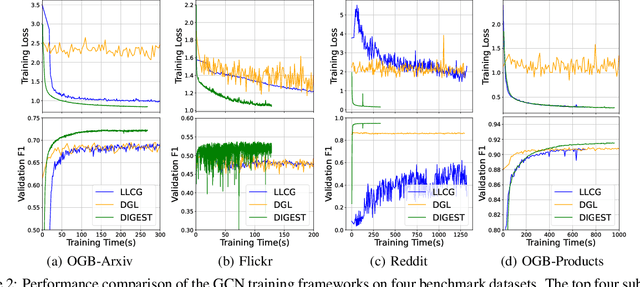

Despite the recent success of Graph Neural Networks (GNNs), it remains challenging to train a GNN on large graphs, which are prevalent in various applications such as social network, recommender systems, and knowledge graphs. Traditional sampling-based methods accelerate GNN by dropping edges and nodes, which impairs the graph integrity and model performance. Differently, distributed GNN algorithms, which accelerate GNN training by utilizing multiple computing devices, can be classified into two types: "partition-based" methods enjoy low communication costs but suffer from information loss due to dropped edges, while "propagation-based" methods avoid information loss but suffer prohibitive communication overhead. To jointly address these problems, this paper proposes DIstributed Graph Embedding SynchronizaTion (DIGEST), a novel distributed GNN training framework that synergizes the complementary strength of both categories of existing methods. During subgraph parallel training, we propose to let each device store the historical embedding of its neighbors in other subgraphs. Therefore, our method does not discard any neighbors in other subgraphs, nor does it updates them intensively. This effectively avoids (1) the intensive computation on explosively-increasing neighbors and (2) excessive communications across different devices. We proved that the approximation error induced by the staleness of historical embedding can be upper bounded and it does NOT affect the GNN model's expressiveness. More importantly, our convergence analysis demonstrates that DIGEST enjoys a state-of-the-art convergence rate. Extensive experimental evaluation on large, real-world graph datasets shows that DIGEST achieves up to $21.82\times$ speedup without compromising the performance compared to state-of-the-art distributed GNN training frameworks.