 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Biomolecular Trajectory Generation via Pretrained Variational Bridge
Feb 07, 2026Molecular Dynamics (MD) simulations provide a fundamental tool for characterizing molecular behavior at full atomic resolution, but their applicability is severely constrained by the computational cost. To address this, a surge of deep generative models has recently emerged to learn dynamics at coarsened timesteps for efficient trajectory generation, yet they either generalize poorly across systems or, due to limited molecular diversity of trajectory data, fail to fully exploit structural information to improve generative fidelity. Here, we present the Pretrained Variational Bridge (PVB) in an encoder-decoder fashion, which maps the initial structure into a noised latent space and transports it toward stage-specific targets through augmented bridge matching. This unifies training on both single-structure and paired trajectory data, enabling consistent use of cross-domain structural knowledge across training stages. Moreover, for protein-ligand complexes, we further introduce a reinforcement learning-based optimization via adjoint matching that speeds progression toward the holo state, which supports efficient post-optimization of docking poses. Experiments on proteins and protein-ligand complexes demonstrate that PVB faithfully reproduces thermodynamic and kinetic observables from MD while delivering stable and efficient generative dynamics.
Distilling LLM Reasoning into Graph of Concept Predictors
Feb 03, 2026Deploying Large Language Models (LLMs) for discriminative workloads is often limited by inference latency, compute, and API costs at scale. Active distillation reduces these costs by querying an LLM oracle to train compact discriminative students, but most pipelines distill only final labels, discarding intermediate reasoning signals and offering limited diagnostics of what reasoning is missing and where errors arise. We propose Graph of Concept Predictors (GCP), a reasoning-aware active distillation framework that externalizes the teacher's decision process as a directed acyclic graph and mirrors it with modular concept predictors in the student. GCP enhances sample efficiency through a graph-aware acquisition strategy that targets uncertainty and disagreement at critical reasoning nodes. Additionally, it improves training stability and efficiency by performing targeted sub-module retraining, which attributes downstream loss to specific concept predictors and updates only the most influential modules. Experiments on eight NLP classification benchmarks demonstrate that GCP enhances performance under limited annotation budgets while yielding more interpretable and controllable training dynamics. Code is available at: https://github.com/Ziyang-Yu/GCP.
Efficient Imputation for Patch-based Missing Single-cell Data via Cluster-regularized Optimal Transport
Jan 21, 2026Missing data in single-cell sequencing datasets poses significant challenges for extracting meaningful biological insights. However, existing imputation approaches, which often assume uniformity and data completeness, struggle to address cases with large patches of missing data. In this paper, we present CROT, an optimal transport-based imputation algorithm designed to handle patch-based missing data in tabular formats. Our approach effectively captures the underlying data structure in the presence of significant missingness. Notably, it achieves superior imputation accuracy while significantly reducing runtime, demonstrating its scalability and efficiency for large-scale datasets. This work introduces a robust solution for imputation in heterogeneous, high-dimensional datasets with structured data absence, addressing critical challenges in both biological and clinical data analysis. Our code is available at Anomalous Github.
ICPC: In-context Prompt Compression with Faster Inference
Jan 03, 2025



Despite the recent success of Large Language Models (LLMs), it remains challenging to feed LLMs with long prompts due to the fixed size of LLM inputs. As a remedy, prompt compression becomes a promising solution by removing redundant tokens in the prompt. However, using LLM in the existing works requires additional computation resources and leads to memory overheads. To address it, we propose ICPC (In-context Prompt Compression), a novel and scalable prompt compression method that adaptively reduces the prompt length. The key idea of ICPC is to calculate the probability of each word appearing in the prompt using encoders and calculate information carried by each word through the information function, which effectively reduces the information loss during prompt compression and increases the speed of compression. Empirically, we demonstrate that ICPC can effectively compress long texts of different categories and thus achieve better performance and speed on different types of NLP tasks.
Domain Adaptation-based Edge Computing for Cross-Conditions Fault Diagnosis
Nov 15, 2024



Fault diagnosis technology supports the healthy operation of mechanical equipment. However, the variations conditions during the operation of mechanical equipment lead to significant disparities in data distribution, posing challenges to fault diagnosis. Furthermore, when deploying applications, traditional methods often encounter issues such as latency and data security. Therefore, conducting fault diagnosis and deploying application methods under cross-operating conditions holds significant value. This paper proposes a domain adaptation-based lightweight fault diagnosis framework for edge computing scenarios. Incorporating the local maximum mean discrepancy into knowledge transfer aligns the feature distributions of different domains in a high-dimensional feature space, to discover a common feature space across domains. The acquired fault diagnosis expertise from the cloud-model is transferred to the lightweight edge-model using adaptation knowledge transfer methods. While ensuring real-time diagnostic capabilities, accurate fault diagnosis is achieved across working conditions. We conducted validation experiments on the NVIDIA Jetson Xavier NX kit. In terms of diagnostic performance, the proposed method significantly improved diagnostic accuracy, with average increases of 34.44% and 17.33% compared to the comparison method, respectively. Regarding lightweight effectiveness, proposed method achieved an average inference speed increase of 80.47%. Additionally, compared to the cloud-model, the parameter count of the edge-model decreased by 96.37%, while the Flops decreased by 83.08%.
Force-Guided Bridge Matching for Full-Atom Time-Coarsened Dynamics of Peptides
Aug 27, 2024
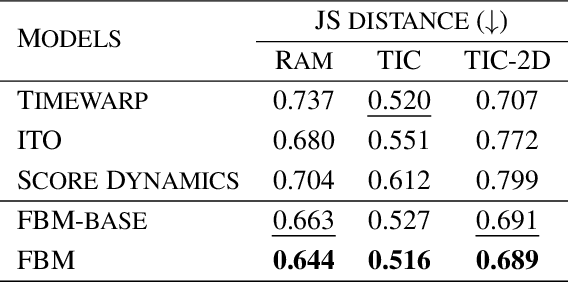


Molecular Dynamics (MD) simulations are irreplaceable and ubiquitous in fields of materials science, chemistry, pharmacology just to name a few. Conventional MD simulations are plagued by numerical stability as well as long equilibration time issues, which limits broader applications of MD simulations. Recently, a surge of deep learning approaches have been devised for time-coarsened dynamics, which learns the state transition mechanism over much larger time scales to overcome these limitations. However, only a few methods target the underlying Boltzmann distribution by resampling techniques, where proposals are rarely accepted as new states with low efficiency. In this work, we propose a force-guided bridge matching model, FBM, a novel framework that first incorporates physical priors into bridge matching for full-atom time-coarsened dynamics. With the guidance of our well-designed intermediate force field, FBM is feasible to target the Boltzmann-like distribution by direct inference without extra steps. Experiments on small peptides verify our superiority in terms of comprehensive metrics and demonstrate transferability to unseen peptide systems.
A Survey of Geometric Graph Neural Networks: Data Structures, Models and Applications
Mar 01, 2024Geometric graph is a special kind of graph with geometric features, which is vital to model many scientific problems. Unlike generic graphs, geometric graphs often exhibit physical symmetries of translations, rotations, and reflections, making them ineffectively processed by current Graph Neural Networks (GNNs). To tackle this issue, researchers proposed a variety of Geometric Graph Neural Networks equipped with invariant/equivariant properties to better characterize the geometry and topology of geometric graphs. Given the current progress in this field, it is imperative to conduct a comprehensive survey of data structures, models, and applications related to geometric GNNs. In this paper, based on the necessary but concise mathematical preliminaries, we provide a unified view of existing models from the geometric message passing perspective. Additionally, we summarize the applications as well as the related datasets to facilitate later research for methodology development and experimental evaluation. We also discuss the challenges and future potential directions of Geometric GNNs at the end of this survey.
Equivariant Pretrained Transformer for Unified Geometric Learning on Multi-Domain 3D Molecules
Feb 20, 2024Pretraining on a large number of unlabeled 3D molecules has showcased superiority in various scientific applications. However, prior efforts typically focus on pretraining models on a specific domain, either proteins or small molecules, missing the opportunity to leverage the cross-domain knowledge. To mitigate this gap, we introduce Equivariant Pretrained Transformer (EPT), a novel pretraining framework designed to harmonize the geometric learning of small molecules and proteins. To be specific, EPT unifies the geometric modeling of multi-domain molecules via the block-enhanced representation that can attend a broader context of each atom. Upon transformer framework, EPT is further enhanced with E(3) equivariance to facilitate the accurate representation of 3D structures. Another key innovation of EPT is its block-level pretraining task, which allows for joint pretraining on datasets comprising both small molecules and proteins. Experimental evaluations on a diverse group of benchmarks, including ligand binding affinity prediction, molecular property prediction, and protein property prediction, show that EPT significantly outperforms previous SOTA methods for affinity prediction, and achieves the best or comparable performance with existing domain-specific pretraining models for other tasks.
Rigid Protein-Protein Docking via Equivariant Elliptic-Paraboloid Interface Prediction
Jan 17, 2024



The study of rigid protein-protein docking plays an essential role in a variety of tasks such as drug design and protein engineering. Recently, several learning-based methods have been proposed for the task, exhibiting much faster docking speed than those computational methods. In this paper, we propose a novel learning-based method called ElliDock, which predicts an elliptic paraboloid to represent the protein-protein docking interface. To be specific, our model estimates elliptic paraboloid interfaces for the two input proteins respectively, and obtains the roto-translation transformation for docking by making two interfaces coincide. By its design, ElliDock is independently equivariant with respect to arbitrary rotations/translations of the proteins, which is an indispensable property to ensure the generalization of the docking process. Experimental evaluations show that ElliDock achieves the fastest inference time among all compared methods and is strongly competitive with current state-of-the-art learning-based models such as DiffDock-PP and Multimer particularly for antibody-antigen docking.
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models
Jan 04, 2024The burgeoning field of Large Language Models (LLMs), exemplified by sophisticated models like OpenAI's ChatGPT, represents a significant advancement in artificial intelligence. These models, however, bring forth substantial challenges in the high consumption of computational, memory, energy, and financial resources, especially in environments with limited resource capabilities. This survey aims to systematically address these challenges by reviewing a broad spectrum of techniques designed to enhance the resource efficiency of LLMs. We categorize methods based on their optimization focus: computational, memory, energy, financial, and network resources and their applicability across various stages of an LLM's lifecycle, including architecture design, pretraining, finetuning, and system design. Additionally, the survey introduces a nuanced categorization of resource efficiency techniques by their specific resource types, which uncovers the intricate relationships and mappings between various resources and corresponding optimization techniques. A standardized set of evaluation metrics and datasets is also presented to facilitate consistent and fair comparisons across different models and techniques. By offering a comprehensive overview of the current sota and identifying open research avenues, this survey serves as a foundational reference for researchers and practitioners, aiding them in developing more sustainable and efficient LLMs in a rapidly evolving landscape.