 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
DynaHOI: Benchmarking Hand-Object Interaction for Dynamic Target
Feb 12, 2026Most existing hand motion generation benchmarks for hand-object interaction (HOI) focus on static objects, leaving dynamic scenarios with moving targets and time-critical coordination largely untested. To address this gap, we introduce the DynaHOI-Gym, a unified online closed-loop platform with parameterized motion generators and rollout-based metrics for dynamic capture evaluation. Built on DynaHOI-Gym, we release DynaHOI-10M, a large-scale benchmark with 10M frames and 180K hand capture trajectories, whose target motions are organized into 8 major categories and 22 fine-grained subcategories. We also provide a simple observe-before-act baseline (ObAct) that integrates short-term observations with the current frame via spatiotemporal attention to predict actions, achieving an 8.1% improvement in location success rate.
Multimodal Multi-Agent Empowered Legal Judgment Prediction
Jan 21, 2026Legal Judgment Prediction (LJP) aims to predict the outcomes of legal cases based on factual descriptions, serving as a fundamental task to advance the development of legal systems. Traditional methods often rely on statistical analyses or role-based simulations but face challenges with multiple allegations, diverse evidence, and lack adaptability. In this paper, we introduce JurisMMA, a novel framework for LJP that effectively decomposes trial tasks, standardizes processes, and organizes them into distinct stages. Furthermore, we build JurisMM, a large dataset with over 100,000 recent Chinese judicial records, including both text and multimodal video-text data, enabling comprehensive evaluation. Experiments on JurisMM and the benchmark LawBench validate our framework's effectiveness. These results indicate that our framework is effective not only for LJP but also for a broader range of legal applications, offering new perspectives for the development of future legal methods and datasets.
Joint Learning for Scattered Point Cloud Understanding with Hierarchical Self-Distillation
Dec 28, 2023Numerous point-cloud understanding techniques focus on whole entities and have succeeded in obtaining satisfactory results and limited sparsity tolerance. However, these methods are generally sensitive to incomplete point clouds that are scanned with flaws or large gaps. To address this issue, in this paper, we propose an end-to-end architecture that compensates for and identifies partial point clouds on the fly. First, we propose a cascaded solution that integrates both the upstream and downstream networks simultaneously, allowing the task-oriented downstream to identify the points generated by the completion-oriented upstream. These two streams complement each other, resulting in improved performance for both completion and downstream-dependent tasks. Second, to explicitly understand the predicted points' pattern, we introduce hierarchical self-distillation (HSD), which can be applied to arbitrary hierarchy-based point cloud methods. HSD ensures that the deepest classifier with a larger perceptual field and longer code length provides additional regularization to intermediate ones rather than simply aggregating the multi-scale features, and therefore maximizing the mutual information between a teacher and students. We show the advantage of the self-distillation process in the hyperspaces based on the information bottleneck principle. On the classification task, our proposed method performs competitively on the synthetic dataset and achieves superior results on the challenging real-world benchmark when compared to the state-of-the-art models. Additional experiments also demonstrate the superior performance and generality of our framework on the part segmentation task.
"Zero Shot" Point Cloud Upsampling
Jun 25, 2021
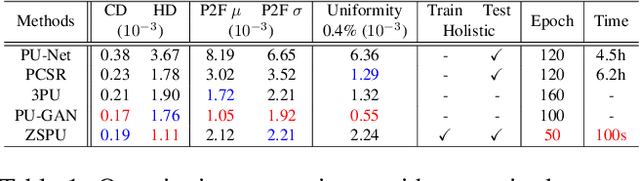
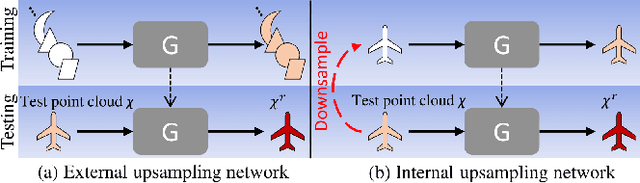
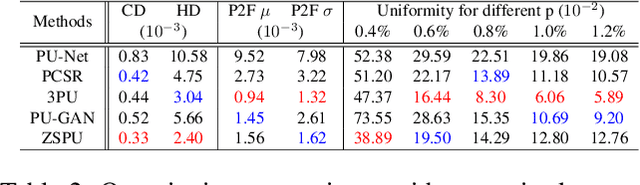
Point cloud upsampling using deep learning has been paid various efforts in the past few years. Recent supervised deep learning methods are restricted to the size of training data and is limited in terms of covering all shapes of point clouds. Besides, the acquisition of such amount of data is unrealistic, and the network generally performs less powerful than expected on unseen records. In this paper, we present an unsupervised approach to upsample point clouds internally referred as "Zero Shot" Point Cloud Upsampling (ZSPU) at holistic level. Our approach is solely based on the internal information provided by a particular point cloud without patching in both self-training and testing phases. This single-stream design significantly reduces the training time of the upsampling task, by learning the relation between low-resolution (LR) point clouds and their high (original) resolution (HR) counterparts. This association will provide super-resolution (SR) outputs when original point clouds are loaded as input. We demonstrate competitive performance on benchmark point cloud datasets when compared to other upsampling methods. Furthermore, ZSPU achieves superior qualitative results on shapes with complex local details or high curvatures.