 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-Grasp: a 6-Dof Interactive Grasp Policy for Language-Oriented Objects in Cluttered Indoor Scenes
Aug 01, 2023Robotic grasping faces new challenges in human-robot-interaction scenarios. We consider the task that the robot grasps a target object designated by human's language directives. The robot not only needs to locate a target based on vision-and-language information, but also needs to predict the reasonable grasp pose candidate at various views and postures. In this work, we propose a novel interactive grasp policy, named Visual-Lingual-Grasp (VL-Grasp), to grasp the target specified by human language. First, we build a new challenging visual grounding dataset to provide functional training data for robotic interactive perception in indoor environments. Second, we propose a 6-Dof interactive grasp policy combined with visual grounding and 6-Dof grasp pose detection to extend the universality of interactive grasping. Third, we design a grasp pose filter module to enhance the performance of the policy. Experiments demonstrate the effectiveness and extendibility of the VL-Grasp in real world. The VL-Grasp achieves a success rate of 72.5\% in different indoor scenes. The code and dataset is available at https://github.com/luyh20/VL-Grasp.
Hybrid Physical Metric For 6-DoF Grasp Pose Detection
Jun 22, 2022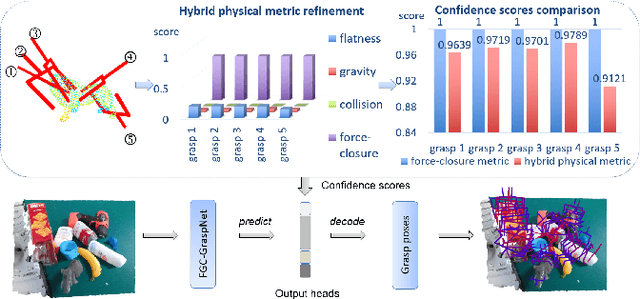
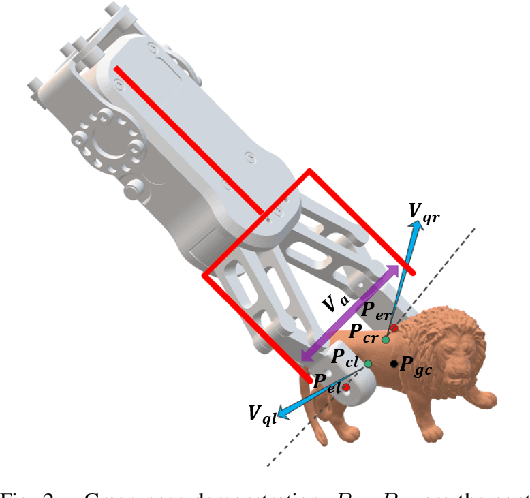
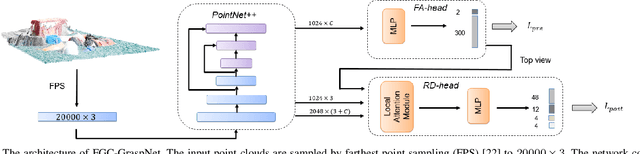
6-DoF grasp pose detection of multi-grasp and multi-object is a challenge task in the field of intelligent robot. To imitate human reasoning ability for grasping objects, data driven methods are widely studied. With the introduction of large-scale datasets, we discover that a single physical metric usually generates several discrete levels of grasp confidence scores, which cannot finely distinguish millions of grasp poses and leads to inaccurate prediction results. In this paper, we propose a hybrid physical metric to solve this evaluation insufficiency. First, we define a novel metric is based on the force-closure metric, supplemented by the measurement of the object flatness, gravity and collision. Second, we leverage this hybrid physical metric to generate elaborate confidence scores. Third, to learn the new confidence scores effectively, we design a multi-resolution network called Flatness Gravity Collision GraspNet (FGC-GraspNet). FGC-GraspNet proposes a multi-resolution features learning architecture for multiple tasks and introduces a new joint loss function that enhances the average precision of the grasp detection. The network evaluation and adequate real robot experiments demonstrate the effectiveness of our hybrid physical metric and FGC-GraspNet. Our method achieves 90.5\% success rate in real-world cluttered scenes. Our code is available at https://github.com/luyh20/FGC-GraspNet.