 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2Diffuser: Diffusion-based Trajectory Optimization for Mobile Manipulation in 3D Scenes
Oct 15, 2024



Recent advances in diffusion models have opened new avenues for research into embodied AI agents and robotics. Despite significant achievements in complex robotic locomotion and skills, mobile manipulation-a capability that requires the coordination of navigation and manipulation-remains a challenge for generative AI techniques. This is primarily due to the high-dimensional action space, extended motion trajectories, and interactions with the surrounding environment. In this paper, we introduce M2Diffuser, a diffusion-based, scene-conditioned generative model that directly generates coordinated and efficient whole-body motion trajectories for mobile manipulation based on robot-centric 3D scans. M2Diffuser first learns trajectory-level distributions from mobile manipulation trajectories provided by an expert planner. Crucially, it incorporates an optimization module that can flexibly accommodate physical constraints and task objectives, modeled as cost and energy functions, during the inference process. This enables the reduction of physical violations and execution errors at each denoising step in a fully differentiable manner. Through benchmarking on three types of mobile manipulation tasks across over 20 scenes, we demonstrate that M2Diffuser outperforms state-of-the-art neural planners and successfully transfers the generated trajectories to a real-world robot. Our evaluations underscore the potential of generative AI to enhance the generalization of traditional planning and learning-based robotic methods, while also highlighting the critical role of enforcing physical constraints for safe and robust execution.
Dynamic Planning for Sequential Whole-body Mobile Manipulation
May 24, 2024
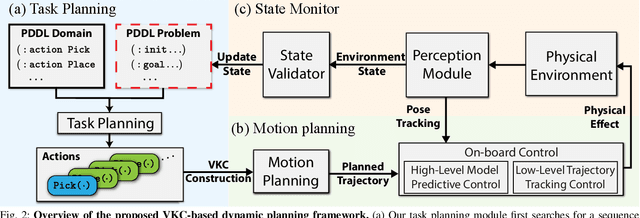
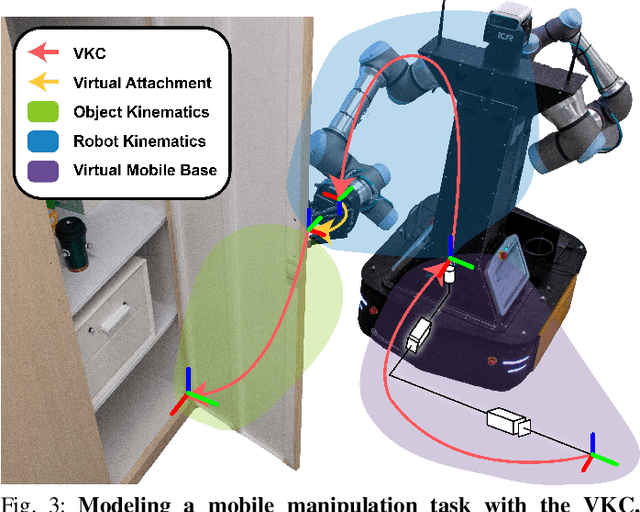
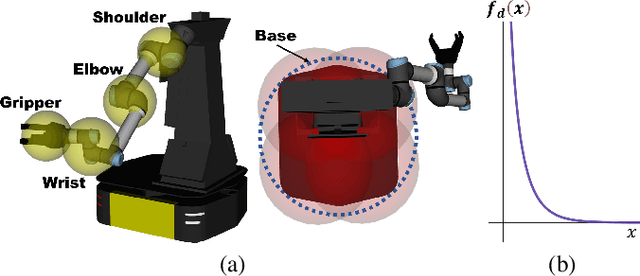
The dynamic Sequential Mobile Manipulation Planning (SMMP) framework is essential for the safe and robust operation of mobile manipulators in dynamic environments. Previous research has primarily focused on either motion-level or task-level dynamic planning, with limitations in handling state changes that have long-term effects or in generating responsive motions for diverse tasks, respectively. This paper presents a holistic dynamic planning framework that extends the Virtual Kinematic Chain (VKC)-based SMMP method, automating dynamic long-term task planning and reactive whole-body motion generation for SMMP problems. The framework consists of an online task planning module designed to respond to environment changes with long-term effects, a VKC-based whole-body motion planning module for manipulating both rigid and articulated objects, alongside a reactive Model Predictive Control (MPC) module for obstacle avoidance during execution. Simulations and real-world experiments validate the framework, demonstrating its efficacy and validity across sequential mobile manipulation tasks, even in scenarios involving human interference.
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Apr 16, 2024



Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. We present COME-robot, the first closed-loop framework utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. We meticulously construct a library of action primitives for robot exploration, navigation, and manipulation, serving as callable execution modules for GPT-4V in task planning. On top of these modules, GPT-4V serves as the brain that can accomplish multimodal reasoning, generate action policy with code, verify the task progress, and provide feedback for replanning. Such design enables COME-robot to (i) actively perceive the environments, (ii) perform situated reasoning, and (iii) recover from failures. Through comprehensive experiments involving 8 challenging real-world tabletop and manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~25%) compared to state-of-the-art baseline methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
Analysis on Multi-robot Relative 6-DOF Pose Estimation Error Based on UWB Range
Sep 27, 2023



Relative pose estimation is the foundational requirement for multi-robot system, while it is a challenging research topic in infrastructure-free scenes. In this study, we analyze the relative 6-DOF pose estimation error of multi-robot system in GNSS-denied and anchor-free environment. An analytical lower bound of position and orientation estimation error is given under the assumption that distance between the nodes are far more than the size of robotic platform. Through simulation, impact of distance between nodes, altitudes and circumradius of tag simplex on pose estimation accuracy is discussed, which verifies the analysis results. Our analysis is expected to determine parameters (e.g. deployment of tags) of UWB based multi-robot systems.