 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Consistency-Improved LiDAR-Inertial Bundle Adjustment
Feb 06, 2026Simultaneous Localization and Mapping (SLAM) using 3D LiDAR has emerged as a cornerstone for autonomous navigation in robotics. While feature-based SLAM systems have achieved impressive results by leveraging edge and planar structures, they often suffer from the inconsistent estimator associated with feature parameterization and estimated covariance. In this work, we present a consistency-improved LiDAR-inertial bundle adjustment (BA) with tailored parameterization and estimator. First, we propose a stereographic-projection representation parameterizing the planar and edge features, and conduct a comprehensive observability analysis to support its integrability with consistent estimator. Second, we implement a LiDAR-inertial BA with Maximum a Posteriori (MAP) formulation and First-Estimate Jacobians (FEJ) to preserve the accurate estimated covariance and observability properties of the system. Last, we apply our proposed BA method to a LiDAR-inertial odometry.
Analysis on Multi-robot Relative 6-DOF Pose Estimation Error Based on UWB Range
Sep 27, 2023



Relative pose estimation is the foundational requirement for multi-robot system, while it is a challenging research topic in infrastructure-free scenes. In this study, we analyze the relative 6-DOF pose estimation error of multi-robot system in GNSS-denied and anchor-free environment. An analytical lower bound of position and orientation estimation error is given under the assumption that distance between the nodes are far more than the size of robotic platform. Through simulation, impact of distance between nodes, altitudes and circumradius of tag simplex on pose estimation accuracy is discussed, which verifies the analysis results. Our analysis is expected to determine parameters (e.g. deployment of tags) of UWB based multi-robot systems.
Relational Learning for Joint Head and Human Detection
Sep 24, 2019

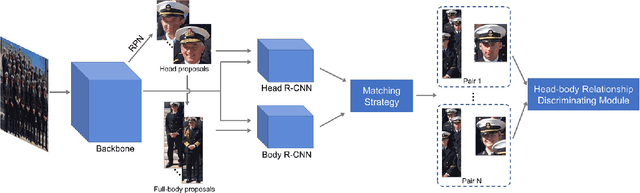
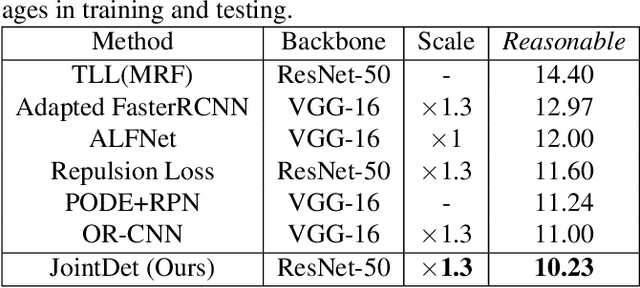
Head and human detection have been rapidly improved with the development of deep convolutional neural networks. However, these two tasks are often studied separately without considering their inherent correlation, leading to that 1) head detection is often trapped in more false positives, and 2) the performance of human detector frequently drops dramatically in crowd scenes. To handle these two issues, we present a novel joint head and human detection network, namely JointDet, which effectively detects head and human body simultaneously. Moreover, we design a head-body relationship discriminating module to perform relational learning between heads and human bodies, and leverage this learned relationship to regain the suppressed human detections and reduce head false positives. To verify the effectiveness of the proposed method, we annotate head bounding boxes of the CityPersons and Caltech-USA datasets, and conduct extensive experiments on the CrowdHuman, CityPersons and Caltech-USA datasets. As a consequence, the proposed JointDet detector achieves state-of-the-art performance on these three benchmarks. To facilitate further studies on the head and human detection problem, all new annotations, source codes and trained models will be public.
PedHunter: Occlusion Robust Pedestrian Detector in Crowded Scenes
Sep 15, 2019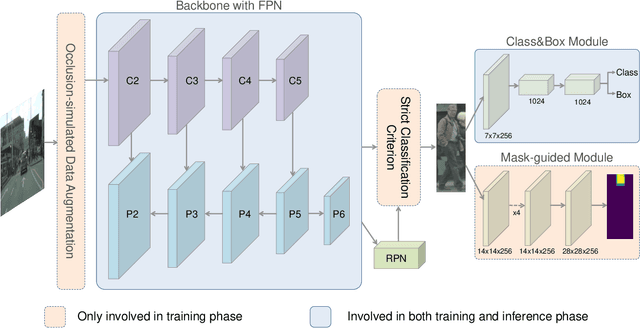


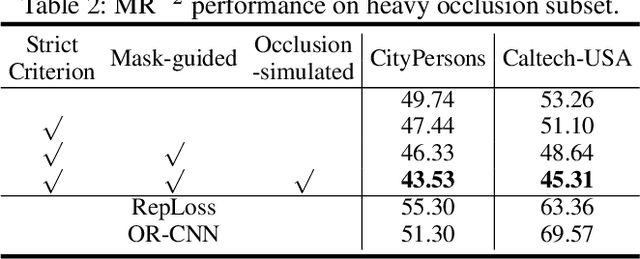
Pedestrian detection in crowded scenes is a challenging problem, because occlusion happens frequently among different pedestrians. In this paper, we propose an effective and efficient detection network to hunt pedestrians in crowd scenes. The proposed method, namely PedHunter, introduces strong occlusion handling ability to existing region-based detection networks without bringing extra computations in the inference stage. Specifically, we design a mask-guided module to leverage the head information to enhance the feature representation learning of the backbone network. Moreover, we develop a strict classification criterion by improving the quality of positive samples during training to eliminate common false positives of pedestrian detection in crowded scenes. Besides, we present an occlusion-simulated data augmentation to enrich the pattern and quantity of occlusion samples to improve the occlusion robustness. As a consequent, we achieve state-of-the-art results on three pedestrian detection datasets including CityPersons, Caltech-USA and CrowdHuman. To facilitate further studies on the occluded pedestrian detection in surveillance scenes, we release a new pedestrian dataset, called SUR-PED, with a total of over 162k high-quality manually labeled instances in 10k images. The proposed dataset, source codes and trained models will be released.
Selective Refinement Network for High Performance Face Detection
Sep 07, 2018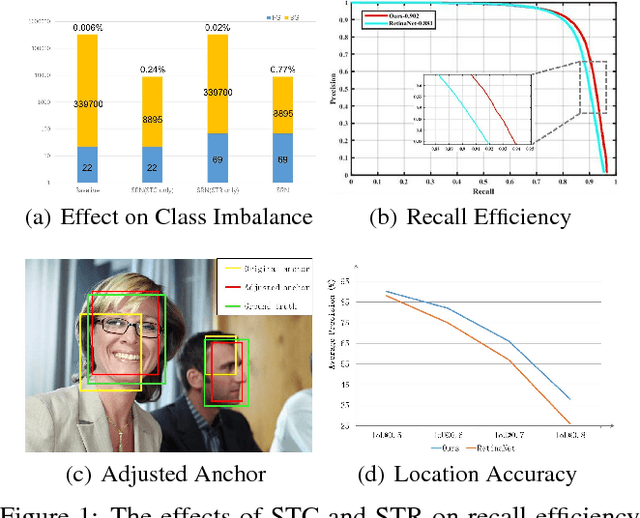
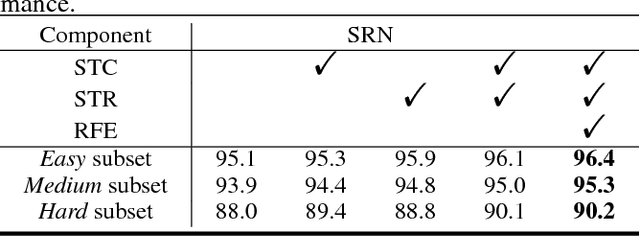
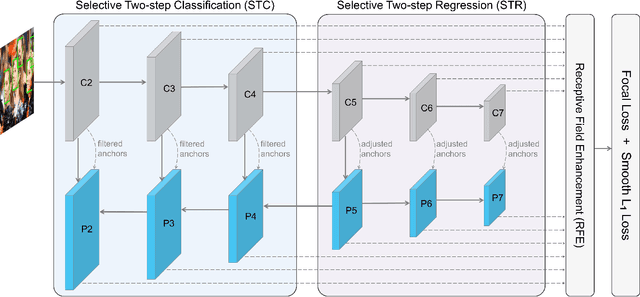

High performance face detection remains a very challenging problem, especially when there exists many tiny faces. This paper presents a novel single-shot face detector, named Selective Refinement Network (SRN), which introduces novel two-step classification and regression operations selectively into an anchor-based face detector to reduce false positives and improve location accuracy simultaneously. In particular, the SRN consists of two modules: the Selective Two-step Classification (STC) module and the Selective Two-step Regression (STR) module. The STC aims to filter out most simple negative anchors from low level detection layers to reduce the search space for the subsequent classifier, while the STR is designed to coarsely adjust the locations and sizes of anchors from high level detection layers to provide better initialization for the subsequent regressor. Moreover, we design a Receptive Field Enhancement (RFE) block to provide more diverse receptive field, which helps to better capture faces in some extreme poses. As a consequence, the proposed SRN detector achieves state-of-the-art performance on all the widely used face detection benchmarks, including AFW, PASCAL face, FDDB, and WIDER FACE datasets. Codes will be released to facilitate further studies on the face detection problem.