 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Exploration and Sequential Manipulation on Scene Graph with LLM-based Situated Replanning
Feb 04, 2026In partially known environments, robots must combine exploration to gather information with task planning for efficient execution. To address this challenge, we propose EPoG, an Exploration-based sequential manipulation Planning framework on Scene Graphs. EPoG integrates a graph-based global planner with a Large Language Model (LLM)-based situated local planner, continuously updating a belief graph using observations and LLM predictions to represent known and unknown objects. Action sequences are generated by computing graph edit operations between the goal and belief graphs, ordered by temporal dependencies and movement costs. This approach seamlessly combines exploration and sequential manipulation planning. In ablation studies across 46 realistic household scenes and 5 long-horizon daily object transportation tasks, EPoG achieved a success rate of 91.3%, reducing travel distance by 36.1% on average. Furthermore, a physical mobile manipulator successfully executed complex tasks in unknown and dynamic environments, demonstrating EPoG's potential for real-world applications.
TaF-VLA: Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation
Jan 30, 2026Vision-Language-Action (VLA) models have recently emerged as powerful generalists for robotic manipulation. However, due to their predominant reliance on visual modalities, they fundamentally lack the physical intuition required for contact-rich tasks that require precise force regulation and physical reasoning. Existing attempts to incorporate vision-based tactile sensing into VLA models typically treat tactile inputs as auxiliary visual textures, thereby overlooking the underlying correlation between surface deformation and interaction dynamics. To bridge this gap, we propose a paradigm shift from tactile-vision alignment to tactile-force alignment. Here, we introduce TaF-VLA, a framework that explicitly grounds high-dimensional tactile observations in physical interaction forces. To facilitate this, we develop an automated tactile-force data acquisition device and curate the TaF-Dataset, comprising over 10 million synchronized tactile observations, 6-axis force/torque, and matrix force map. To align sequential tactile observations with interaction forces, the central component of our approach is the Tactile-Force Adapter (TaF-Adapter), a tactile sensor encoder that extracts discretized latent information for encoding tactile observations. This mechanism ensures that the learned representations capture history-dependent, noise-insensitive physical dynamics rather than static visual textures. Finally, we integrate this force-aligned encoder into a VLA backbone. Extensive real-world experiments demonstrate that TaF-VLA policy significantly outperforms state-of-the-art tactile-vision-aligned and vision-only baselines on contact-rich tasks, verifying its ability to achieve robust, force-aware manipulation through cross-modal physical reasoning.
Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation
Jan 28, 2026Vision-Language-Action (VLA) models have recently emerged as powerful generalists for robotic manipulation. However, due to their predominant reliance on visual modalities, they fundamentally lack the physical intuition required for contact-rich tasks that require precise force regulation and physical reasoning. Existing attempts to incorporate vision-based tactile sensing into VLA models typically treat tactile inputs as auxiliary visual textures, thereby overlooking the underlying correlation between surface deformation and interaction dynamics. To bridge this gap, we propose a paradigm shift from tactile-vision alignment to tactile-force alignment. Here, we introduce TaF-VLA, a framework that explicitly grounds high-dimensional tactile observations in physical interaction forces. To facilitate this, we develop an automated tactile-force data acquisition device and curate the TaF-Dataset, comprising over 10 million synchronized tactile observations, 6-axis force/torque, and matrix force map. To align sequential tactile observations with interaction forces, the central component of our approach is the Tactile-Force Adapter (TaF-Adapter), a tactile sensor encoder that extracts discretized latent information for encoding tactile observations. This mechanism ensures that the learned representations capture history-dependent, noise-insensitive physical dynamics rather than static visual textures. Finally, we integrate this force-aligned encoder into a VLA backbone. Extensive real-world experiments demonstrate that TaF-VLA policy significantly outperforms state-of-the-art tactile-vision-aligned and vision-only baselines on contact-rich tasks, verifying its ability to achieve robust, force-aware manipulation through cross-modal physical reasoning.
In-situ Value-aligned Human-Robot Interactions with Physical Constraints
Aug 11, 2025Equipped with Large Language Models (LLMs), human-centered robots are now capable of performing a wide range of tasks that were previously deemed challenging or unattainable. However, merely completing tasks is insufficient for cognitive robots, who should learn and apply human preferences to future scenarios. In this work, we propose a framework that combines human preferences with physical constraints, requiring robots to complete tasks while considering both. Firstly, we developed a benchmark of everyday household activities, which are often evaluated based on specific preferences. We then introduced In-Context Learning from Human Feedback (ICLHF), where human feedback comes from direct instructions and adjustments made intentionally or unintentionally in daily life. Extensive sets of experiments, testing the ICLHF to generate task plans and balance physical constraints with preferences, have demonstrated the efficiency of our approach.
IKDiffuser: Fast and Diverse Inverse Kinematics Solution Generation for Multi-arm Robotic Systems
Jun 16, 2025Solving Inverse Kinematics (IK) problems is fundamental to robotics, but has primarily been successful with single serial manipulators. For multi-arm robotic systems, IK remains challenging due to complex self-collisions, coupled joints, and high-dimensional redundancy. These complexities make traditional IK solvers slow, prone to failure, and lacking in solution diversity. In this paper, we present IKDiffuser, a diffusion-based model designed for fast and diverse IK solution generation for multi-arm robotic systems. IKDiffuser learns the joint distribution over the configuration space, capturing complex dependencies and enabling seamless generalization to multi-arm robotic systems of different structures. In addition, IKDiffuser can incorporate additional objectives during inference without retraining, offering versatility and adaptability for task-specific requirements. In experiments on 6 different multi-arm systems, the proposed IKDiffuser achieves superior solution accuracy, precision, diversity, and computational efficiency compared to existing solvers. The proposed IKDiffuser framework offers a scalable, unified approach to solving multi-arm IK problems, facilitating the potential of multi-arm robotic systems in real-time manipulation tasks.
PP-Tac: Paper Picking Using Tactile Feedback in Dexterous Robotic Hands
Apr 23, 2025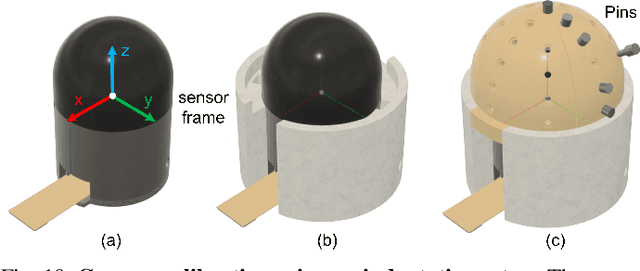
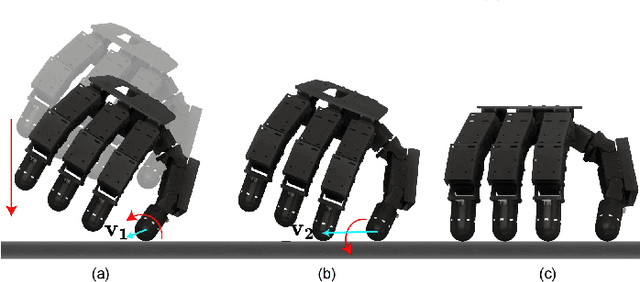
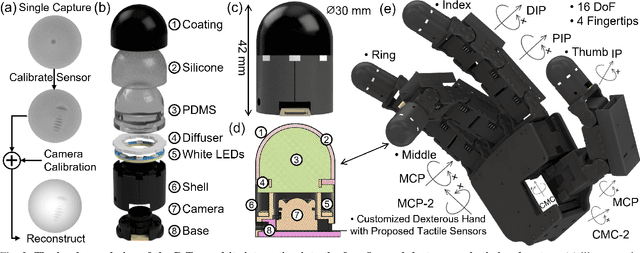
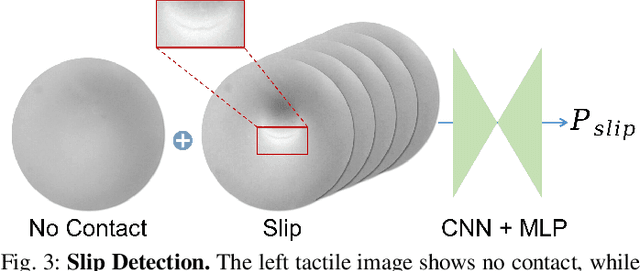
Robots are increasingly envisioned as human companions, assisting with everyday tasks that often involve manipulating deformable objects. Although recent advances in robotic hardware and embodied AI have expanded their capabilities, current systems still struggle with handling thin, flat, and deformable objects such as paper and fabric. This limitation arises from the lack of suitable perception techniques for robust state estimation under diverse object appearances, as well as the absence of planning techniques for generating appropriate grasp motions. To bridge these gaps, this paper introduces PP-Tac, a robotic system for picking up paper-like objects. PP-Tac features a multi-fingered robotic hand with high-resolution omnidirectional tactile sensors \sensorname. This hardware configuration enables real-time slip detection and online frictional force control that mitigates such slips. Furthermore, grasp motion generation is achieved through a trajectory synthesis pipeline, which first constructs a dataset of finger's pinching motions. Based on this dataset, a diffusion-based policy is trained to control the hand-arm robotic system. Experiments demonstrate that PP-Tac can effectively grasp paper-like objects of varying material, thickness, and stiffness, achieving an overall success rate of 87.5\%. To our knowledge, this work is the first attempt to grasp paper-like deformable objects using a tactile dexterous hand. Our project webpage can be found at: https://peilin-666.github.io/projects/PP-Tac/
Flight Structure Optimization of Modular Reconfigurable UAVs
Jul 04, 2024



This paper presents a Genetic Algorithm (GA) designed to reconfigure a large group of modular Unmanned Aerial Vehicles (UAVs), each with different weights and inertia parameters, into an over-actuated flight structure with improved dynamic properties. Previous research efforts either utilized expert knowledge to design flight structures for a specific task or relied on enumeration-based algorithms that required extensive computation to find an optimal one. However, both approaches encounter challenges in accommodating the heterogeneity among modules. Our GA addresses these challenges by incorporating the complexities of over-actuation and dynamic properties into its formulation. Additionally, we employ a tree representation and a vector representation to describe flight structures, facilitating efficient crossover operations and fitness evaluations within the GA framework, respectively. Using cubic modular quadcopters capable of functioning as omni-directional thrust generators, we validate that the proposed approach can (i) adeptly identify suboptimal configurations ensuring over-actuation while ensuring trajectory tracking accuracy and (ii) significantly reduce computational costs compared to traditional enumeration-based methods.
Dynamic Planning for Sequential Whole-body Mobile Manipulation
May 24, 2024
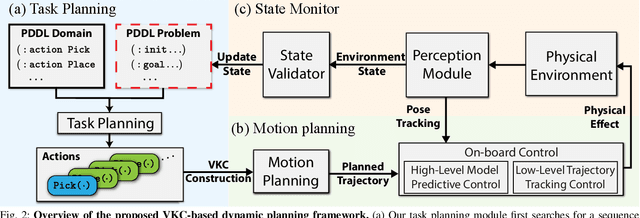
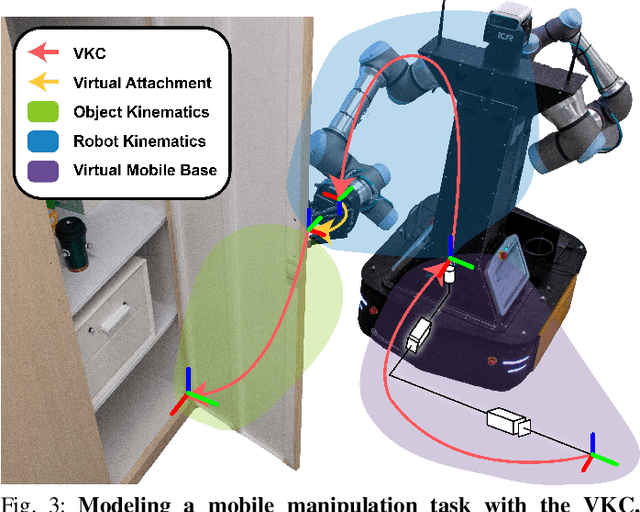
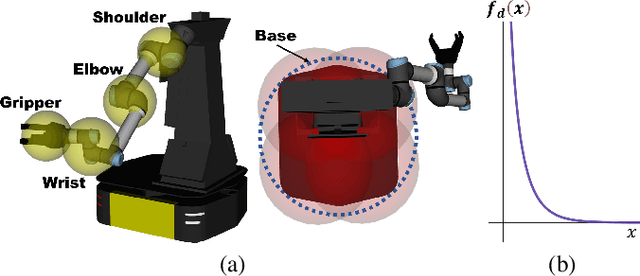
The dynamic Sequential Mobile Manipulation Planning (SMMP) framework is essential for the safe and robust operation of mobile manipulators in dynamic environments. Previous research has primarily focused on either motion-level or task-level dynamic planning, with limitations in handling state changes that have long-term effects or in generating responsive motions for diverse tasks, respectively. This paper presents a holistic dynamic planning framework that extends the Virtual Kinematic Chain (VKC)-based SMMP method, automating dynamic long-term task planning and reactive whole-body motion generation for SMMP problems. The framework consists of an online task planning module designed to respond to environment changes with long-term effects, a VKC-based whole-body motion planning module for manipulating both rigid and articulated objects, alongside a reactive Model Predictive Control (MPC) module for obstacle avoidance during execution. Simulations and real-world experiments validate the framework, demonstrating its efficacy and validity across sequential mobile manipulation tasks, even in scenarios involving human interference.
Closed-Loop Open-Vocabulary Mobile Manipulation with GPT-4V
Apr 16, 2024



Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. We present COME-robot, the first closed-loop framework utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. We meticulously construct a library of action primitives for robot exploration, navigation, and manipulation, serving as callable execution modules for GPT-4V in task planning. On top of these modules, GPT-4V serves as the brain that can accomplish multimodal reasoning, generate action policy with code, verify the task progress, and provide feedback for replanning. Such design enables COME-robot to (i) actively perceive the environments, (ii) perform situated reasoning, and (iii) recover from failures. Through comprehensive experiments involving 8 challenging real-world tabletop and manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~25%) compared to state-of-the-art baseline methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.
LLM3:Large Language Model-based Task and Motion Planning with Motion Failure Reasoning
Mar 20, 2024



Conventional Task and Motion Planning (TAMP) approaches rely on manually crafted interfaces connecting symbolic task planning with continuous motion generation. These domain-specific and labor-intensive modules are limited in addressing emerging tasks in real-world settings. Here, we present LLM^3, a novel Large Language Model (LLM)-based TAMP framework featuring a domain-independent interface. Specifically, we leverage the powerful reasoning and planning capabilities of pre-trained LLMs to propose symbolic action sequences and select continuous action parameters for motion planning. Crucially, LLM^3 incorporates motion planning feedback through prompting, allowing the LLM to iteratively refine its proposals by reasoning about motion failure. Consequently, LLM^3 interfaces between task planning and motion planning, alleviating the intricate design process of handling domain-specific messages between them. Through a series of simulations in a box-packing domain, we quantitatively demonstrate the effectiveness of LLM^3 in solving TAMP problems and the efficiency in selecting action parameters. Ablation studies underscore the significant contribution of motion failure reasoning to the success of LLM^3. Furthermore, we conduct qualitative experiments on a physical manipulator, demonstrating the practical applicability of our approach in real-world settings.