 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingua-SafetyBench: A Benchmark for Safety Evaluation of Multilingual Vision-Language Models
Jan 30, 2026Robust safety of vision-language large models (VLLMs) under joint multilingual and multimodal inputs remains underexplored. Existing benchmarks are typically multilingual but text-only, or multimodal but monolingual. Recent multilingual multimodal red-teaming efforts render harmful prompts into images, yet rely heavily on typography-style visuals and lack semantically grounded image-text pairs, limiting coverage of realistic cross-modal interactions. We introduce Lingua-SafetyBench, a benchmark of 100,440 harmful image-text pairs across 10 languages, explicitly partitioned into image-dominant and text-dominant subsets to disentangle risk sources. Evaluating 11 open-source VLLMs reveals a consistent asymmetry: image-dominant risks yield higher ASR in high-resource languages, while text-dominant risks are more severe in non-high-resource languages. A controlled study on the Qwen series shows that scaling and version upgrades reduce Attack Success Rate (ASR) overall but disproportionately benefit HRLs, widening the gap between HRLs and Non-HRLs under text-dominant risks. This underscores the necessity of language- and modality-aware safety alignment beyond mere scaling.To facilitate reproducibility and future research, we will publicly release our benchmark, model checkpoints, and source code.The code and dataset will be available at https://github.com/zsxr15/Lingua-SafetyBench.Warning: this paper contains examples with unsafe content.
FemtoDet: An Object Detection Baseline for Energy Versus Performance Tradeoffs
Jan 17, 2023Efficient detectors for edge devices are often optimized for metrics like parameters or speed counts, which remain weak correlation with the energy of detectors. However, among vision applications of convolutional neural networks (CNNs), some, such as always-on surveillance cameras, are critical for energy constraints. This paper aims to serve as a baseline by designing detectors to reach tradeoffs between energy and performance from two perspectives: 1) We extensively analyze various CNNs to identify low-energy architectures, including the selection of activation functions, convolutions operators, and feature fusion structures on necks. These underappreciated details in past works seriously affect the energy consumption of detectors; 2) To break through the dilemmatic energy-performance problem, we propose a balanced detector driven by energy using discovered low-energy components named \textit{FemtoDet}. In addition to the novel construction, we further improve FemtoDet by considering convolutions and training strategy optimizations. Specifically, we develop a new instance boundary enhancement (IBE) module for convolution optimization to overcome the contradiction between the limited capacity of CNNs and detection tasks in diverse spatial representations, and propose a recursive warm-restart (RecWR) for optimizing training strategy to escape the sub-optimization of light-weight detectors, considering the data shift produced in popular augmentations. As a result, FemtoDet with only 68.77k parameters achieves a competitive score of 46.3 AP50 on PASCAL VOC and power of 7.83W on RTX 3090. Extensive experiments on COCO and TJU-DHD datasets indicate that the proposed method achieves competitive results in diverse scenes.
CausCF: Causal Collaborative Filtering for RecommendationEffect Estimation
May 28, 2021


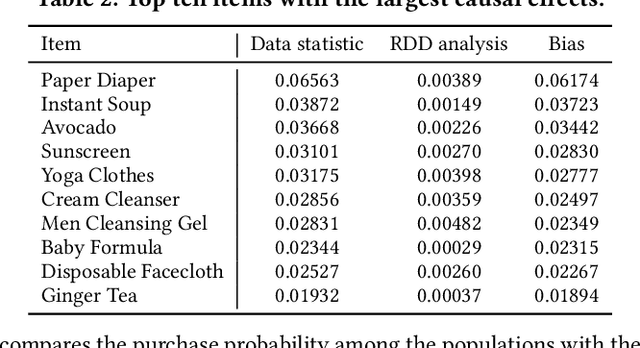
To improve user experience and profits of corporations, modern industrial recommender systems usually aim to select the items that are most likely to be interacted with (e.g., clicks and purchases). However, they overlook the fact that users may purchase the items even without recommendations. To select these effective items, it is essential to estimate the causal effect of recommendations. The real effective items are the ones which can contribute to purchase probability uplift. Nevertheless, it is difficult to obtain the real causal effect since we can only recommend or not recommend an item to a user at one time. Furthermore, previous works usually rely on the randomized controlled trial~(RCT) experiment to evaluate their performance. However, it is usually not practicable in the recommendation scenario due to its unavailable time consuming. To tackle these problems, in this paper, we propose a causal collaborative filtering~(CausCF) method inspired by the widely adopted collaborative filtering~(CF) technique. It is based on the idea that similar users not only have a similar taste on items, but also have similar treatment effect under recommendations. CausCF extends the classical matrix factorization to the tensor factorization with three dimensions -- user, item, and treatment. Furthermore, we also employs regression discontinuity design (RDD) to evaluate the precision of the estimated causal effects from different models. With the testable assumptions, RDD analysis can provide an unbiased causal conclusion without RCT experiments. Through dedicated experiments on both the public datasets and the industrial application, we demonstrate the effectiveness of our proposed CausCF on the causal effect estimation and ranking performance improvement.
Trajectory Prediction with Latent Belief Energy-Based Model
Apr 07, 2021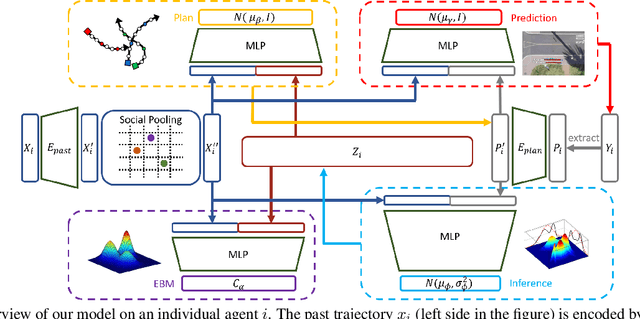
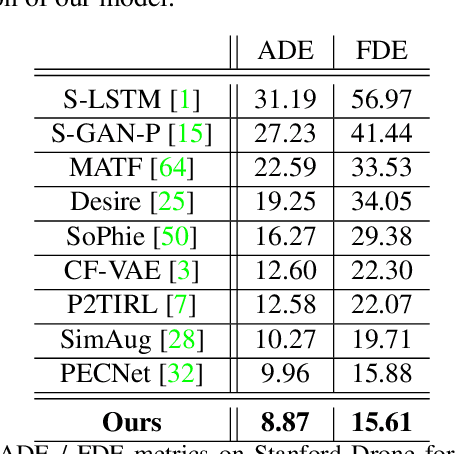

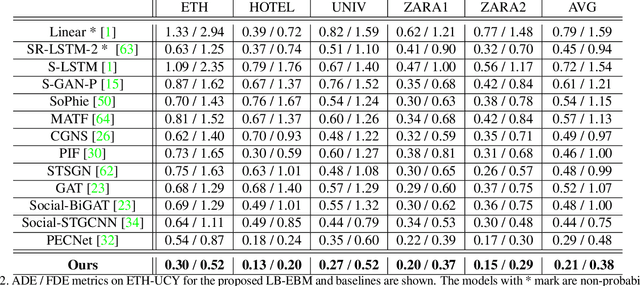
Human trajectory prediction is critical for autonomous platforms like self-driving cars or social robots. We present a latent belief energy-based model (LB-EBM) for diverse human trajectory forecast. LB-EBM is a probabilistic model with cost function defined in the latent space to account for the movement history and social context. The low-dimensionality of the latent space and the high expressivity of the EBM make it easy for the model to capture the multimodality of pedestrian trajectory distributions. LB-EBM is learned from expert demonstrations (i.e., human trajectories) projected into the latent space. Sampling from or optimizing the learned LB-EBM yields a belief vector which is used to make a path plan, which then in turn helps to predict a long-range trajectory. The effectiveness of LB-EBM and the two-step approach are supported by strong empirical results. Our model is able to make accurate, multi-modal, and social compliant trajectory predictions and improves over prior state-of-the-arts performance on the Stanford Drone trajectory prediction benchmark by 10.9% and on the ETH-UCY benchmark by 27.6%.
Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments
Mar 30, 2021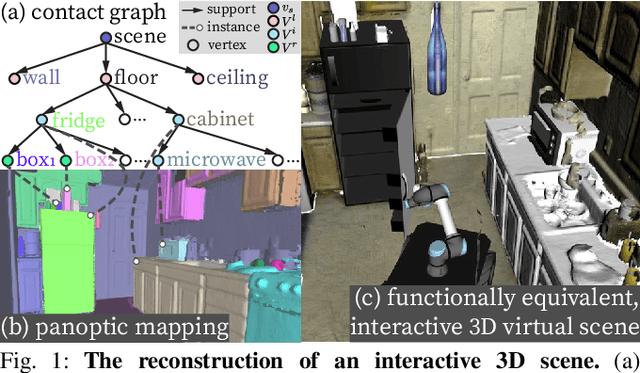
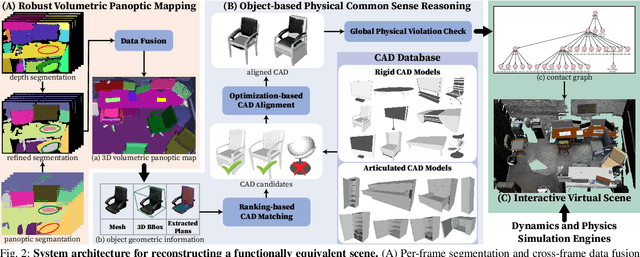
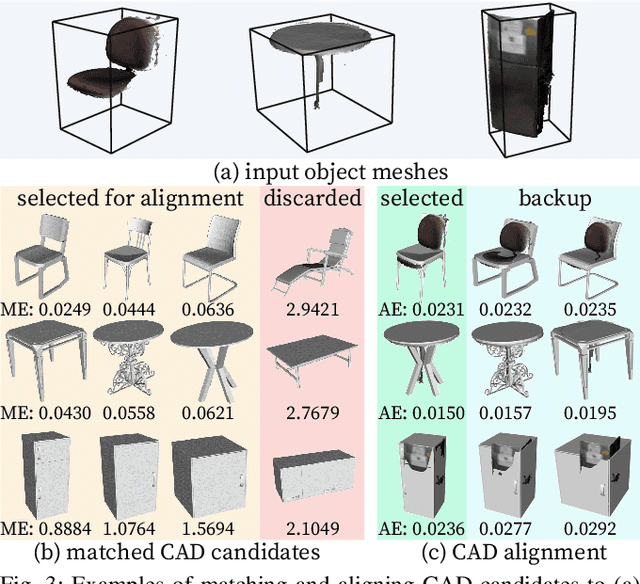
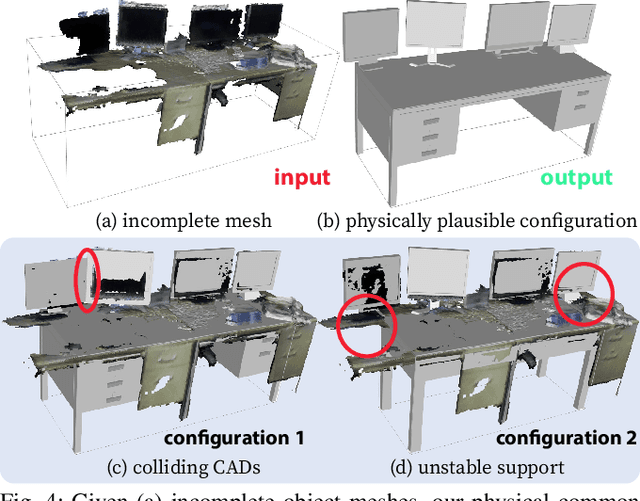
In this paper, we rethink the problem of scene reconstruction from an embodied agent's perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints such that the reconstructed scenes provide \em{actionable} information for simulating \em{interactions} with agents. Here, we address this challenging problem by reconstructing an interactive scene using RGB-D data stream, which captures (i) the semantics and geometry of objects and layouts by a 3D volumetric panoptic mapping module, and (ii) object affordance and contextual relations by reasoning over physical common sense among objects, organized by a graph-based scene representation. Crucially, this reconstructed scene replaces the object meshes in the dense panoptic map with part-based articulated CAD models for finer-grained robot interactions. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods, (ii) a high-performant physical reasoning procedure that matches, aligns, and replaces objects' meshes with best-fitted CAD models, and (iii) reconstructed scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based simulators and virtual environments for complex robot task executions.
Congestion-aware Multi-agent Trajectory Prediction for Collision Avoidance
Mar 26, 2021

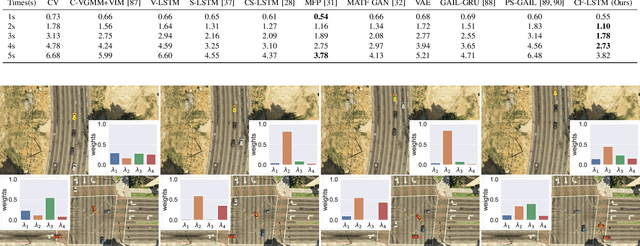

Predicting agents' future trajectories plays a crucial role in modern AI systems, yet it is challenging due to intricate interactions exhibited in multi-agent systems, especially when it comes to collision avoidance. To address this challenge, we propose to learn congestion patterns as contextual cues explicitly and devise a novel "Sense--Learn--Reason--Predict" framework by exploiting advantages of three different doctrines of thought, which yields the following desirable benefits: (i) Representing congestion as contextual cues via latent factors subsumes the concept of social force commonly used in physics-based approaches and implicitly encodes the distance as a cost, similar to the way a planning-based method models the environment. (ii) By decomposing the learning phases into two stages, a "student" can learn contextual cues from a "teacher" while generating collision-free trajectories. To make the framework computationally tractable, we formulate it as an optimization problem and derive an upper bound by leveraging the variational parametrization. In experiments, we demonstrate that the proposed model is able to generate collision-free trajectory predictions in a synthetic dataset designed for collision avoidance evaluation and remains competitive on the commonly used NGSIM US-101 highway dataset.
Explore User Neighborhood for Real-time E-commerce Recommendation
Feb 28, 2021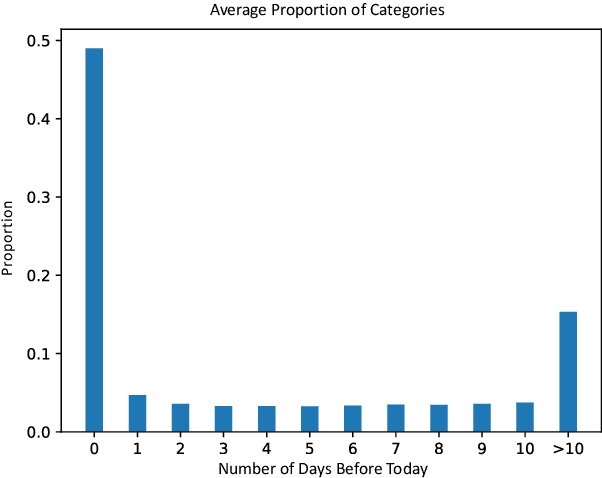
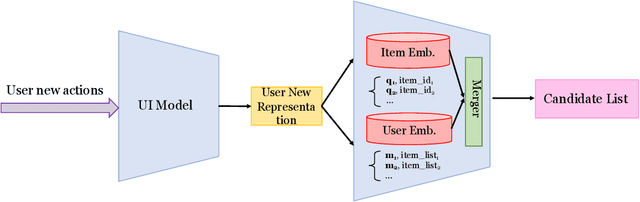
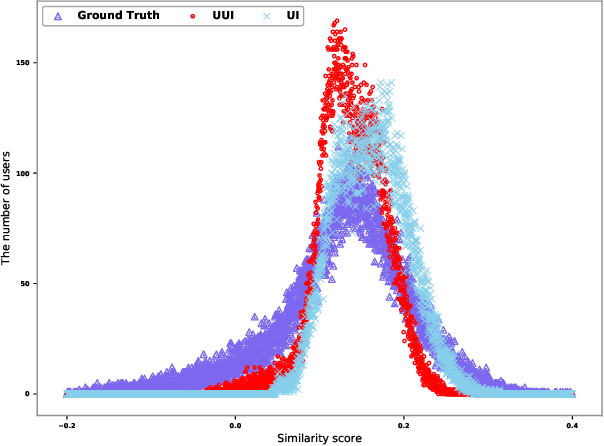
Recommender systems play a vital role in modern online services, such as Amazon and Taobao. Traditional personalized methods, which focus on user-item (UI) relations, have been widely applied in industrial settings, owing to their efficiency and effectiveness. Despite their success, we argue that these approaches ignore local information hidden in similar users. To tackle this problem, user-based methods exploit similar user relations to make recommendations in a local perspective. Nevertheless, traditional user-based methods, like userKNN and matrix factorization, are intractable to be deployed in the real-time applications since such transductive models have to be recomputed or retrained with any new interaction. To overcome this challenge, we propose a framework called self-complementary collaborative filtering~(SCCF) which can make recommendations with both global and local information in real time. On the one hand, it utilizes UI relations and user neighborhood to capture both global and local information. On the other hand, it can identify similar users for each user in real time by inferring user representations on the fly with an inductive model. The proposed framework can be seamlessly incorporated into existing inductive UI approach and benefit from user neighborhood with little additional computation. It is also the first attempt to apply user-based methods in real-time settings. The effectiveness and efficiency of SCCF are demonstrated through extensive offline experiments on four public datasets, as well as a large scale online A/B test in Taobao.
VRGym: A Virtual Testbed for Physical and Interactive AI
Apr 02, 2019



We propose VRGym, a virtual reality testbed for realistic human-robot interaction. Different from existing toolkits and virtual reality environments, the VRGym emphasizes on building and training both physical and interactive agents for robotics, machine learning, and cognitive science. VRGym leverages mechanisms that can generate diverse 3D scenes with high realism through physics-based simulation. We demonstrate that VRGym is able to (i) collect human interactions and fine manipulations, (ii) accommodate various robots with a ROS bridge, (iii) support experiments for human-robot interaction, and (iv) provide toolkits for training the state-of-the-art machine learning algorithms. We hope VRGym can help to advance general-purpose robotics and machine learning agents, as well as assisting human studies in the field of cognitive science.
VRKitchen: an Interactive 3D Virtual Environment for Task-oriented Learning
Mar 13, 2019
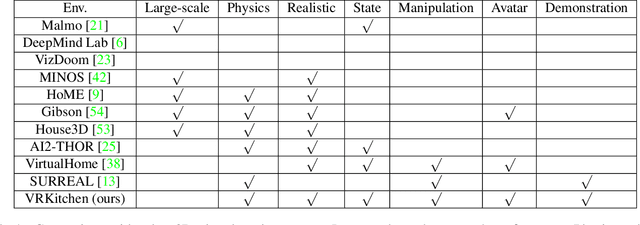
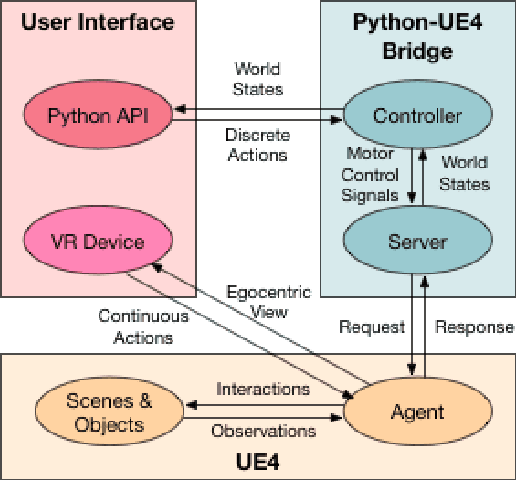
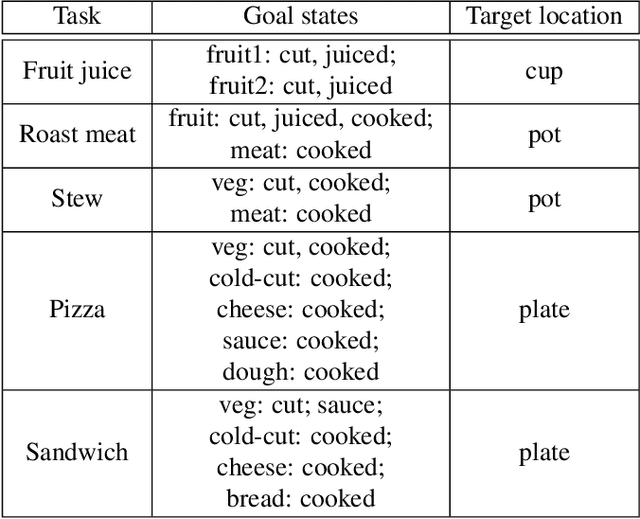
One of the main challenges of advancing task-oriented learning such as visual task planning and reinforcement learning is the lack of realistic and standardized environments for training and testing AI agents. Previously, researchers often relied on ad-hoc lab environments. There have been recent advances in virtual systems built with 3D physics engines and photo-realistic rendering for indoor and outdoor environments, but the embodied agents in those systems can only conduct simple interactions with the world (e.g., walking around, moving objects, etc.). Most of the existing systems also do not allow human participation in their simulated environments. In this work, we design and implement a virtual reality (VR) system, VRKitchen, with integrated functions which i) enable embodied agents powered by modern AI methods (e.g., planning, reinforcement learning, etc.) to perform complex tasks involving a wide range of fine-grained object manipulations in a realistic environment, and ii) allow human teachers to perform demonstrations to train agents (i.e., learning from demonstration). We also provide standardized evaluation benchmarks and data collection tools to facilitate a broad use in research on task-oriented learning and beyond.